 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-Pool Setwise Reranking with Long-Context Language Models
Jun 01, 2026Previous LLM-based passage re-rankers are often expensive and slow because the input context constraints require the LLM to make many dependent model calls. We study how recent long-context LLMs change this problem: when the full set of retrieved candidate passages can be shown to the model at once, ranking no longer has to be reconstructed from many overlapping local comparisons. We propose Whole-Pool Setwise re-ranking, where each call considers all currently unranked candidate passages, and introduce DualEnd, which identifies both the most and least relevant passages in one call. By filling the ranking from both ends, DualEnd ranks 100 candidates with 50 serial LLM calls, compared with 99 calls for comparable one-passage-at-a-time whole-pool methods. Experiments with nine open-weight LLMs on two passage re-ranking benchmarks, measuring effectiveness, call count, token use, runtime, and output reliability shows that long context is not merely more prompt space, but an opportunity to make LLM re-rankers both effective and efficient.
On the impact of retrieved content representations in RAG Pipelines
May 29, 2026Retrieval-Augmented Generation (RAG) supplements a language model's input with retrieved documents, yet most RAG pipelines inherit retrieval components designed for human readers. How retrieved content should be represented when the consumer is a large language model (LLM) rather than a human is less well understood. Recent work has proposed transformations of retrieved content and identified properties that affect generation, but each examines a single transformation or property in isolation, leaving open which features of a document's representation matter most. We address this with a controlled comparison: holding retrieval fixed, we vary only the representation of retrieved documents, comparing an original baseline against thirteen transformations spanning selection, summarisation, and reformulation, in query-dependent and query-independent variants. Across these fourteen representations we measure question-answering accuracy for four generators, and for each representation we also measure answer retention: whether a known answer-bearing document still supports its answer after transformation. We find that answer retention is the primary determinant of generator accuracy; notably, when retention is high, a representation's wording, structure, length, and query-dependence have limited effect. This suggests that accuracy gains attributed to specific mechanisms in prior work may be partly explained by how well those mechanisms preserve answer-bearing content, an attribution that cannot be settled without controlling for retention.
Can It Reach the Generator? Investigating the Survival of Prompt-Injection Attacks in Realistic RAG Settings
May 28, 2026Recent generative engine optimisation (GEO) research has shown that prompt-injection attacks can push a target product to the top of an LLM's recommendation list, with the strongest attacks reporting around $80\%$ success and raising serious security concerns about RAG-based recommendation. However, these results assume the attacked document is always fed directly to the generator, bypassing the retriever and reranker. This is unrealistic: in deployed RAG systems, the attack modifies the document content, which can in turn change whether the document is retrieved and reranked highly enough to reach the generator at all. In this paper, we re-evaluate seven GEO attacks under a realistic three-stage pipeline (retriever\,$\to$\,LLM reranker\,$\to$\,LLM generator). We find that prior protocols substantially overstate attack effectiveness: gradient-based and instruction override attacks largely collapse before reaching the generator, and only LLM-driven prompt injections remain effective end-to-end. Our analysis further reveals that current GEO attacks are easily detectable: a lightweight prompt-injection guard finetuned on a small attack dataset already detects every attack. Our code and data are available at https://github.com/ielab/geo_injection_rag_survival.
Toward Clinically Acceptable Chest X-ray Report Generation: A Qualitative Retrospective Pilot Study of CXRMate-2
Apr 21, 2026Chest X-ray (CXR) radiology report generation (RRG) models have shown rapid progress, yet their clinical utility remains uncertain due to limited evaluation by radiologists. We present CXRMate-2, a state-of-the-art CXR RRG model that integrates structured multimodal conditioning and reinforcement learning with a composite reward for semantic alignment with radiologist reports. Across the MIMIC-CXR, CheXpert Plus, and ReXgradient datasets, CXRMate-2 achieves statistically significant improvements over strong benchmarks, including gains of 11.2% and 24.4% in GREEN and RadGraph-XL, respectively, on MIMIC-CXR relative to MedGemma 1.5 (4B). To directly compare CXRMate-2 against radiologist reporting, we conduct a blinded, randomised qualitative retrospective evaluation. Three consultant radiologists compare generated and radiologist reports across 120 studies from the MIMIC-CXR test set. Generated reports were deemed acceptable (defined as preferred or rated equally to radiologist reports) in 45% of ratings, with no statistically significant difference in preference rates between radiologist reports and acceptable generated reports for seven of the eight analysed findings. Preference for radiologist reports was driven primarily by higher recall, while generated reports were often preferred for readability. Together, these results suggest a credible pathway to clinically acceptable CXR RRG. Improvements in recall, alongside better detection of subtle findings (e.g., pulmonary congestion), are likely sufficient to achieve non-inferiority to radiologist reporting. With these targeted advances, CXR RRG systems may be ready for prospective evaluation in assistive roles within radiologist-led workflows.
Beyond Chunk-Then-Embed: A Comprehensive Taxonomy and Evaluation of Document Chunking Strategies for Information Retrieval
Feb 19, 2026Document chunking is a critical preprocessing step in dense retrieval systems, yet the design space of chunking strategies remains poorly understood. Recent research has proposed several concurrent approaches, including LLM-guided methods (e.g., DenseX and LumberChunker) and contextualized strategies(e.g., Late Chunking), which generate embeddings before segmentation to preserve contextual information. However, these methods emerged independently and were evaluated on benchmarks with minimal overlap, making direct comparisons difficult. This paper reproduces prior studies in document chunking and presents a systematic framework that unifies existing strategies along two key dimensions: (1) segmentation methods, including structure-based methods (fixed-size, sentence-based, and paragraph-based) as well as semantically-informed and LLM-guided methods; and (2) embedding paradigms, which determine the timing of chunking relative to embedding (pre-embedding chunking vs. contextualized chunking). Our reproduction evaluates these approaches in two distinct retrieval settings established in previous work: in-document retrieval (needle-in-a-haystack) and in-corpus retrieval (the standard information retrieval task). Our comprehensive evaluation reveals that optimal chunking strategies are task-dependent: simple structure-based methods outperform LLM-guided alternatives for in-corpus retrieval, while LumberChunker performs best for in-document retrieval. Contextualized chunking improves in-corpus effectiveness but degrades in-document retrieval. We also find that chunk size correlates moderately with in-document but weakly with in-corpus effectiveness, suggesting segmentation method differences are not purely driven by chunk size. Our code and evaluation benchmarks are publicly available at (Anonymoused).
Reassessing Large Language Model Boolean Query Generation for Systematic Reviews
May 12, 2025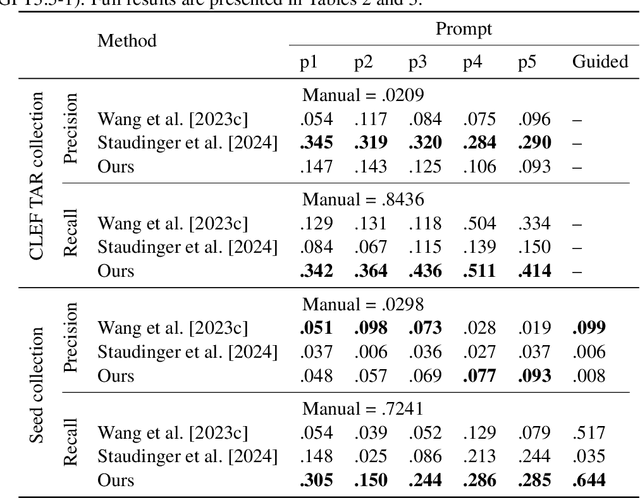
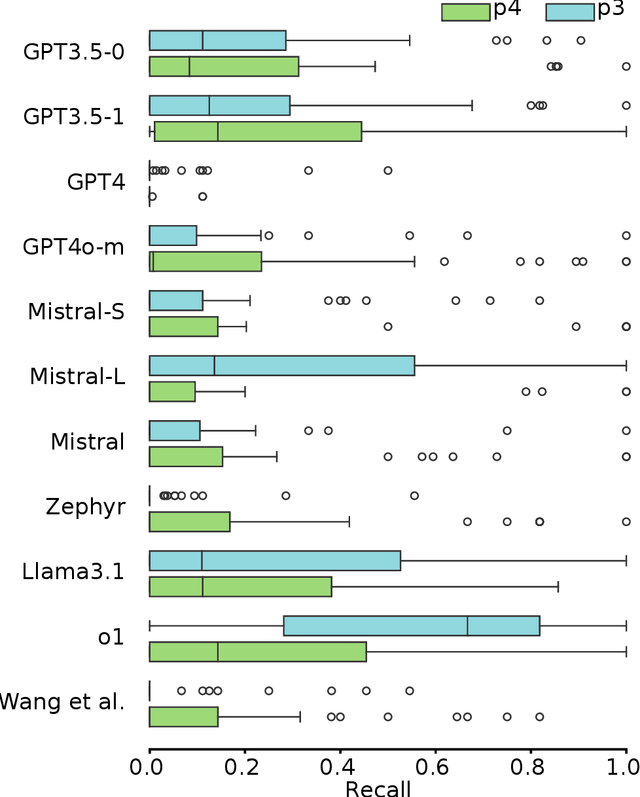
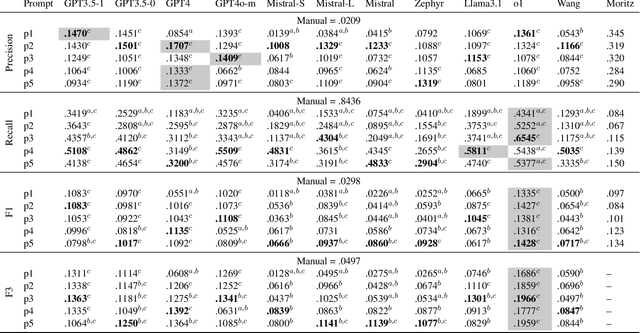

Systematic reviews are comprehensive literature reviews that address highly focused research questions and represent the highest form of evidence in medicine. A critical step in this process is the development of complex Boolean queries to retrieve relevant literature. Given the difficulty of manually constructing these queries, recent efforts have explored Large Language Models (LLMs) to assist in their formulation. One of the first studies,Wang et al., investigated ChatGPT for this task, followed by Staudinger et al., which evaluated multiple LLMs in a reproducibility study. However, the latter overlooked several key aspects of the original work, including (i) validation of generated queries, (ii) output formatting constraints, and (iii) selection of examples for chain-of-thought (Guided) prompting. As a result, its findings diverged significantly from the original study. In this work, we systematically reproduce both studies while addressing these overlooked factors. Our results show that query effectiveness varies significantly across models and prompt designs, with guided query formulation benefiting from well-chosen seed studies. Overall, prompt design and model selection are key drivers of successful query formulation. Our findings provide a clearer understanding of LLMs' potential in Boolean query generation and highlight the importance of model- and prompt-specific optimisations. The complex nature of systematic reviews adds to challenges in both developing and reproducing methods but also highlights the importance of reproducibility studies in this domain.
LLM-VPRF: Large Language Model Based Vector Pseudo Relevance Feedback
Apr 02, 2025Vector Pseudo Relevance Feedback (VPRF) has shown promising results in improving BERT-based dense retrieval systems through iterative refinement of query representations. This paper investigates the generalizability of VPRF to Large Language Model (LLM) based dense retrievers. We introduce LLM-VPRF and evaluate its effectiveness across multiple benchmark datasets, analyzing how different LLMs impact the feedback mechanism. Our results demonstrate that VPRF's benefits successfully extend to LLM architectures, establishing it as a robust technique for enhancing dense retrieval performance regardless of the underlying models. This work bridges the gap between VPRF with traditional BERT-based dense retrievers and modern LLMs, while providing insights into their future directions.
Pseudo-Relevance Feedback Can Improve Zero-Shot LLM-Based Dense Retrieval
Mar 19, 2025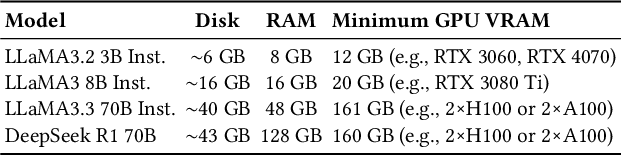
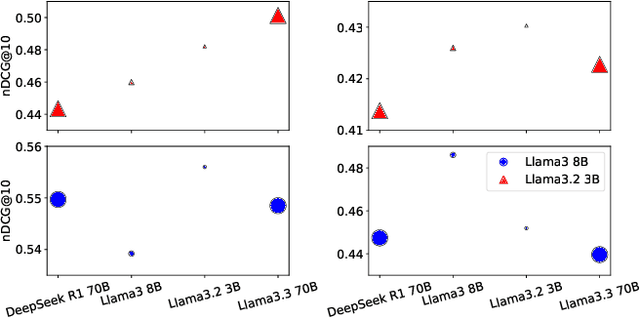

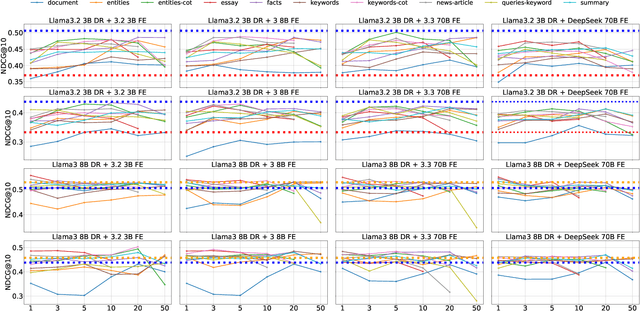
Pseudo-relevance feedback (PRF) refines queries by leveraging initially retrieved documents to improve retrieval effectiveness. In this paper, we investigate how large language models (LLMs) can facilitate PRF for zero-shot LLM-based dense retrieval, extending the recently proposed PromptReps method. Specifically, our approach uses LLMs to extract salient passage features-such as keywords and summaries-from top-ranked documents, which are then integrated into PromptReps to produce enhanced query representations. Experiments on passage retrieval benchmarks demonstrate that incorporating PRF significantly boosts retrieval performance. Notably, smaller rankers with PRF can match the effectiveness of larger rankers without PRF, highlighting PRF's potential to improve LLM-driven search while maintaining an efficient balance between effectiveness and resource usage.
Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning
Mar 08, 2025
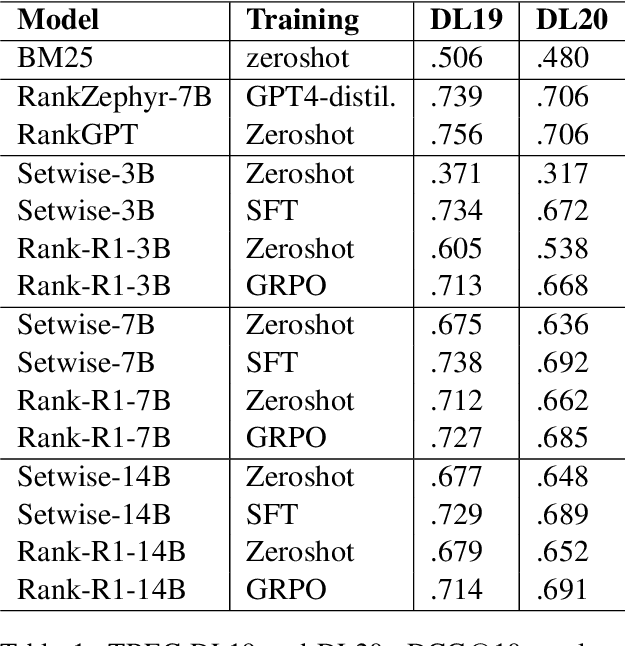
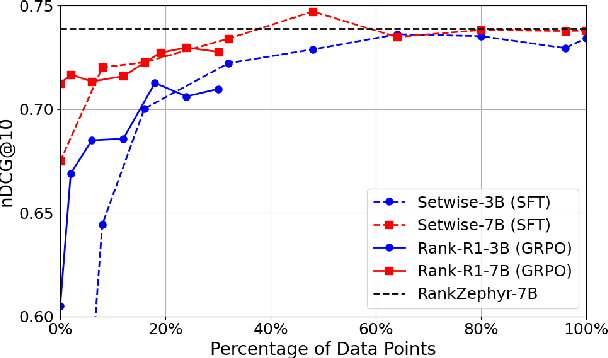
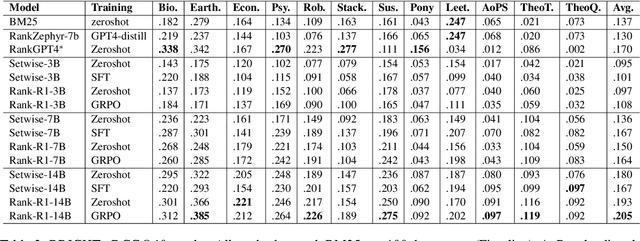
In this paper, we introduce Rank-R1, a novel LLM-based reranker that performs reasoning over both the user query and candidate documents before performing the ranking task. Existing document reranking methods based on large language models (LLMs) typically rely on prompting or fine-tuning LLMs to order or label candidate documents according to their relevance to a query. For Rank-R1, we use a reinforcement learning algorithm along with only a small set of relevance labels (without any reasoning supervision) to enhance the reasoning ability of LLM-based rerankers. Our hypothesis is that adding reasoning capabilities to the rerankers can improve their relevance assessement and ranking capabilities. Our experiments on the TREC DL and BRIGHT datasets show that Rank-R1 is highly effective, especially for complex queries. In particular, we find that Rank-R1 achieves effectiveness on in-domain datasets at par with that of supervised fine-tuning methods, but utilizing only 18\% of the training data used by the fine-tuning methods. We also find that the model largely outperforms zero-shot and supervised fine-tuning when applied to out-of-domain datasets featuring complex queries, especially when a 14B-size model is used. Finally, we qualitatively observe that Rank-R1's reasoning process improves the explainability of the ranking results, opening new opportunities for search engine results presentation and fruition.
Document Screenshot Retrievers are Vulnerable to Pixel Poisoning Attacks
Jan 28, 2025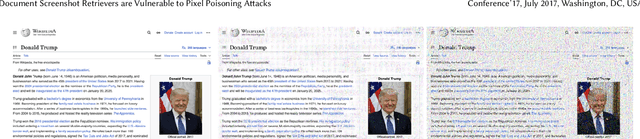
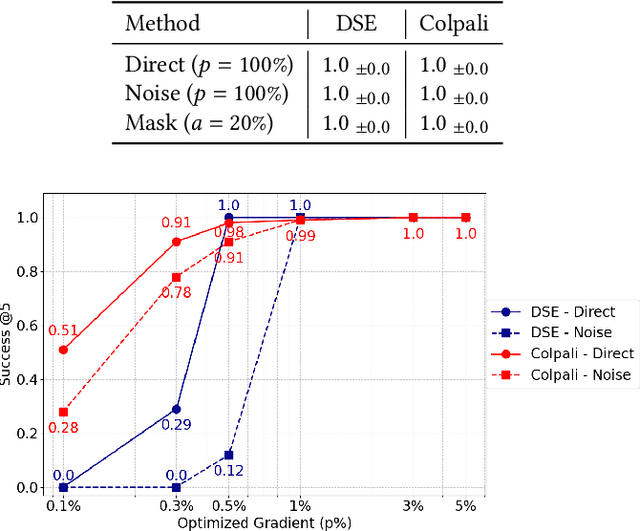

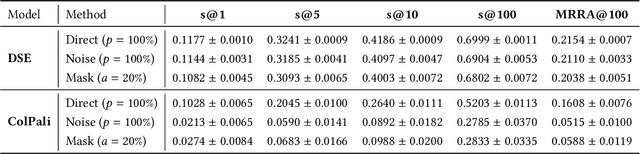
Recent advancements in dense retrieval have introduced vision-language model (VLM)-based retrievers, such as DSE and ColPali, which leverage document screenshots embedded as vectors to enable effective search and offer a simplified pipeline over traditional text-only methods. In this study, we propose three pixel poisoning attack methods designed to compromise VLM-based retrievers and evaluate their effectiveness under various attack settings and parameter configurations. Our empirical results demonstrate that injecting even a single adversarial screenshot into the retrieval corpus can significantly disrupt search results, poisoning the top-10 retrieved documents for 41.9% of queries in the case of DSE and 26.4% for ColPali. These vulnerability rates notably exceed those observed with equivalent attacks on text-only retrievers. Moreover, when targeting a small set of known queries, the attack success rate raises, achieving complete success in certain cases. By exposing the vulnerabilities inherent in vision-language models, this work highlights the potential risks associated with their deployment.