 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of the Quality of Textual Data on Feature Representation and Machine Learning Models
Feb 12, 2025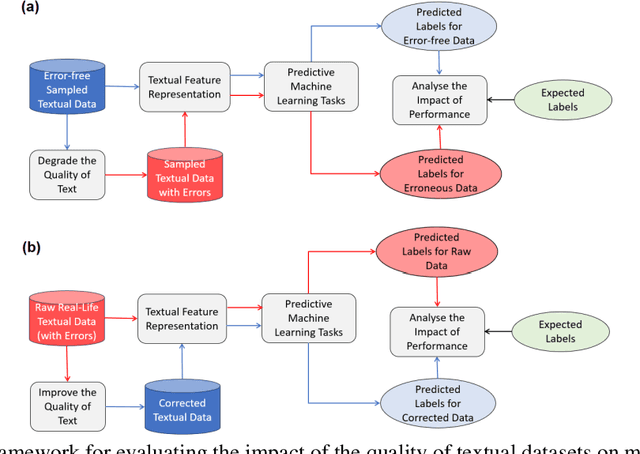
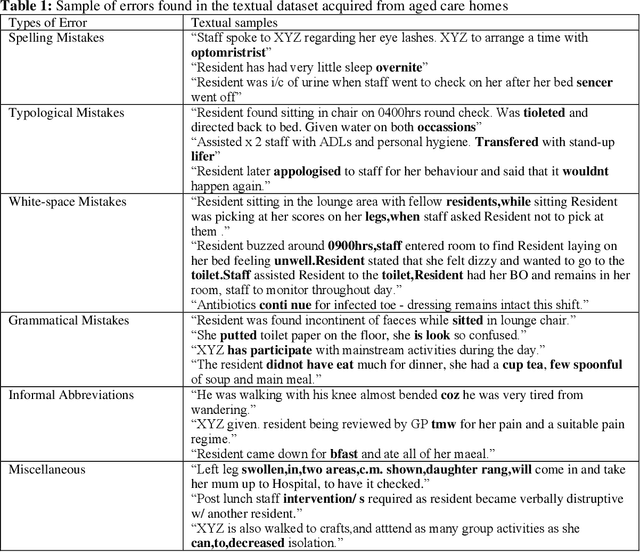
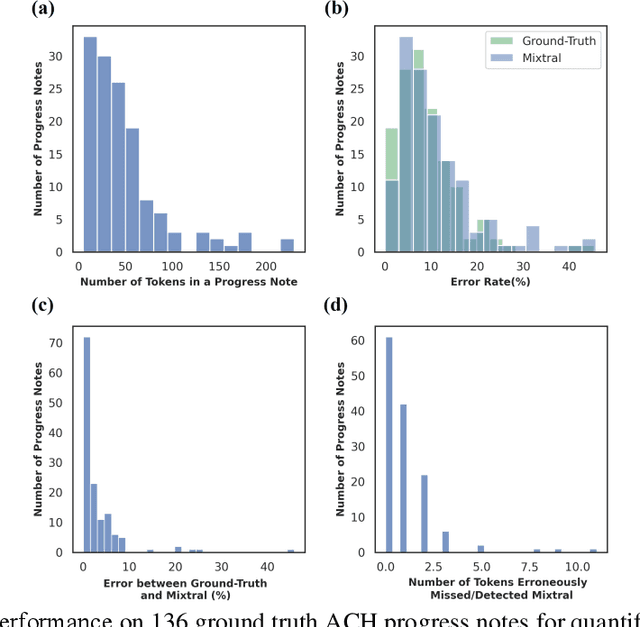
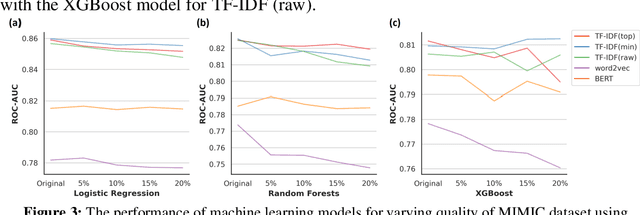
Background: Data collected in controlled settings typically results in high-quality datasets. However, in real-world applications, the quality of data collection is often compromised. It is well established that the quality of a dataset significantly impacts the performance of machine learning models. Methods: A rudimentary error rate metric was developed to evaluate textual dataset quality at the token level. Mixtral Large Language Model (LLM) was used to quantify and correct errors in low quality datasets. The study analyzed two healthcare datasets: the high-quality MIMIC-III public hospital dataset and a lower-quality private dataset from Australian aged care homes. Errors were systematically introduced into MIMIC at varying rates, while the ACH dataset quality was improved using the LLM. Results: For the sampled 35,774 and 6,336 patients from the MIMIC and ACH datasets respectively, we used Mixtral to introduce errors in MIMIC and correct errors in ACH. Mixtral correctly detected errors in 63% of progress notes, with 17% containing a single token misclassified due to medical terminology. LLMs demonstrated potential for improving progress note quality by addressing various errors. Under varying error rates, feature representation performance was tolerant to lower error rates (<10%) but declined significantly at higher rates. Conclusions: The study revealed that models performed relatively well on datasets with lower error rates (<10%), but their performance declined significantly as error rates increased (>=10%). Therefore, it is crucial to evaluate the quality of a dataset before utilizing it for machine learning tasks. For datasets with higher error rates, implementing corrective measures is essential to ensure the reliability and effectiveness of machine learning models.
ITTC @ TREC 2021 Clinical Trials Track
Feb 16, 2022
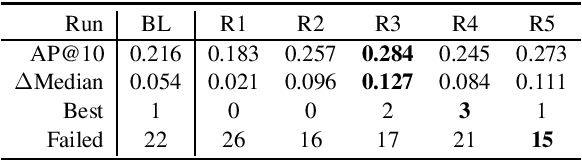
This paper describes the submissions of the Natural Language Processing (NLP) team from the Australian Research Council Industrial Transformation Training Centre (ITTC) for Cognitive Computing in Medical Technologies to the TREC 2021 Clinical Trials Track. The task focuses on the problem of matching eligible clinical trials to topics constituting a summary of a patient's admission notes. We explore different ways of representing trials and topics using NLP techniques, and then use a common retrieval model to generate the ranked list of relevant trials for each topic. The results from all our submitted runs are well above the median scores for all topics, but there is still plenty of scope for improvement.
Conversational Search -- A Report from Dagstuhl Seminar 19461
May 18, 2020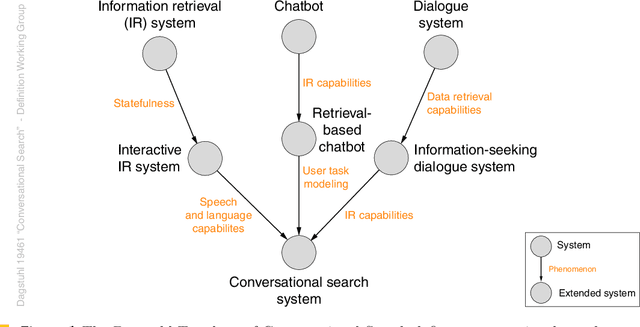
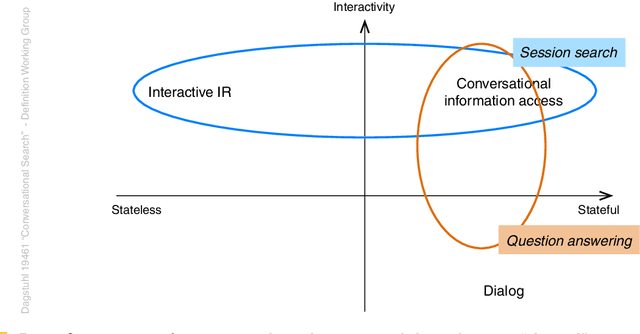
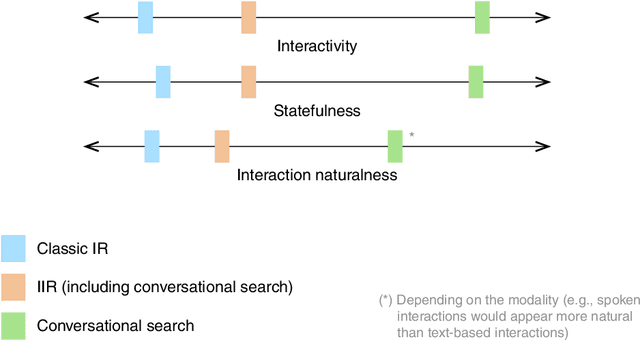

Dagstuhl Seminar 19461 "Conversational Search" was held on 10-15 November 2019. 44~researchers in Information Retrieval and Web Search, Natural Language Processing, Human Computer Interaction, and Dialogue Systems were invited to share the latest development in the area of Conversational Search and discuss its research agenda and future directions. A 5-day program of the seminar consisted of six introductory and background sessions, three visionary talk sessions, one industry talk session, and seven working groups and reporting sessions. The seminar also had three social events during the program. This report provides the executive summary, overview of invited talks, and findings from the seven working groups which cover the definition, evaluation, modelling, explanation, scenarios, applications, and prototype of Conversational Search. The ideas and findings presented in this report should serve as one of the main sources for diverse research programs on Conversational Search.
On the Transferability of Representations in Neural Networks Between Datasets and Tasks
Nov 29, 2018
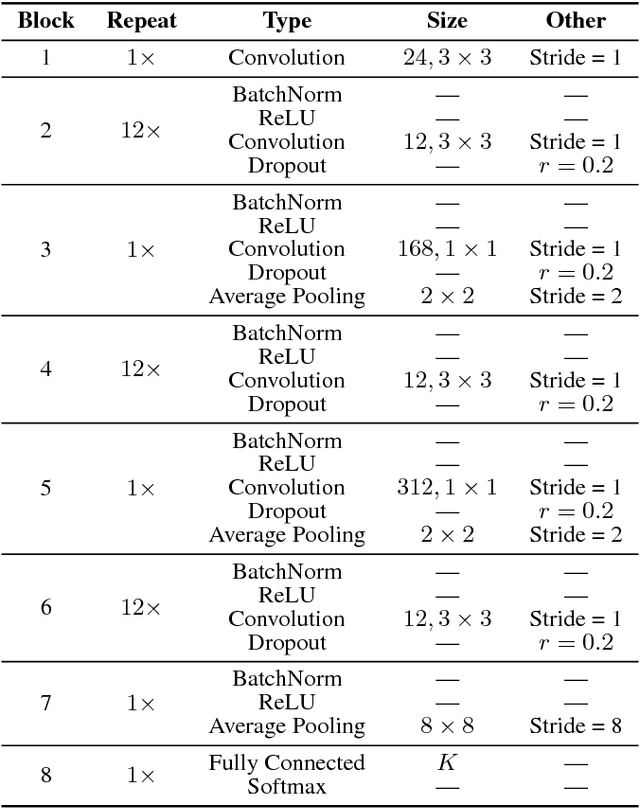
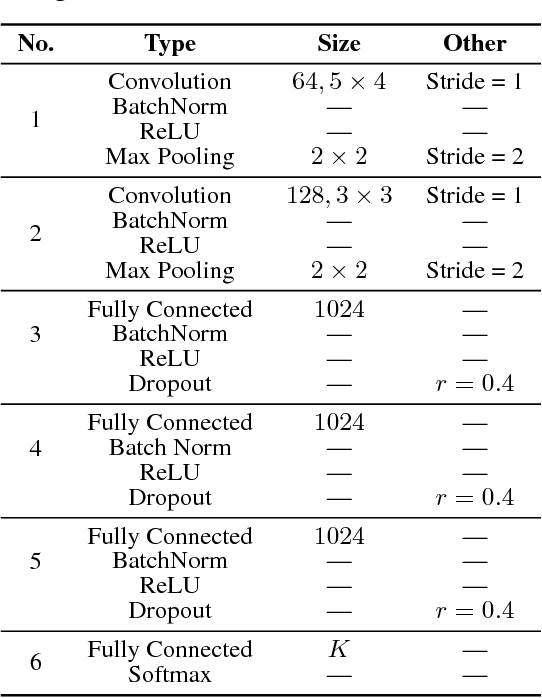

Deep networks, composed of multiple layers of hierarchical distributed representations, tend to learn low-level features in initial layers and transition to high-level features towards final layers. Paradigms such as transfer learning, multi-task learning, and continual learning leverage this notion of generic hierarchical distributed representations to share knowledge across datasets and tasks. Herein, we study the layer-wise transferability of representations in deep networks across a few datasets and tasks and note some interesting empirical observations.
* Accepted Paper in the Continual Learning Workshop, NeurIPS 2018