 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models as World Models: A Foundational Study in Text-Based GridWorlds
Sep 19, 2025



While reinforcement learning from scratch has shown impressive results in solving sequential decision-making tasks with efficient simulators, real-world applications with expensive interactions require more sample-efficient agents. Foundation models (FMs) are natural candidates to improve sample efficiency as they possess broad knowledge and reasoning capabilities, but it is yet unclear how to effectively integrate them into the reinforcement learning framework. In this paper, we anticipate and, most importantly, evaluate two promising strategies. First, we consider the use of foundation world models (FWMs) that exploit the prior knowledge of FMs to enable training and evaluating agents with simulated interactions. Second, we consider the use of foundation agents (FAs) that exploit the reasoning capabilities of FMs for decision-making. We evaluate both approaches empirically in a family of grid-world environments that are suitable for the current generation of large language models (LLMs). Our results suggest that improvements in LLMs already translate into better FWMs and FAs; that FAs based on current LLMs can already provide excellent policies for sufficiently simple environments; and that the coupling of FWMs and reinforcement learning agents is highly promising for more complex settings with partial observability and stochastic elements.
Heterogenous graph neural networks for species distribution modeling
Mar 14, 2025Species distribution models (SDMs) are necessary for measuring and predicting occurrences and habitat suitability of species and their relationship with environmental factors. We introduce a novel presence-only SDM with graph neural networks (GNN). In our model, species and locations are treated as two distinct node sets, and the learning task is predicting detection records as the edges that connect locations to species. Using GNN for SDM allows us to model fine-grained interactions between species and the environment. We evaluate the potential of this methodology on the six-region dataset compiled by National Center for Ecological Analysis and Synthesis (NCEAS) for benchmarking SDMs. For each of the regions, the heterogeneous GNN model is comparable to or outperforms previously-benchmarked single-species SDMs as well as a feed-forward neural network baseline model.
Posterior Sampling for Deep Reinforcement Learning
Apr 30, 2023Despite remarkable successes, deep reinforcement learning algorithms remain sample inefficient: they require an enormous amount of trial and error to find good policies. Model-based algorithms promise sample efficiency by building an environment model that can be used for planning. Posterior Sampling for Reinforcement Learning is such a model-based algorithm that has attracted significant interest due to its performance in the tabular setting. This paper introduces Posterior Sampling for Deep Reinforcement Learning (PSDRL), the first truly scalable approximation of Posterior Sampling for Reinforcement Learning that retains its model-based essence. PSDRL combines efficient uncertainty quantification over latent state space models with a specially tailored continual planning algorithm based on value-function approximation. Extensive experiments on the Atari benchmark show that PSDRL significantly outperforms previous state-of-the-art attempts at scaling up posterior sampling while being competitive with a state-of-the-art (model-based) reinforcement learning method, both in sample efficiency and computational efficiency.
Hardness in Markov Decision Processes: Theory and Practice
Oct 24, 2022



Meticulously analysing the empirical strengths and weaknesses of reinforcement learning methods in hard (challenging) environments is essential to inspire innovations and assess progress in the field. In tabular reinforcement learning, there is no well-established standard selection of environments to conduct such analysis, which is partially due to the lack of a widespread understanding of the rich theory of hardness of environments. The goal of this paper is to unlock the practical usefulness of this theory through four main contributions. First, we present a systematic survey of the theory of hardness, which also identifies promising research directions. Second, we introduce Colosseum, a pioneering package that enables empirical hardness analysis and implements a principled benchmark composed of environments that are diverse with respect to different measures of hardness. Third, we present an empirical analysis that provides new insights into computable measures. Finally, we benchmark five tabular agents in our newly proposed benchmark. While advancing the theoretical understanding of hardness in non-tabular reinforcement learning remains essential, our contributions in the tabular setting are intended as solid steps towards a principled non-tabular benchmark. Accordingly, we benchmark four agents in non-tabular versions of Colosseum environments, obtaining results that demonstrate the generality of tabular hardness measures.
Submodular Kernels for Efficient Rankings
May 26, 2021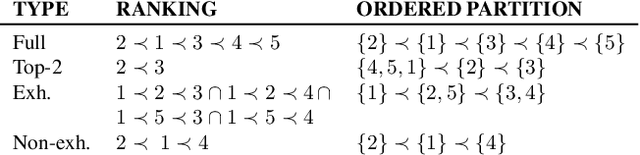
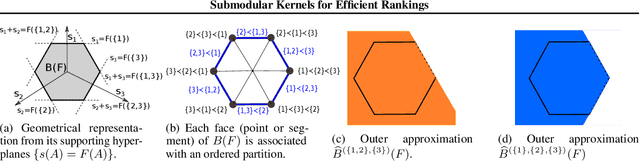
Many algorithms for ranked data become computationally intractable as the number of objects grows due to complex geometric structure induced by rankings. An additional challenge is posed by partial rankings, i.e. rankings in which the preference is only known for a subset of all objects. For these reasons, state-of-the-art methods cannot scale to real-world applications, such as recommender systems. We address this challenge by exploiting geometric structure of ranked data and additional available information about the objects to derive a submodular kernel for ranking. The submodular kernel combines the efficiency of submodular optimization with the theoretical properties of kernel-based methods. We demonstrate that the submodular kernel drastically reduces the computational cost compared to state-of-the-art kernels and scales well to large datasets while attaining good empirical performance.