 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFER: Mitigating Bias in Opinion Summarisation via Frequency Framed Prompting
Sep 19, 2025Individuals express diverse opinions, a fair summary should represent these viewpoints comprehensively. Previous research on fairness in opinion summarisation using large language models (LLMs) relied on hyperparameter tuning or providing ground truth distributional information in prompts. However, these methods face practical limitations: end-users rarely modify default model parameters, and accurate distributional information is often unavailable. Building upon cognitive science research demonstrating that frequency-based representations reduce systematic biases in human statistical reasoning by making reference classes explicit and reducing cognitive load, this study investigates whether frequency framed prompting (REFER) can similarly enhance fairness in LLM opinion summarisation. Through systematic experimentation with different prompting frameworks, we adapted techniques known to improve human reasoning to elicit more effective information processing in language models compared to abstract probabilistic representations.Our results demonstrate that REFER enhances fairness in language models when summarising opinions. This effect is particularly pronounced in larger language models and using stronger reasoning instructions.
SWAP-NAS: Sample-Wise Activation Patterns for Ultra-fast NAS
Mar 13, 2024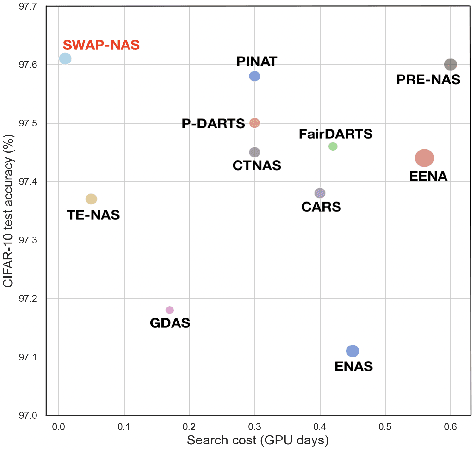
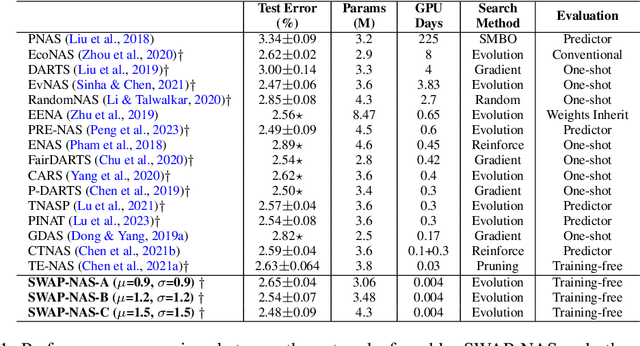

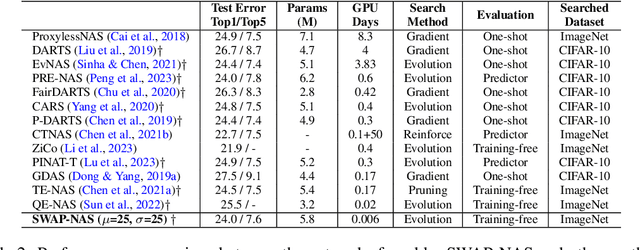
Training-free metrics (a.k.a. zero-cost proxies) are widely used to avoid resource-intensive neural network training, especially in Neural Architecture Search (NAS). Recent studies show that existing training-free metrics have several limitations, such as limited correlation and poor generalisation across different search spaces and tasks. Hence, we propose Sample-Wise Activation Patterns and its derivative, SWAP-Score, a novel high-performance training-free metric. It measures the expressivity of networks over a batch of input samples. The SWAP-Score is strongly correlated with ground-truth performance across various search spaces and tasks, outperforming 15 existing training-free metrics on NAS-Bench-101/201/301 and TransNAS-Bench-101. The SWAP-Score can be further enhanced by regularisation, which leads to even higher correlations in cell-based search space and enables model size control during the search. For example, Spearman's rank correlation coefficient between regularised SWAP-Score and CIFAR-100 validation accuracies on NAS-Bench-201 networks is 0.90, significantly higher than 0.80 from the second-best metric, NWOT. When integrated with an evolutionary algorithm for NAS, our SWAP-NAS achieves competitive performance on CIFAR-10 and ImageNet in approximately 6 minutes and 9 minutes of GPU time respectively.
The Structurally Complex with Additive Parent Causality (SCARY) Dataset
Apr 27, 2023Causal datasets play a critical role in advancing the field of causality. However, existing datasets often lack the complexity of real-world issues such as selection bias, unfaithful data, and confounding. To address this gap, we propose a new synthetic causal dataset, the Structurally Complex with Additive paRent causalitY (SCARY) dataset, which includes the following features. The dataset comprises 40 scenarios, each generated with three different seeds, allowing researchers to leverage relevant subsets of the dataset. Additionally, we use two different data generation mechanisms for generating the causal relationship between parents and child nodes, including linear and mixed causal mechanisms with multiple sub-types. Our dataset generator is inspired by the Causal Discovery Toolbox and generates only additive models. The dataset has a Varsortability of 0.5. Our SCARY dataset provides a valuable resource for researchers to explore causal discovery under more realistic scenarios. The dataset is available at https://github.com/JayJayc/SCARY.
PRE-NAS: Predictor-assisted Evolutionary Neural Architecture Search
Apr 27, 2022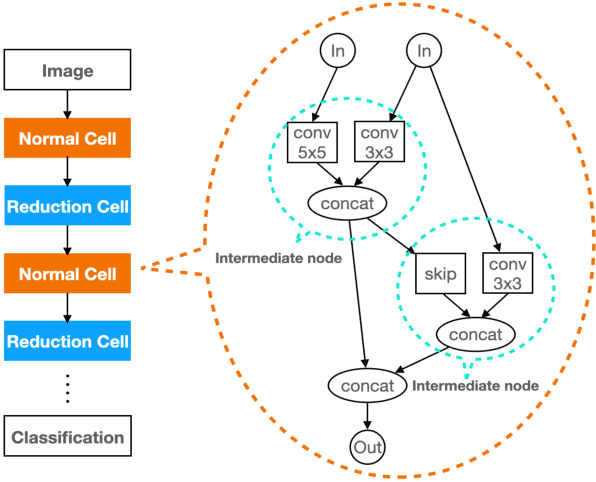
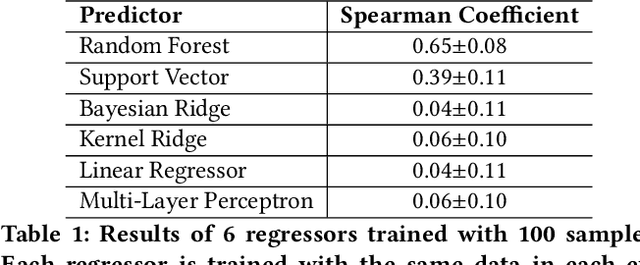
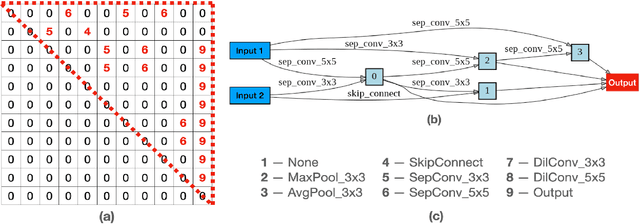
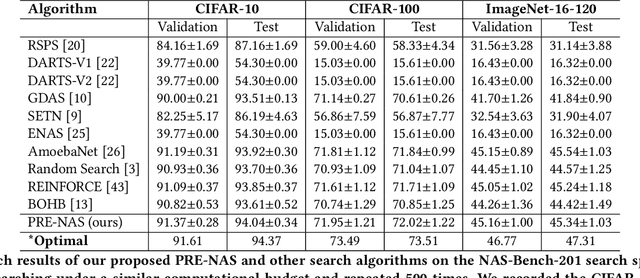
Neural architecture search (NAS) aims to automate architecture engineering in neural networks. This often requires a high computational overhead to evaluate a number of candidate networks from the set of all possible networks in the search space during the search. Prediction of the networks' performance can alleviate this high computational overhead by mitigating the need for evaluating every candidate network. Developing such a predictor typically requires a large number of evaluated architectures which may be difficult to obtain. We address this challenge by proposing a novel evolutionary-based NAS strategy, Predictor-assisted E-NAS (PRE-NAS), which can perform well even with an extremely small number of evaluated architectures. PRE-NAS leverages new evolutionary search strategies and integrates high-fidelity weight inheritance over generations. Unlike one-shot strategies, which may suffer from bias in the evaluation due to weight sharing, offspring candidates in PRE-NAS are topologically homogeneous, which circumvents bias and leads to more accurate predictions. Extensive experiments on NAS-Bench-201 and DARTS search spaces show that PRE-NAS can outperform state-of-the-art NAS methods. With only a single GPU searching for 0.6 days, competitive architecture can be found by PRE-NAS which achieves 2.40% and 24% test error rates on CIFAR-10 and ImageNet respectively.
Large Scale Audiovisual Learning of Sounds with Weakly Labeled Data
May 29, 2020
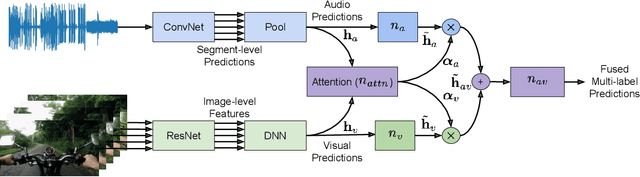
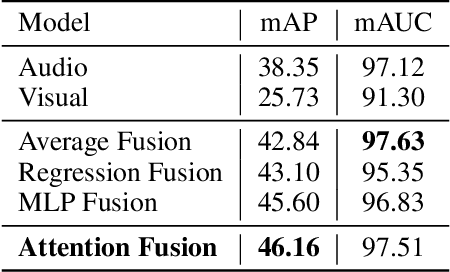
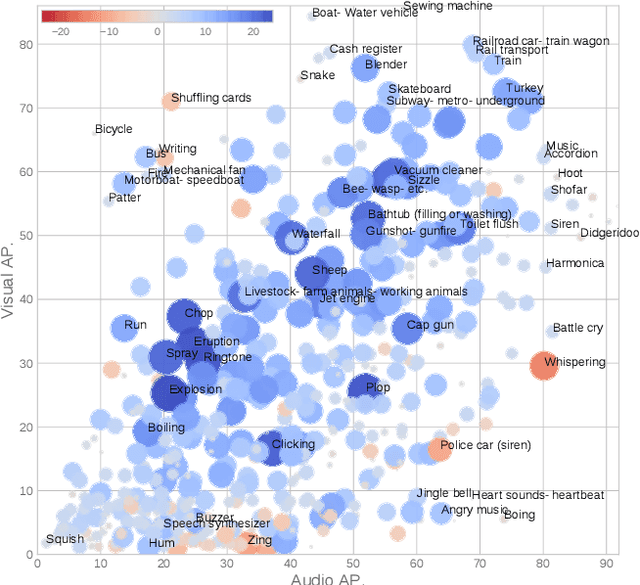
Recognizing sounds is a key aspect of computational audio scene analysis and machine perception. In this paper, we advocate that sound recognition is inherently a multi-modal audiovisual task in that it is easier to differentiate sounds using both the audio and visual modalities as opposed to one or the other. We present an audiovisual fusion model that learns to recognize sounds from weakly labeled video recordings. The proposed fusion model utilizes an attention mechanism to dynamically combine the outputs of the individual audio and visual models. Experiments on the large scale sound events dataset, AudioSet, demonstrate the efficacy of the proposed model, which outperforms the single-modal models, and state-of-the-art fusion and multi-modal models. We achieve a mean Average Precision (mAP) of 46.16 on Audioset, outperforming prior state of the art by approximately +4.35 mAP (relative: 10.4%).
Temporal Reasoning via Audio Question Answering
Nov 21, 2019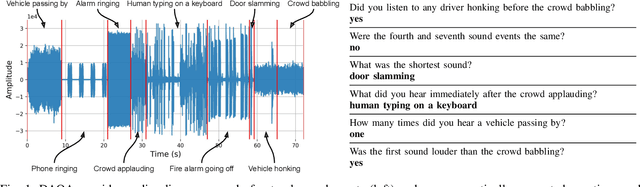
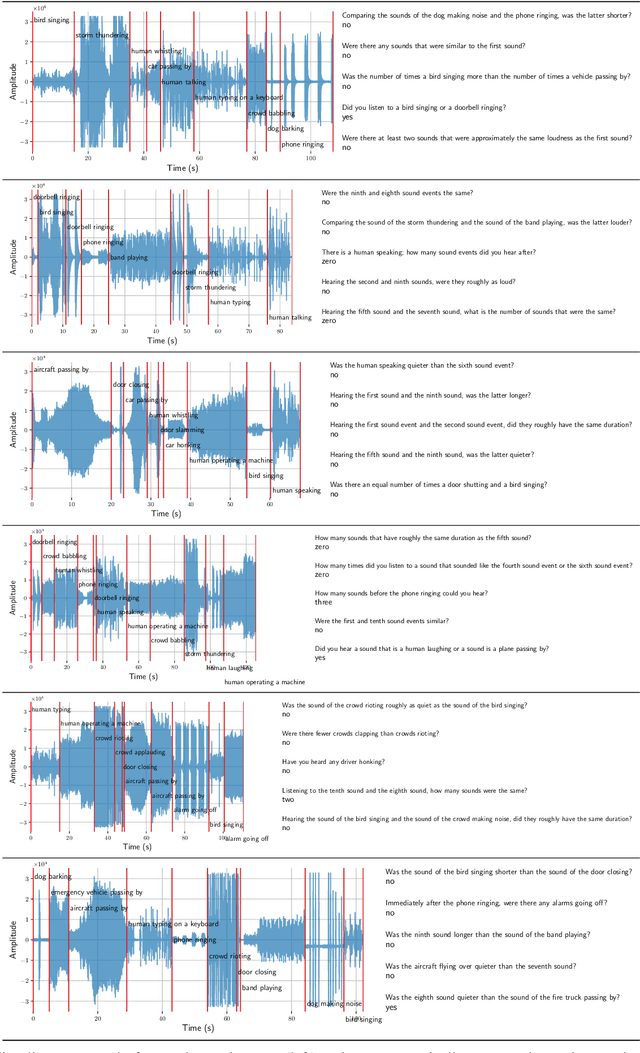
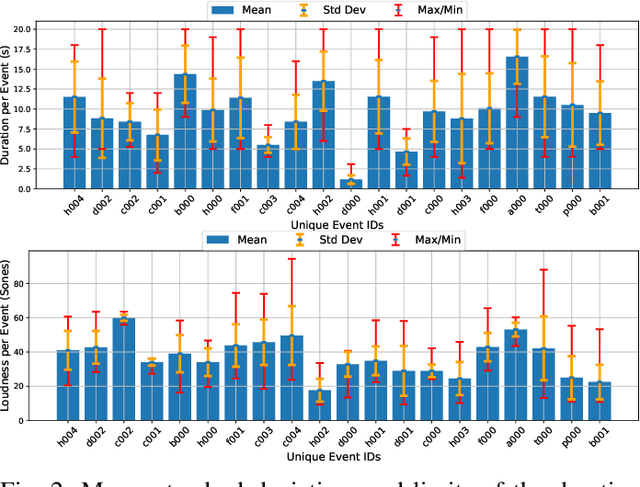
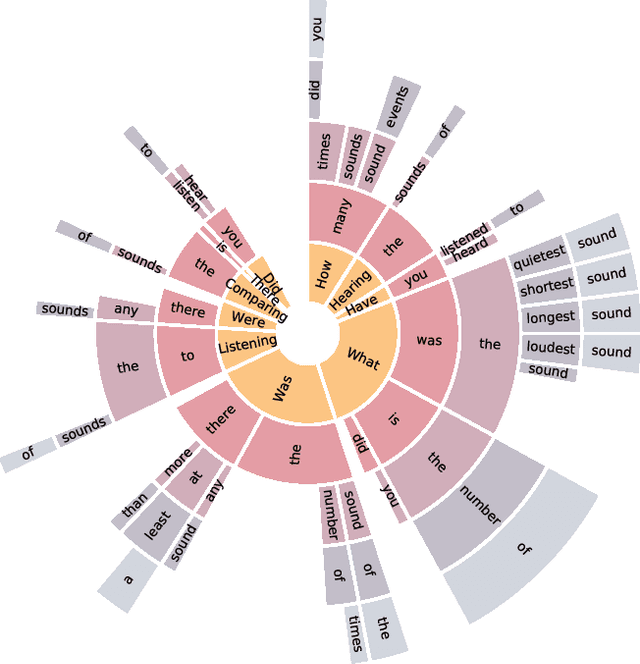
Multimodal question answering tasks can be used as proxy tasks to study systems that can perceive and reason about the world. Answering questions about different types of input modalities stresses different aspects of reasoning such as visual reasoning, reading comprehension, story understanding, or navigation. In this paper, we use the task of Audio Question Answering (AQA) to study the temporal reasoning abilities of machine learning models. To this end, we introduce the Diagnostic Audio Question Answering (DAQA) dataset comprising audio sequences of natural sound events and programmatically generated questions and answers that probe various aspects of temporal reasoning. We adapt several recent state-of-the-art methods for visual question answering to the AQA task, and use DAQA to demonstrate that they perform poorly on questions that require in-depth temporal reasoning. Finally, we propose a new model, Multiple Auxiliary Controllers for Linear Modulation (MALiMo) that extends the recent Feature-wise Linear Modulation (FiLM) model and significantly improves its temporal reasoning capabilities. We envisage DAQA to foster research on AQA and temporal reasoning and MALiMo a step towards models for AQA.
On the Transferability of Representations in Neural Networks Between Datasets and Tasks
Nov 29, 2018
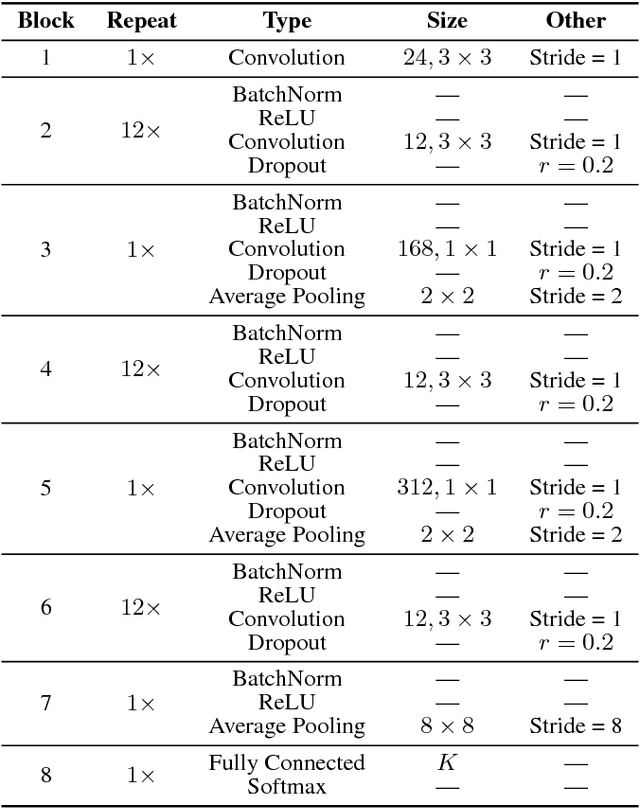
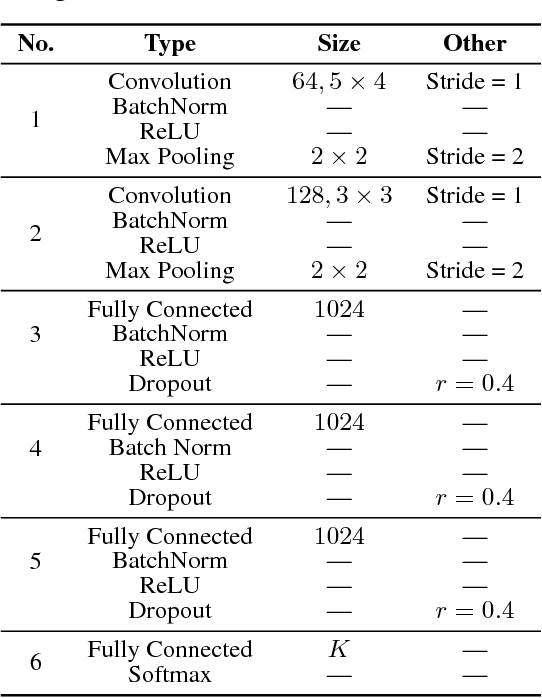

Deep networks, composed of multiple layers of hierarchical distributed representations, tend to learn low-level features in initial layers and transition to high-level features towards final layers. Paradigms such as transfer learning, multi-task learning, and continual learning leverage this notion of generic hierarchical distributed representations to share knowledge across datasets and tasks. Herein, we study the layer-wise transferability of representations in deep networks across a few datasets and tasks and note some interesting empirical observations.
* Accepted Paper in the Continual Learning Workshop, NeurIPS 2018