 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurvaDion: Curvature-Adaptive Distributed Orthonormalization
Dec 13, 2025As language models scale to trillions of parameters, distributed training across many GPUs becomes essential, yet gradient synchronization over high-bandwidth, low-latency networks remains a critical bottleneck. While recent methods like Dion reduce per-step communication through low-rank updates, they synchronize at every step regardless of the optimization landscape. We observe that synchronization requirements vary dramatically throughout training: workers naturally compute similar gradients in flat regions, making frequent synchronization redundant, while high-curvature regions require coordination to prevent divergence. We introduce CurvaDion, which uses Relative Maximum Momentum Change (RMMC) to detect high-curvature regions requiring synchronization. RMMC leverages momentum dynamics which are already computed during optimization as a computationally tractable proxy for directional curvature, adding only $\mathcal{O}(d)$ operations per layer. We establish theoretical connections between RMMC and loss curvature and demonstrate that CurvaDion achieves 99\% communication reduction while matching baseline convergence across models from 160M to 1.3B parameters.
Hermes 4 Technical Report
Aug 25, 2025We present Hermes 4, a family of hybrid reasoning models that combine structured, multi-turn reasoning with broad instruction-following ability. We describe the challenges encountered during data curation, synthesis, training, and evaluation, and outline the solutions employed to address these challenges at scale. We comprehensively evaluate across mathematical reasoning, coding, knowledge, comprehension, and alignment benchmarks, and we report both quantitative performance and qualitative behavioral analysis. To support open research, all model weights are published publicly at https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
Spectrally Transformed Kernel Regression
Feb 01, 2024Unlabeled data is a key component of modern machine learning. In general, the role of unlabeled data is to impose a form of smoothness, usually from the similarity information encoded in a base kernel, such as the $\epsilon$-neighbor kernel or the adjacency matrix of a graph. This work revisits the classical idea of spectrally transformed kernel regression (STKR), and provides a new class of general and scalable STKR estimators able to leverage unlabeled data. Intuitively, via spectral transformation, STKR exploits the data distribution for which unlabeled data can provide additional information. First, we show that STKR is a principled and general approach, by characterizing a universal type of "target smoothness", and proving that any sufficiently smooth function can be learned by STKR. Second, we provide scalable STKR implementations for the inductive setting and a general transformation function, while prior work is mostly limited to the transductive setting. Third, we derive statistical guarantees for two scenarios: STKR with a known polynomial transformation, and STKR with kernel PCA when the transformation is unknown. Overall, we believe that this work helps deepen our understanding of how to work with unlabeled data, and its generality makes it easier to inspire new methods.
Conversational Recommendation System with Unsupervised Learning
Sep 22, 2016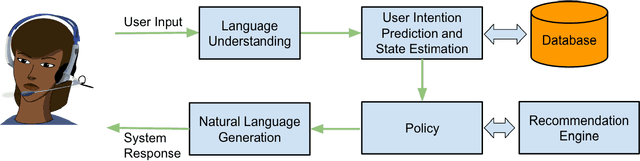

We will demonstrate a conversational products recommendation agent. This system shows how we combine research in personalized recommendation systems with research in dialogue systems to build a virtual sales agent. Based on new deep learning technologies we developed, the virtual agent is capable of learning how to interact with users, how to answer user questions, what is the next question to ask, and what to recommend when chatting with a human user. Normally a descent conversational agent for a particular domain requires tens of thousands of hand labeled conversational data or hand written rules. This is a major barrier when launching a conversation agent for a new domain. We will explore and demonstrate the effectiveness of the learning solution even when there is no hand written rules or hand labeled training data.