 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Geospatial Reasoning Capabilities of LLMs: A Trajectory Recovery Perspective
Oct 02, 2025We explore the geospatial reasoning capabilities of Large Language Models (LLMs), specifically, whether LLMs can read road network maps and perform navigation. We frame trajectory recovery as a proxy task, which requires models to reconstruct masked GPS traces, and introduce GLOBALTRACE, a dataset with over 4,000 real-world trajectories across diverse regions and transportation modes. Using road network as context, our prompting framework enables LLMs to generate valid paths without accessing any external navigation tools. Experiments show that LLMs outperform off-the-shelf baselines and specialized trajectory recovery models, with strong zero-shot generalization. Fine-grained analysis shows that LLMs have strong comprehension of the road network and coordinate systems, but also pose systematic biases with respect to regions and transportation modes. Finally, we demonstrate how LLMs can enhance navigation experiences by reasoning over maps in flexible ways to incorporate user preferences.
Revisiting subword tokenization: A case study on affixal negation in large language models
Apr 04, 2024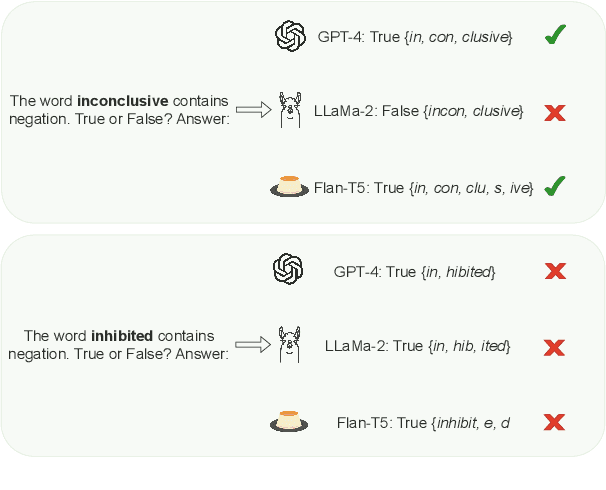
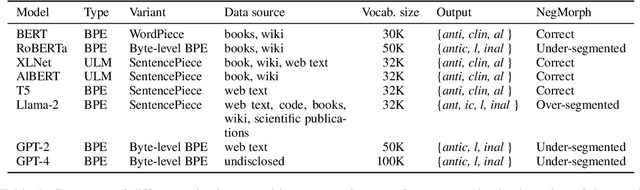
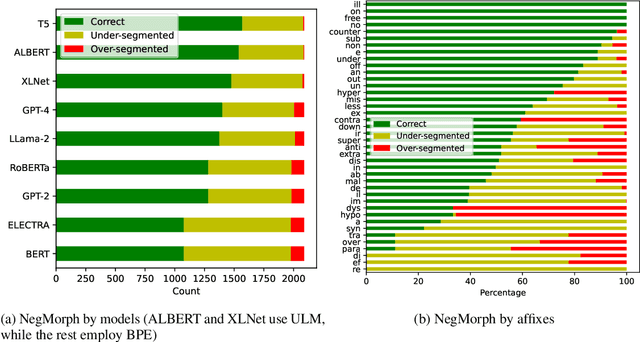
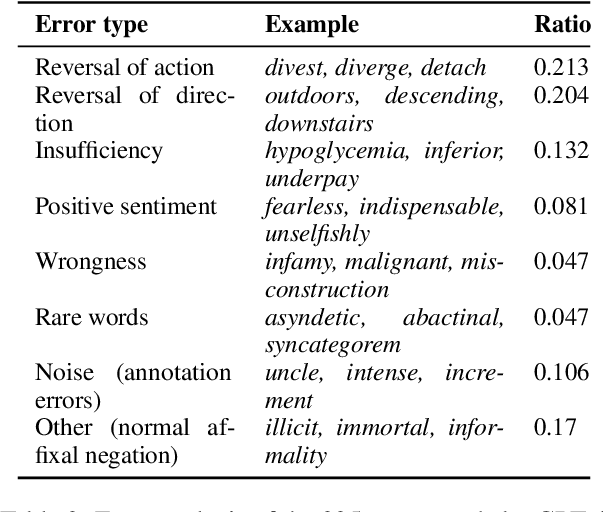
In this work, we measure the impact of affixal negation on modern English large language models (LLMs). In affixal negation, the negated meaning is expressed through a negative morpheme, which is potentially challenging for LLMs as their tokenizers are often not morphologically plausible. We conduct extensive experiments using LLMs with different subword tokenization methods, which lead to several insights on the interaction between tokenization performance and negation sensitivity. Despite some interesting mismatches between tokenization accuracy and negation detection performance, we show that models can, on the whole, reliably recognize the meaning of affixal negation.
Language models are not naysayers: An analysis of language models on negation benchmarks
Jun 14, 2023



Negation has been shown to be a major bottleneck for masked language models, such as BERT. However, whether this finding still holds for larger-sized auto-regressive language models (``LLMs'') has not been studied comprehensively. With the ever-increasing volume of research and applications of LLMs, we take a step back to evaluate the ability of current-generation LLMs to handle negation, a fundamental linguistic phenomenon that is central to language understanding. We evaluate different LLMs -- including the open-source GPT-neo, GPT-3, and InstructGPT -- against a wide range of negation benchmarks. Through systematic experimentation with varying model sizes and prompts, we show that LLMs have several limitations including insensitivity to the presence of negation, an inability to capture the lexical semantics of negation, and a failure to reason under negation.
Automated Metrics for Medical Multi-Document Summarization Disagree with Human Evaluations
May 23, 2023Evaluating multi-document summarization (MDS) quality is difficult. This is especially true in the case of MDS for biomedical literature reviews, where models must synthesize contradicting evidence reported across different documents. Prior work has shown that rather than performing the task, models may exploit shortcuts that are difficult to detect using standard n-gram similarity metrics such as ROUGE. Better automated evaluation metrics are needed, but few resources exist to assess metrics when they are proposed. Therefore, we introduce a dataset of human-assessed summary quality facets and pairwise preferences to encourage and support the development of better automated evaluation methods for literature review MDS. We take advantage of community submissions to the Multi-document Summarization for Literature Review (MSLR) shared task to compile a diverse and representative sample of generated summaries. We analyze how automated summarization evaluation metrics correlate with lexical features of generated summaries, to other automated metrics including several we propose in this work, and to aspects of human-assessed summary quality. We find that not only do automated metrics fail to capture aspects of quality as assessed by humans, in many cases the system rankings produced by these metrics are anti-correlated with rankings according to human annotators.
From Disfluency Detection to Intent Detection and Slot Filling
Sep 17, 2022



We present the first empirical study investigating the influence of disfluency detection on downstream tasks of intent detection and slot filling. We perform this study for Vietnamese -- a low-resource language that has no previous study as well as no public dataset available for disfluency detection. First, we extend the fluent Vietnamese intent detection and slot filling dataset PhoATIS by manually adding contextual disfluencies and annotating them. Then, we conduct experiments using strong baselines for disfluency detection and joint intent detection and slot filling, which are based on pre-trained language models. We find that: (i) disfluencies produce negative effects on the performances of the downstream intent detection and slot filling tasks, and (ii) in the disfluency context, the pre-trained multilingual language model XLM-R helps produce better intent detection and slot filling performances than the pre-trained monolingual language model PhoBERT, and this is opposite to what generally found in the fluency context.
Improving negation detection with negation-focused pre-training
May 09, 2022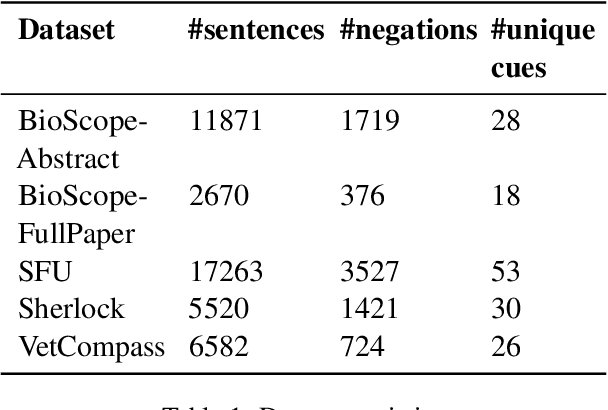



Negation is a common linguistic feature that is crucial in many language understanding tasks, yet it remains a hard problem due to diversity in its expression in different types of text. Recent work has shown that state-of-the-art NLP models underperform on samples containing negation in various tasks, and that negation detection models do not transfer well across domains. We propose a new negation-focused pre-training strategy, involving targeted data augmentation and negation masking, to better incorporate negation information into language models. Extensive experiments on common benchmarks show that our proposed approach improves negation detection performance and generalizability over the strong baseline NegBERT (Khandewal and Sawant, 2020).
ITTC @ TREC 2021 Clinical Trials Track
Feb 16, 2022
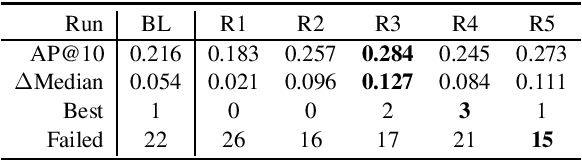
This paper describes the submissions of the Natural Language Processing (NLP) team from the Australian Research Council Industrial Transformation Training Centre (ITTC) for Cognitive Computing in Medical Technologies to the TREC 2021 Clinical Trials Track. The task focuses on the problem of matching eligible clinical trials to topics constituting a summary of a patient's admission notes. We explore different ways of representing trials and topics using NLP techniques, and then use a common retrieval model to generate the ranked list of relevant trials for each topic. The results from all our submitted runs are well above the median scores for all topics, but there is still plenty of scope for improvement.
COVID-19 Named Entity Recognition for Vietnamese
Apr 08, 2021

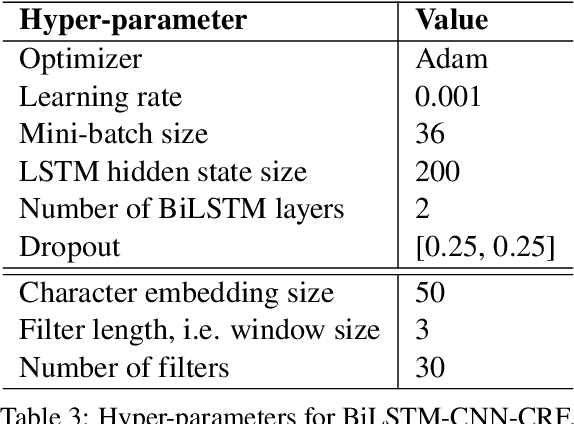
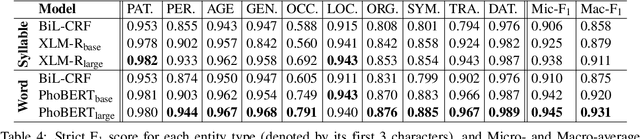
The current COVID-19 pandemic has lead to the creation of many corpora that facilitate NLP research and downstream applications to help fight the pandemic. However, most of these corpora are exclusively for English. As the pandemic is a global problem, it is worth creating COVID-19 related datasets for languages other than English. In this paper, we present the first manually-annotated COVID-19 domain-specific dataset for Vietnamese. Particularly, our dataset is annotated for the named entity recognition (NER) task with newly-defined entity types that can be used in other future epidemics. Our dataset also contains the largest number of entities compared to existing Vietnamese NER datasets. We empirically conduct experiments using strong baselines on our dataset, and find that: automatic Vietnamese word segmentation helps improve the NER results and the highest performances are obtained by fine-tuning pre-trained language models where the monolingual model PhoBERT for Vietnamese (Nguyen and Nguyen, 2020) produces higher results than the multilingual model XLM-R (Conneau et al., 2020). We publicly release our dataset at: https://github.com/VinAIResearch/PhoNER_COVID19
Intent detection and slot filling for Vietnamese
Apr 05, 2021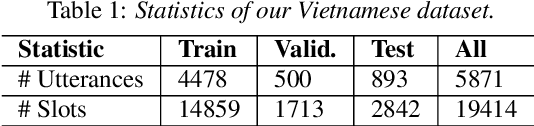
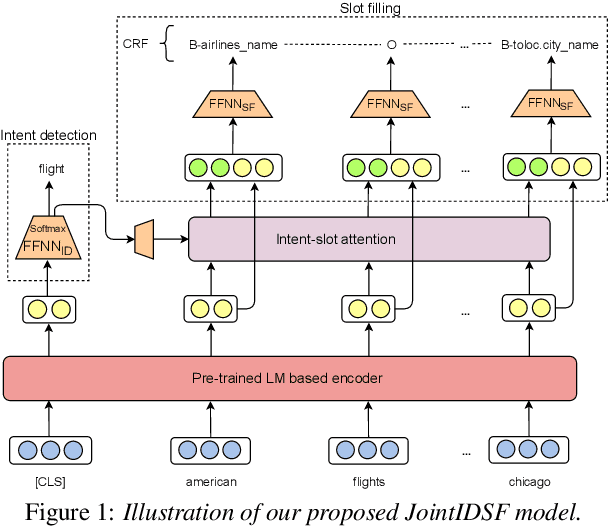


Intent detection and slot filling are important tasks in spoken and natural language understanding. However, Vietnamese is a low-resource language in these research topics. In this paper, we present the first public intent detection and slot filling dataset for Vietnamese. In addition, we also propose a joint model for intent detection and slot filling, that extends the recent state-of-the-art JointBERT+CRF model with an intent-slot attention layer in order to explicitly incorporate intent context information into slot filling via "soft" intent label embedding. Experimental results on our Vietnamese dataset show that our proposed model significantly outperforms JointBERT+CRF. We publicly release our dataset and the implementation of our model at: https://github.com/VinAIResearch/JointIDSF