Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Transferability of Representations in Neural Networks Between Datasets and Tasks
Nov 29, 2018
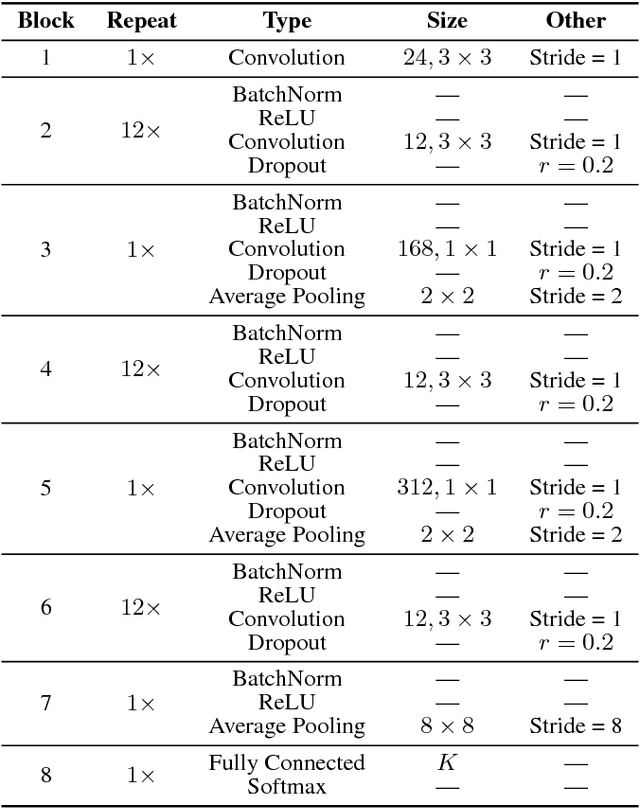
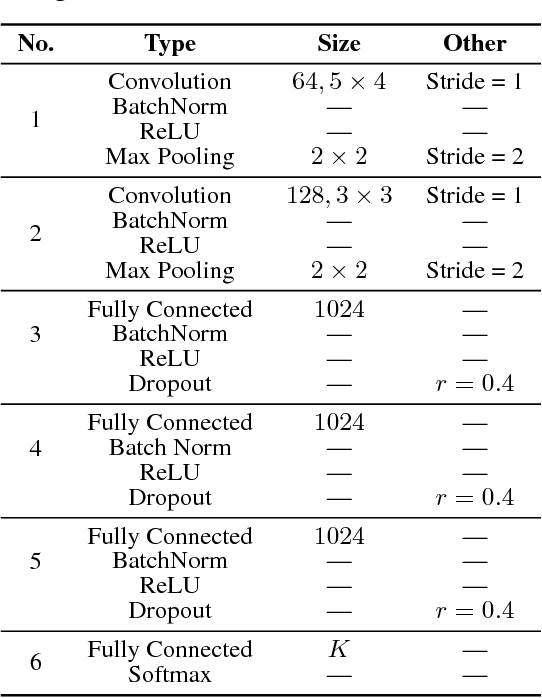

Deep networks, composed of multiple layers of hierarchical distributed representations, tend to learn low-level features in initial layers and transition to high-level features towards final layers. Paradigms such as transfer learning, multi-task learning, and continual learning leverage this notion of generic hierarchical distributed representations to share knowledge across datasets and tasks. Herein, we study the layer-wise transferability of representations in deep networks across a few datasets and tasks and note some interesting empirical observations.
* Continual Learning Workshop, 32nd Neural Information Processing
Systems (NeurIPS 2018), Montreal, Canada
* Accepted Paper in the Continual Learning Workshop, NeurIPS 2018
* Accepted Paper in the Continual Learning Workshop, NeurIPS 2018
Via