 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGaze: Autoregressive Transformers for Online Egocentric Gaze Estimation
Feb 04, 2026Online egocentric gaze estimation predicts where a camera wearer is looking from first-person video using only past and current frames, a task essential for augmented reality and assistive technologies. Unlike third-person gaze estimation, this setting lacks explicit head or eye signals, requiring models to infer current visual attention from sparse, indirect cues such as hand-object interactions and salient scene content. We observe that gaze exhibits strong temporal continuity during goal-directed activities: knowing where a person looked recently provides a powerful prior for predicting where they look next. Inspired by vision-conditioned autoregressive decoding in vision-language models, we propose ARGaze, which reformulates gaze estimation as sequential prediction: at each timestep, a transformer decoder predicts current gaze by conditioning on (i) current visual features and (ii) a fixed-length Gaze Context Window of recent gaze target estimates. This design enforces causality and enables bounded-resource streaming inference. We achieve state-of-the-art performance across multiple egocentric benchmarks under online evaluation, with extensive ablations validating that autoregressive modeling with bounded gaze history is critical for robust prediction. We will release our source code and pre-trained models.
AI-Driven Prediction of Cancer Pain Episodes: A Hybrid Decision Support Approach
Dec 18, 2025Lung cancer patients frequently experience breakthrough pain episodes, with up to 91% requiring timely intervention. To enable proactive pain management, we propose a hybrid machine learning and large language model pipeline that predicts pain episodes within 48 and 72 hours of hospitalization using both structured and unstructured electronic health record data. A retrospective cohort of 266 inpatients was analyzed, with features including demographics, tumor stage, vital signs, and WHO-tiered analgesic use. The machine learning module captured temporal medication trends, while the large language model interpreted ambiguous dosing records and free-text clinical notes. Integrating these modalities improved sensitivity and interpretability. Our framework achieved an accuracy of 0.874 (48h) and 0.917 (72h), with an improvement in sensitivity of 8.6% and 10.4% due to the augmentation of large language model. This hybrid approach offers a clinically interpretable and scalable tool for early pain episode forecasting, with potential to enhance treatment precision and optimize resource allocation in oncology care.
P3-LLM: An Integrated NPU-PIM Accelerator for LLM Inference Using Hybrid Numerical Formats
Nov 16, 2025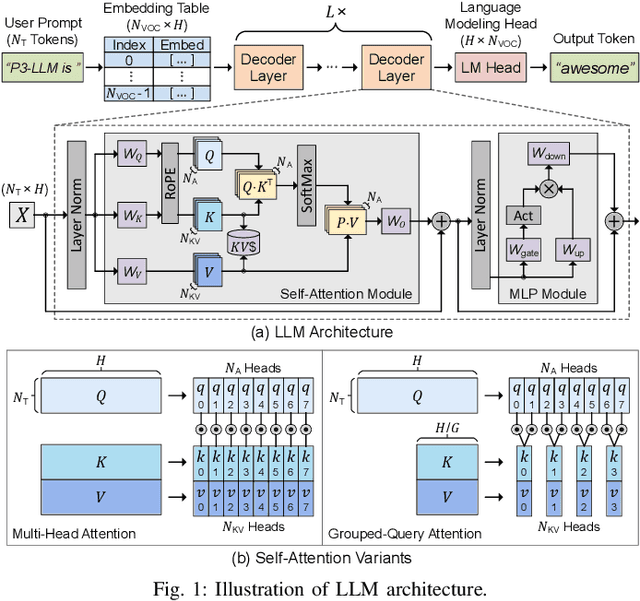
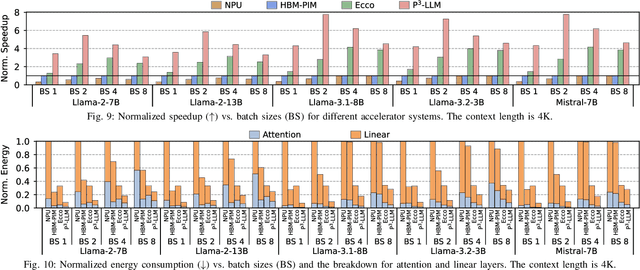
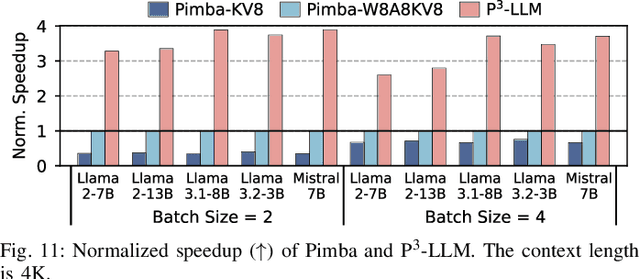
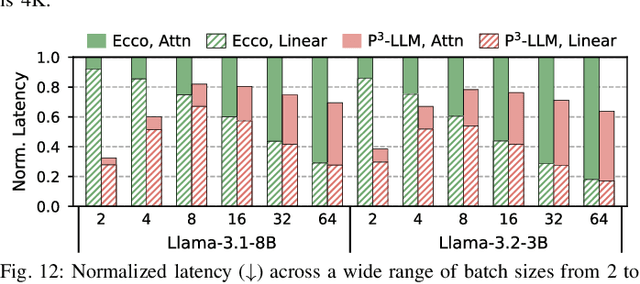
The substantial memory bandwidth and computational demands of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, existing high-precision (e.g., FP16) PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for LLM inference using hybrid numerical formats. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator for P3-LLM, featuring enhanced compute units to support hybrid numerical formats. Our careful choice of numerical formats allows to co-design low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Evaluation on a diverse set of representative LLMs and tasks demonstrates that P3-LLM achieves state-of-the-art accuracy in terms of both KV-cache quantization and weight-activation quantization. Combining the proposed quantization scheme with PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over the state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Our quantization code is available at https://github.com/yc2367/P3-LLM.git
Background Fades, Foreground Leads: Curriculum-Guided Background Pruning for Efficient Foreground-Centric Collaborative Perception
Oct 22, 2025Collaborative perception enhances the reliability and spatial coverage of autonomous vehicles by sharing complementary information across vehicles, offering a promising solution to long-tail scenarios that challenge single-vehicle perception. However, the bandwidth constraints of vehicular networks make transmitting the entire feature map impractical. Recent methods, therefore, adopt a foreground-centric paradigm, transmitting only predicted foreground-region features while discarding the background, which encodes essential context. We propose FadeLead, a foreground-centric framework that overcomes this limitation by learning to encapsulate background context into compact foreground features during training. At the core of our design is a curricular learning strategy that leverages background cues early on but progressively prunes them away, forcing the model to internalize context into foreground representations without transmitting background itself. Extensive experiments on both simulated and real-world benchmarks show that FadeLead outperforms prior methods under different bandwidth settings, underscoring the effectiveness of context-enriched foreground sharing.
AirV2X: Unified Air-Ground Vehicle-to-Everything Collaboration
Jun 24, 2025While multi-vehicular collaborative driving demonstrates clear advantages over single-vehicle autonomy, traditional infrastructure-based V2X systems remain constrained by substantial deployment costs and the creation of "uncovered danger zones" in rural and suburban areas. We present AirV2X-Perception, a large-scale dataset that leverages Unmanned Aerial Vehicles (UAVs) as a flexible alternative or complement to fixed Road-Side Units (RSUs). Drones offer unique advantages over ground-based perception: complementary bird's-eye-views that reduce occlusions, dynamic positioning capabilities that enable hovering, patrolling, and escorting navigation rules, and significantly lower deployment costs compared to fixed infrastructure. Our dataset comprises 6.73 hours of drone-assisted driving scenarios across urban, suburban, and rural environments with varied weather and lighting conditions. The AirV2X-Perception dataset facilitates the development and standardized evaluation of Vehicle-to-Drone (V2D) algorithms, addressing a critical gap in the rapidly expanding field of aerial-assisted autonomous driving systems. The dataset and development kits are open-sourced at https://github.com/taco-group/AirV2X-Perception.
DEL-ToM: Inference-Time Scaling for Theory-of-Mind Reasoning via Dynamic Epistemic Logic
May 22, 2025Theory-of-Mind (ToM) tasks pose a unique challenge for small language models (SLMs) with limited scale, which often lack the capacity to perform deep social reasoning. In this work, we propose DEL-ToM, a framework that improves ToM reasoning through inference-time scaling rather than architectural changes. Our approach decomposes ToM tasks into a sequence of belief updates grounded in Dynamic Epistemic Logic (DEL), enabling structured and transparent reasoning. We train a verifier, called the Process Belief Model (PBM), to score each belief update step using labels generated automatically via a DEL simulator. During inference, candidate belief traces generated by a language model are evaluated by the PBM, and the highest-scoring trace is selected. This allows SLMs to emulate more deliberate reasoning by allocating additional compute at test time. Experiments across multiple model scales and benchmarks show that DEL-ToM consistently improves performance, demonstrating that verifiable belief supervision can significantly enhance ToM abilities of SLMs without retraining.
SATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
May 20, 2025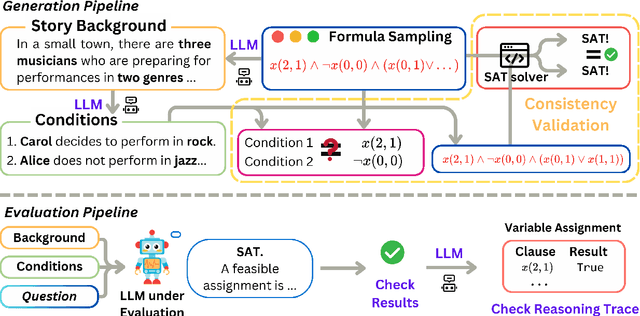



We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
LangCoop: Collaborative Driving with Language
Apr 21, 2025



Multi-agent collaboration holds great promise for enhancing the safety, reliability, and mobility of autonomous driving systems by enabling information sharing among multiple connected agents. However, existing multi-agent communication approaches are hindered by limitations of existing communication media, including high bandwidth demands, agent heterogeneity, and information loss. To address these challenges, we introduce LangCoop, a new paradigm for collaborative autonomous driving that leverages natural language as a compact yet expressive medium for inter-agent communication. LangCoop features two key innovations: Mixture Model Modular Chain-of-thought (M$^3$CoT) for structured zero-shot vision-language reasoning and Natural Language Information Packaging (LangPack) for efficiently packaging information into concise, language-based messages. Through extensive experiments conducted in the CARLA simulations, we demonstrate that LangCoop achieves a remarkable 96\% reduction in communication bandwidth (< 2KB per message) compared to image-based communication, while maintaining competitive driving performance in the closed-loop evaluation. Our project page and code are at https://xiangbogaobarry.github.io/LangCoop/.
Sensitivity Meets Sparsity: The Impact of Extremely Sparse Parameter Patterns on Theory-of-Mind of Large Language Models
Apr 05, 2025



This paper investigates the emergence of Theory-of-Mind (ToM) capabilities in large language models (LLMs) from a mechanistic perspective, focusing on the role of extremely sparse parameter patterns. We introduce a novel method to identify ToM-sensitive parameters and reveal that perturbing as little as 0.001% of these parameters significantly degrades ToM performance while also impairing contextual localization and language understanding. To understand this effect, we analyze their interaction with core architectural components of LLMs. Our findings demonstrate that these sensitive parameters are closely linked to the positional encoding module, particularly in models using Rotary Position Embedding (RoPE), where perturbations disrupt dominant-frequency activations critical for contextual processing. Furthermore, we show that perturbing ToM-sensitive parameters affects LLM's attention mechanism by modulating the angle between queries and keys under positional encoding. These insights provide a deeper understanding of how LLMs acquire social reasoning abilities, bridging AI interpretability with cognitive science. Our results have implications for enhancing model alignment, mitigating biases, and improving AI systems designed for human interaction.
CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis
Mar 29, 2025Inductive program synthesis, or programming by example, requires synthesizing functions from input-output examples that generalize to unseen inputs. While large language model agents have shown promise in programming tasks guided by natural language, their ability to perform inductive program synthesis is underexplored. Existing evaluation protocols rely on static sets of examples and held-out tests, offering no feedback when synthesized functions are incorrect and failing to reflect real-world scenarios such as reverse engineering. We propose CodeARC, the Code Abstraction and Reasoning Challenge, a new evaluation framework where agents interact with a hidden target function by querying it with new inputs, synthesizing candidate functions, and iteratively refining their solutions using a differential testing oracle. This interactive setting encourages agents to perform function calls and self-correction based on feedback. We construct the first large-scale benchmark for general-purpose inductive program synthesis, featuring 1114 functions. Among 18 models evaluated, o3-mini performs best with a success rate of 52.7%, highlighting the difficulty of this task. Fine-tuning LLaMA-3.1-8B-Instruct on curated synthesis traces yields up to a 31% relative performance gain. CodeARC provides a more realistic and challenging testbed for evaluating LLM-based program synthesis and inductive reasoning.