Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoLEM and IndoBERT: A Benchmark Dataset and Pre-trained Language Model for Indonesian NLP
Paper and Code
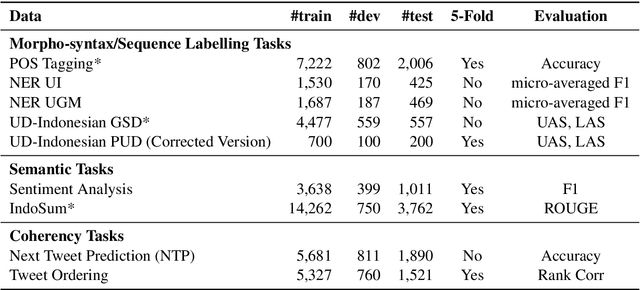
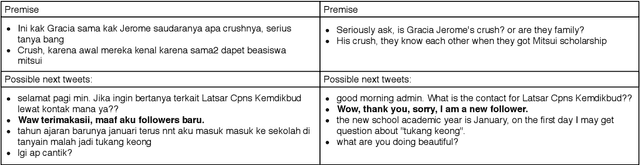
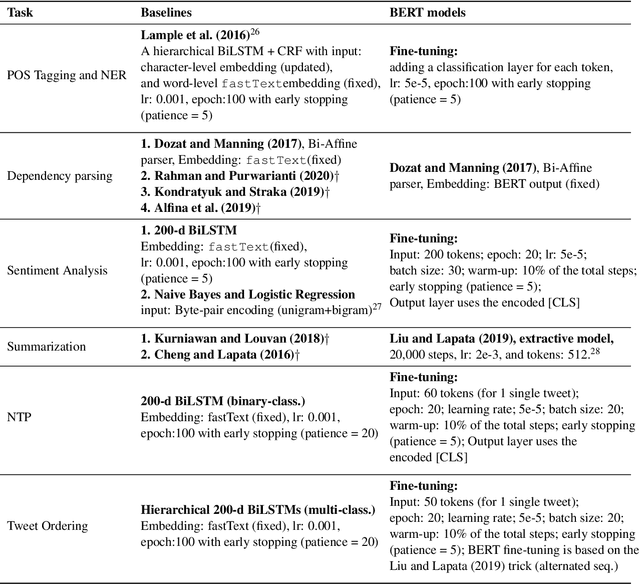
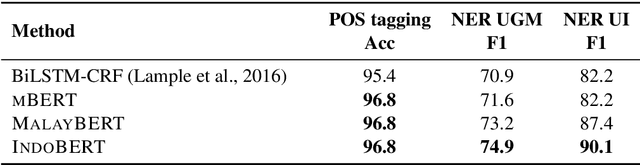
Although the Indonesian language is spoken by almost 200 million people and the 10th most spoken language in the world, it is under-represented in NLP research. Previous work on Indonesian has been hampered by a lack of annotated datasets, a sparsity of language resources, and a lack of resource standardization. In this work, we release the IndoLEM dataset comprising seven tasks for the Indonesian language, spanning morpho-syntax, semantics, and discourse. We additionally release IndoBERT, a new pre-trained language model for Indonesian, and evaluate it over IndoLEM, in addition to benchmarking it against existing resources. Our experiments show that IndoBERT achieves state-of-the-art performance over most of the tasks in IndoLEM.
* Accepted at COLING 2020 - The 28th International Conference on
Computational Linguistics
View paper on