 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Space Perturbation: A Panacea to Enhanced Transferability Estimation
Paper and Code
Feb 23, 2025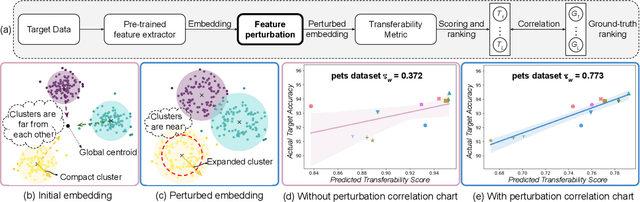
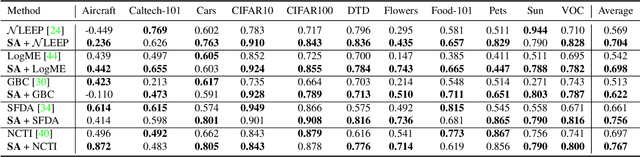

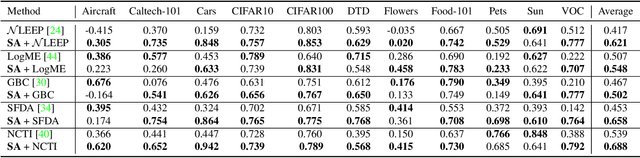
Leveraging a transferability estimation metric facilitates the non-trivial challenge of selecting the optimal model for the downstream task from a pool of pre-trained models. Most existing metrics primarily focus on identifying the statistical relationship between feature embeddings and the corresponding labels within the target dataset, but overlook crucial aspect of model robustness. This oversight may limit their effectiveness in accurately ranking pre-trained models. To address this limitation, we introduce a feature perturbation method that enhances the transferability estimation process by systematically altering the feature space. Our method includes a Spread operation that increases intra-class variability, adding complexity within classes, and an Attract operation that minimizes the distances between different classes, thereby blurring the class boundaries. Through extensive experimentation, we demonstrate the efficacy of our feature perturbation method in providing a more precise and robust estimation of model transferability. Notably, the existing LogMe method exhibited a significant improvement, showing a 28.84% increase in performance after applying our feature perturbation method.