 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXMainframe: A Large Language Model for Mainframe Modernization
Aug 05, 2024



Mainframe operating systems, despite their inception in the 1940s, continue to support critical sectors like finance and government. However, these systems are often viewed as outdated, requiring extensive maintenance and modernization. Addressing this challenge necessitates innovative tools that can understand and interact with legacy codebases. To this end, we introduce XMainframe, a state-of-the-art large language model (LLM) specifically designed with knowledge of mainframe legacy systems and COBOL codebases. Our solution involves the creation of an extensive data collection pipeline to produce high-quality training datasets, enhancing XMainframe's performance in this specialized domain. Additionally, we present MainframeBench, a comprehensive benchmark for assessing mainframe knowledge, including multiple-choice questions, question answering, and COBOL code summarization. Our empirical evaluations demonstrate that XMainframe consistently outperforms existing state-of-the-art LLMs across these tasks. Specifically, XMainframe achieves 30% higher accuracy than DeepSeek-Coder on multiple-choice questions, doubles the BLEU score of Mixtral-Instruct 8x7B on question answering, and scores six times higher than GPT-3.5 on COBOL summarization. Our work highlights the potential of XMainframe to drive significant advancements in managing and modernizing legacy systems, thereby enhancing productivity and saving time for software developers.
AgileCoder: Dynamic Collaborative Agents for Software Development based on Agile Methodology
Jun 16, 2024Software agents have emerged as promising tools for addressing complex software engineering tasks. However, existing works oversimplify software development workflows by following the waterfall model. Thus, we propose AgileCoder, a multi-agent system that integrates Agile Methodology (AM) into the framework. This system assigns specific AM roles such as Product Manager, Developer, and Tester to different agents, who then collaboratively develop software based on user inputs. AgileCoder enhances development efficiency by organizing work into sprints, focusing on incrementally developing software through sprints. Additionally, we introduce Dynamic Code Graph Generator, a module that creates a Code Dependency Graph dynamically as updates are made to the codebase. This allows agents to better comprehend the codebase, leading to more precise code generation and modifications throughout the software development process. AgileCoder surpasses existing benchmarks, like ChatDev and MetaGPT, establishing a new standard and showcasing the capabilities of multi-agent systems in advanced software engineering environments. Our source code can be found at https://github.com/FSoft-AI4Code/AgileCoder.
Contextual Explainable Video Representation: Human Perception-based Understanding
Dec 17, 2022

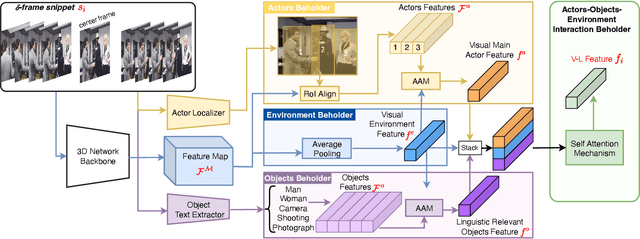

Video understanding is a growing field and a subject of intense research, which includes many interesting tasks to understanding both spatial and temporal information, e.g., action detection, action recognition, video captioning, video retrieval. One of the most challenging problems in video understanding is dealing with feature extraction, i.e. extract contextual visual representation from given untrimmed video due to the long and complicated temporal structure of unconstrained videos. Different from existing approaches, which apply a pre-trained backbone network as a black-box to extract visual representation, our approach aims to extract the most contextual information with an explainable mechanism. As we observed, humans typically perceive a video through the interactions between three main factors, i.e., the actors, the relevant objects, and the surrounding environment. Therefore, it is very crucial to design a contextual explainable video representation extraction that can capture each of such factors and model the relationships between them. In this paper, we discuss approaches, that incorporate the human perception process into modeling actors, objects, and the environment. We choose video paragraph captioning and temporal action detection to illustrate the effectiveness of human perception based-contextual representation in video understanding. Source code is publicly available at https://github.com/UARK-AICV/Video_Representation.