 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Screenshot Retrievers are Vulnerable to Pixel Poisoning Attacks
Jan 28, 2025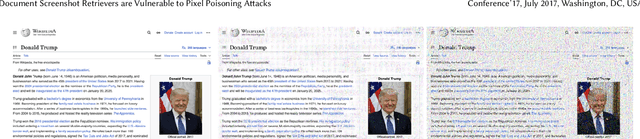
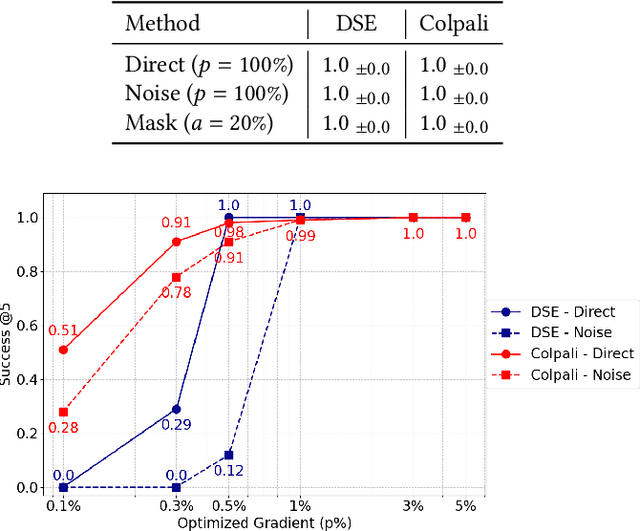

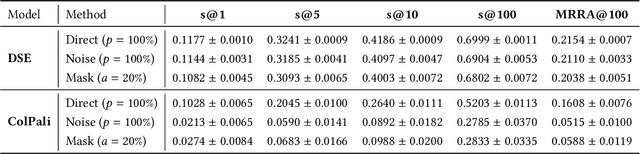
Recent advancements in dense retrieval have introduced vision-language model (VLM)-based retrievers, such as DSE and ColPali, which leverage document screenshots embedded as vectors to enable effective search and offer a simplified pipeline over traditional text-only methods. In this study, we propose three pixel poisoning attack methods designed to compromise VLM-based retrievers and evaluate their effectiveness under various attack settings and parameter configurations. Our empirical results demonstrate that injecting even a single adversarial screenshot into the retrieval corpus can significantly disrupt search results, poisoning the top-10 retrieved documents for 41.9% of queries in the case of DSE and 26.4% for ColPali. These vulnerability rates notably exceed those observed with equivalent attacks on text-only retrievers. Moreover, when targeting a small set of known queries, the attack success rate raises, achieving complete success in certain cases. By exposing the vulnerabilities inherent in vision-language models, this work highlights the potential risks associated with their deployment.
Source-Free Domain-Invariant Performance Prediction
Aug 06, 2024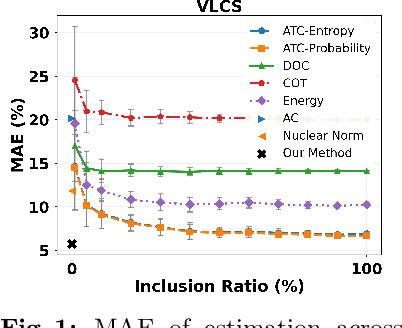

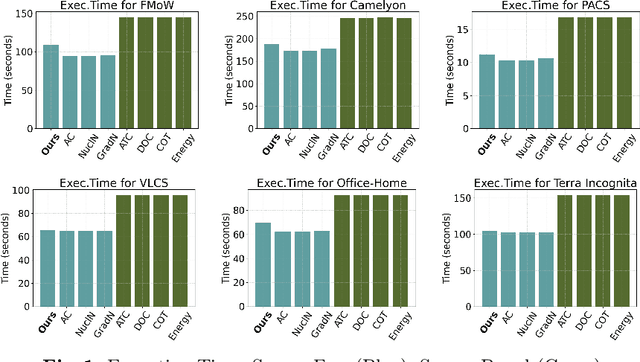
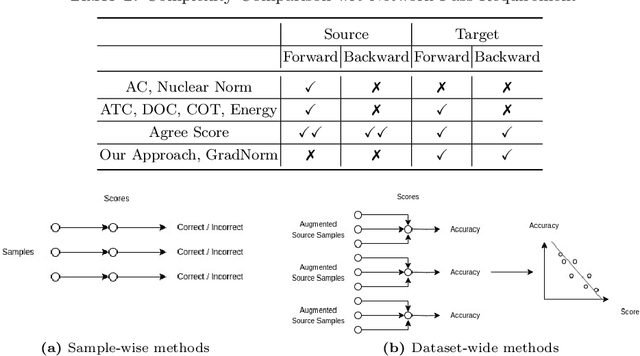
Accurately estimating model performance poses a significant challenge, particularly in scenarios where the source and target domains follow different data distributions. Most existing performance prediction methods heavily rely on the source data in their estimation process, limiting their applicability in a more realistic setting where only the trained model is accessible. The few methods that do not require source data exhibit considerably inferior performance. In this work, we propose a source-free approach centred on uncertainty-based estimation, using a generative model for calibration in the absence of source data. We establish connections between our approach for unsupervised calibration and temperature scaling. We then employ a gradient-based strategy to evaluate the correctness of the calibrated predictions. Our experiments on benchmark object recognition datasets reveal that existing source-based methods fall short with limited source sample availability. Furthermore, our approach significantly outperforms the current state-of-the-art source-free and source-based methods, affirming its effectiveness in domain-invariant performance estimation.
Embark on DenseQuest: A System for Selecting the Best Dense Retriever for a Custom Collection
Jul 09, 2024


In this demo we present a web-based application for selecting an effective pre-trained dense retriever to use on a private collection. Our system, DenseQuest, provides unsupervised selection and ranking capabilities to predict the best dense retriever among a pool of available dense retrievers, tailored to an uploaded target collection. DenseQuest implements a number of existing approaches, including a recent, highly effective method powered by Large Language Models (LLMs), which requires neither queries nor relevance judgments. The system is designed to be intuitive and easy to use for those information retrieval engineers and researchers who need to identify a general-purpose dense retrieval model to encode or search a new private target collection. Our demonstration illustrates conceptual architecture and the different use case scenarios of the system implemented on the cloud, enabling universal access and use. DenseQuest is available at https://densequest.ielab.io.
FeB4RAG: Evaluating Federated Search in the Context of Retrieval Augmented Generation
Feb 19, 2024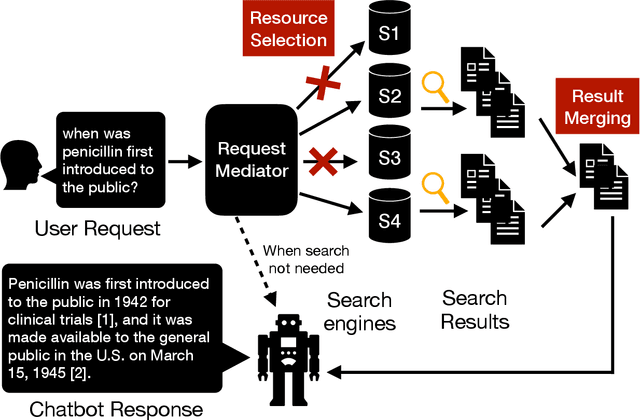
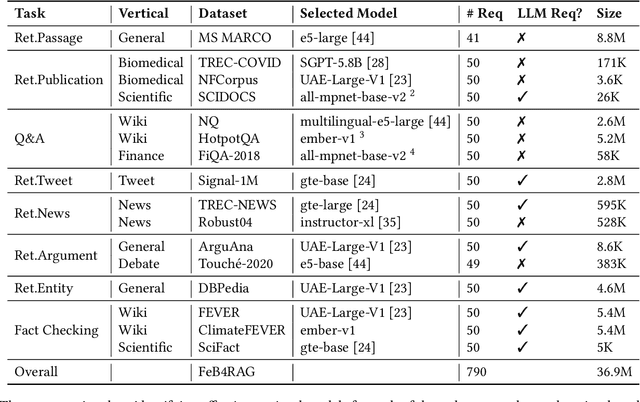


Federated search systems aggregate results from multiple search engines, selecting appropriate sources to enhance result quality and align with user intent. With the increasing uptake of Retrieval-Augmented Generation (RAG) pipelines, federated search can play a pivotal role in sourcing relevant information across heterogeneous data sources to generate informed responses. However, existing datasets, such as those developed in the past TREC FedWeb tracks, predate the RAG paradigm shift and lack representation of modern information retrieval challenges. To bridge this gap, we present FeB4RAG, a novel dataset specifically designed for federated search within RAG frameworks. This dataset, derived from 16 sub-collections of the widely used \beir benchmarking collection, includes 790 information requests (akin to conversational queries) tailored for chatbot applications, along with top results returned by each resource and associated LLM-derived relevance judgements. Additionally, to support the need for this collection, we demonstrate the impact on response generation of a high quality federated search system for RAG compared to a naive approach to federated search. We do so by comparing answers generated through the RAG pipeline through a qualitative side-by-side comparison. Our collection fosters and supports the development and evaluation of new federated search methods, especially in the context of RAG pipelines.
Leveraging LLMs for Unsupervised Dense Retriever Ranking
Feb 07, 2024



This paper introduces a novel unsupervised technique that utilizes large language models (LLMs) to determine the most suitable dense retriever for a specific test(target) corpus. Selecting the appropriate dense retriever is vital for numerous IR applications that employ these retrievers, trained on public datasets, to encode or conduct searches within a new private target corpus. The effectiveness of a dense retriever can significantly diminish when applied to a target corpus that diverges in domain or task from the original training set. The problem becomes more pronounced in cases where the target corpus is unlabeled, e.g. in zero-shot scenarios, rendering direct evaluation of the model's effectiveness on the target corpus unattainable. Therefore, the unsupervised selection of an optimally pre-trained dense retriever, especially under conditions of domain shift, emerges as a critical challenge. Existing methodologies for ranking dense retrievers fall short in addressing these domain shift scenarios. To tackle this, our method capitalizes on LLMs to create pseudo-relevant queries, labels, and reference lists by analyzing a subset of documents from the target corpus. This allows for the ranking of dense retrievers based on their performance with these pseudo-relevant signals. Significantly, this strategy is the first to depend exclusively on the target corpus data, removing the necessity for training data and test labels. We assessed the effectiveness of our approach by compiling a comprehensive pool of cutting-edge dense retrievers and comparing our method against traditional dense retriever selection benchmarks. The findings reveal that our proposed solution surpasses the existing benchmarks in both the selection and ranking of dense retrievers.
Selecting which Dense Retriever to use for Zero-Shot Search
Sep 18, 2023We propose the new problem of choosing which dense retrieval model to use when searching on a new collection for which no labels are available, i.e. in a zero-shot setting. Many dense retrieval models are readily available. Each model however is characterized by very differing search effectiveness -- not just on the test portion of the datasets in which the dense representations have been learned but, importantly, also across different datasets for which data was not used to learn the dense representations. This is because dense retrievers typically require training on a large amount of labeled data to achieve satisfactory search effectiveness in a specific dataset or domain. Moreover, effectiveness gains obtained by dense retrievers on datasets for which they are able to observe labels during training, do not necessarily generalise to datasets that have not been observed during training. This is however a hard problem: through empirical experimentation we show that methods inspired by recent work in unsupervised performance evaluation with the presence of domain shift in the area of computer vision and machine learning are not effective for choosing highly performing dense retrievers in our setup. The availability of reliable methods for the selection of dense retrieval models in zero-shot settings that do not require the collection of labels for evaluation would allow to streamline the widespread adoption of dense retrieval. This is therefore an important new problem we believe the information retrieval community should consider. Implementation of methods, along with raw result files and analysis scripts are made publicly available at https://www.github.com/anonymized.
Rethinking Persistent Homology for Visual Recognition
Jul 09, 2022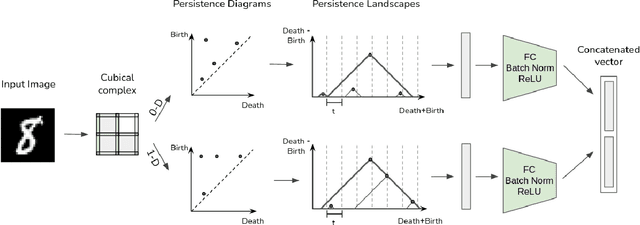
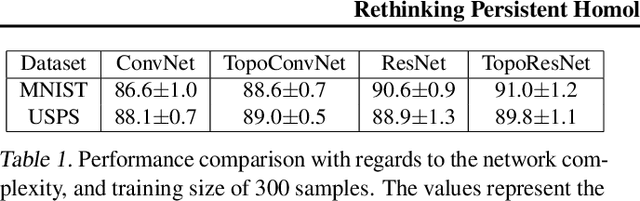
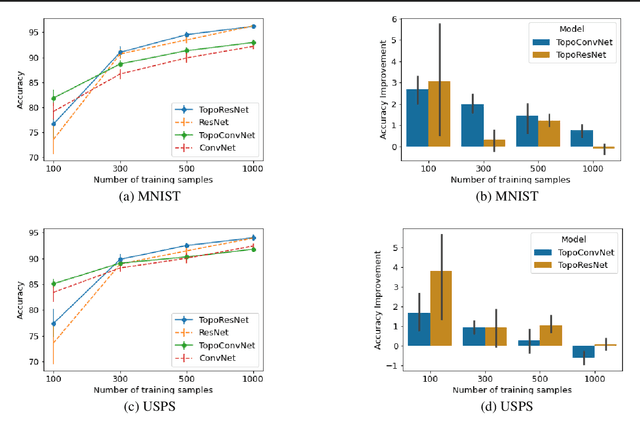
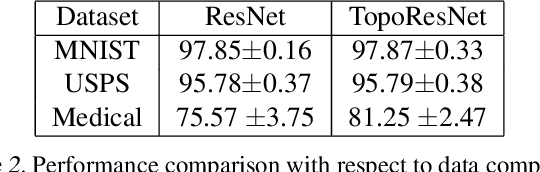
Persistent topological properties of an image serve as an additional descriptor providing an insight that might not be discovered by traditional neural networks. The existing research in this area focuses primarily on efficiently integrating topological properties of the data in the learning process in order to enhance the performance. However, there is no existing study to demonstrate all possible scenarios where introducing topological properties can boost or harm the performance. This paper performs a detailed analysis of the effectiveness of topological properties for image classification in various training scenarios, defined by: the number of training samples, the complexity of the training data and the complexity of the backbone network. We identify the scenarios that benefit the most from topological features, e.g., training simple networks on small datasets. Additionally, we discuss the problem of topological consistency of the datasets which is one of the major bottlenecks for using topological features for classification. We further demonstrate how the topological inconsistency can harm the performance for certain scenarios.