 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Lifelong Learning of Representations
Paper and Code
Oct 27, 2021
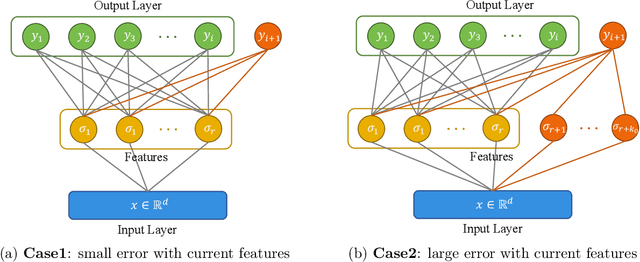
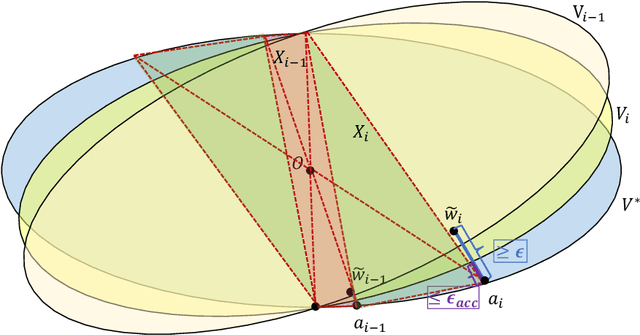
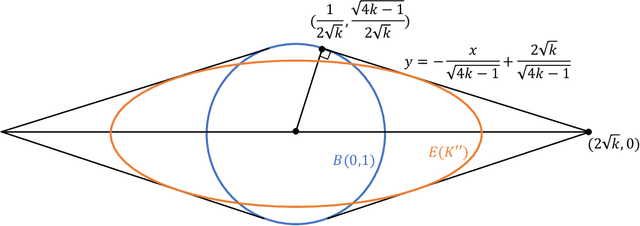
In lifelong learning, the tasks (or classes) to be learned arrive sequentially over time in arbitrary order. During training, knowledge from previous tasks can be captured and transferred to subsequent ones to improve sample efficiency. We consider the setting where all target tasks can be represented in the span of a small number of unknown linear or nonlinear features of the input data. We propose a provable lifelong learning algorithm that maintains and refines the internal feature representation. We prove that for any desired accuracy on all tasks, the dimension of the representation remains close to that of the underlying representation. The resulting sample complexity improves significantly on existing bounds. In the setting of linear features, our algorithm is provably efficient and the sample complexity for input dimension $d$, $m$ tasks with $k$ features up to error $\epsilon$ is $\tilde{O}(dk^{1.5}/\epsilon+km/\epsilon)$. We also prove a matching lower bound for any lifelong learning algorithm that uses a single task learner as a black box. Finally, we complement our analysis with an empirical study.