 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference
Dec 18, 2025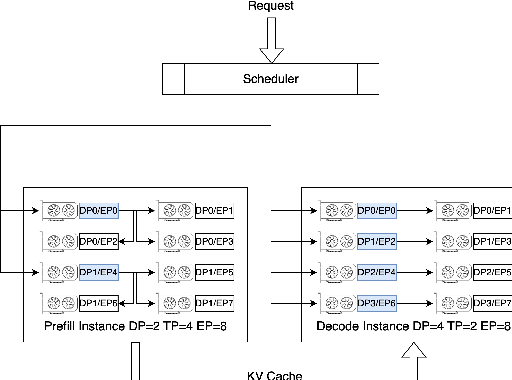
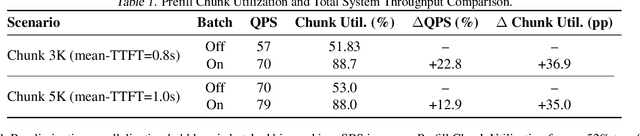
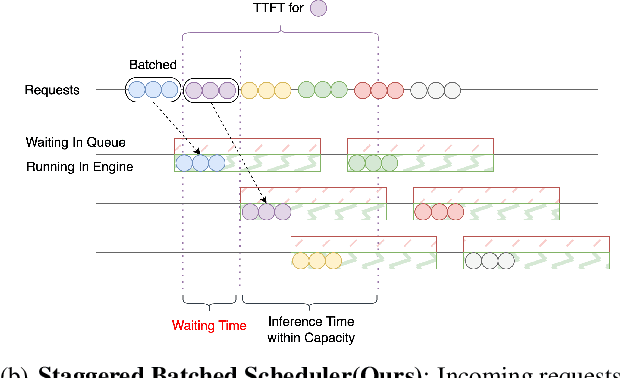
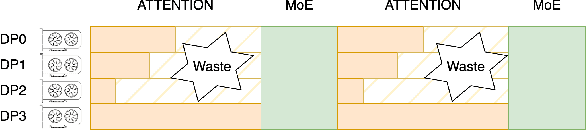
The evolution of Large Language Model (LLM) serving towards complex, distributed architectures--specifically the P/D-separated, large-scale DP+EP paradigm--introduces distinct scheduling challenges. Unlike traditional deployments where schedulers can treat instances as black boxes, DP+EP architectures exhibit high internal synchronization costs. We identify that immediate request dispatching in such systems leads to severe in-engine queuing and parallelization bubbles, degrading Time-to-First-Token (TTFT). To address this, we propose Staggered Batch Scheduling (SBS), a mechanism that deliberately buffers requests to form optimal execution batches. This temporal decoupling eliminates internal queuing bubbles without compromising throughput. Furthermore, leveraging the scheduling window created by buffering, we introduce a Load-Aware Global Allocation strategy that balances computational load across DP units for both Prefill and Decode phases. Deployed on a production H800 cluster serving Deepseek-V3, our system reduces TTFT by 30%-40% and improves throughput by 15%-20% compared to state-of-the-art immediate scheduling baselines.
CPMamba: Selective State Space Models for MIMO Channel Prediction in High-Mobility Environments
Dec 18, 2025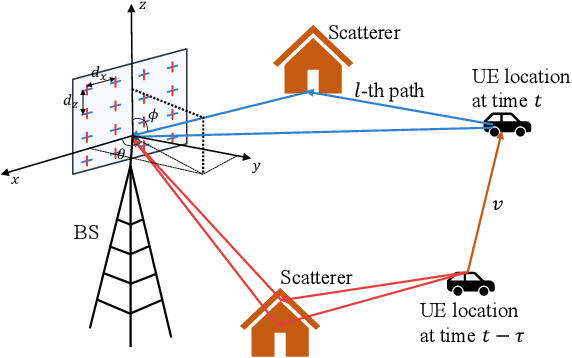
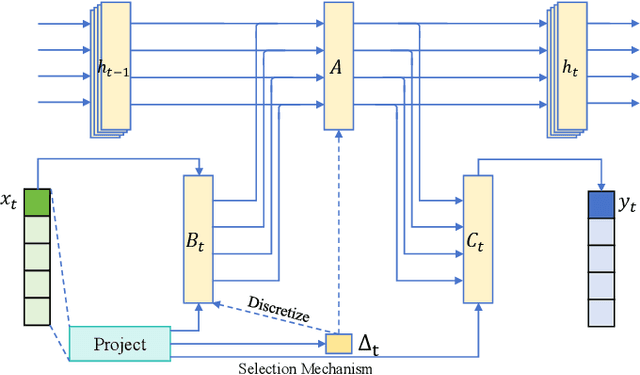
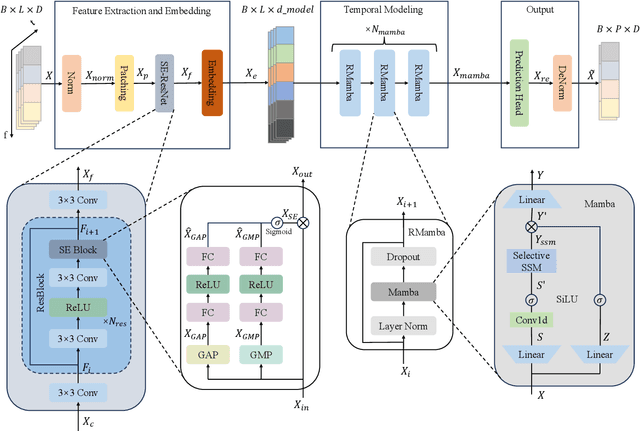
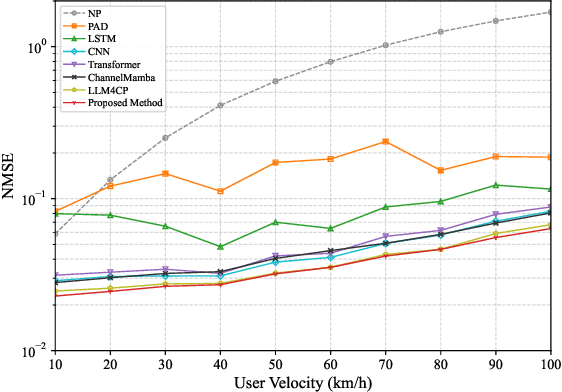
Channel prediction is a key technology for improving the performance of various functions such as precoding, adaptive modulation, and resource allocation in MIMO-OFDM systems. Especially in high-mobility scenarios with fast time-varying channels, it is crucial for resisting channel aging and ensuring communication quality. However, existing methods suffer from high complexity and the inability to accurately model the temporal variations of channels. To address this issue, this paper proposes CPMamba -- an efficient channel prediction framework based on the selective state space model. The proposed CPMamba architecture extracts features from historical channel state information (CSI) using a specifically designed feature extraction and embedding network and employs stacked residual Mamba modules for temporal modeling. By leveraging an input-dependent selective mechanism to dynamically adjust state transitions, it can effectively capture the long-range dependencies between the CSIs while maintaining a linear computational complexity. Simulation results under the 3GPP standard channel model demonstrate that CPMamba achieves state-of-the-art prediction accuracy across all scenarios, along with superior generalization and robustness. Compared to existing baseline models, CPMamba reduces the number of parameters by approximately 50 percent while achieving comparable or better performance, thereby significantly lowering the barrier for practical deployment.
Unbiased Evaluation of Large Language Models from a Causal Perspective
Feb 10, 2025



Benchmark contamination has become a significant concern in the LLM evaluation community. Previous Agents-as-an-Evaluator address this issue by involving agents in the generation of questions. Despite their success, the biases in Agents-as-an-Evaluator methods remain largely unexplored. In this paper, we present a theoretical formulation of evaluation bias, providing valuable insights into designing unbiased evaluation protocols. Furthermore, we identify two type of bias in Agents-as-an-Evaluator through carefully designed probing tasks on a minimal Agents-as-an-Evaluator setup. To address these issues, we propose the Unbiased Evaluator, an evaluation protocol that delivers a more comprehensive, unbiased, and interpretable assessment of LLMs.Extensive experiments reveal significant room for improvement in current LLMs. Additionally, we demonstrate that the Unbiased Evaluator not only offers strong evidence of benchmark contamination but also provides interpretable evaluation results.
MGH: Metadata Guided Hypergraph Modeling for Unsupervised Person Re-identification
Oct 12, 2021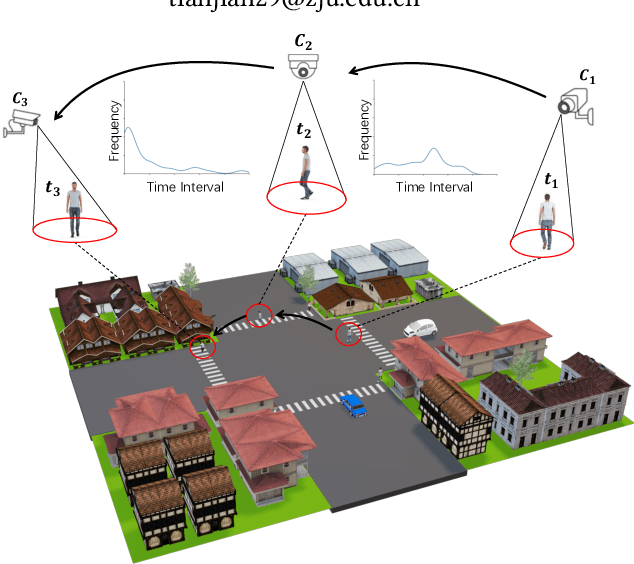

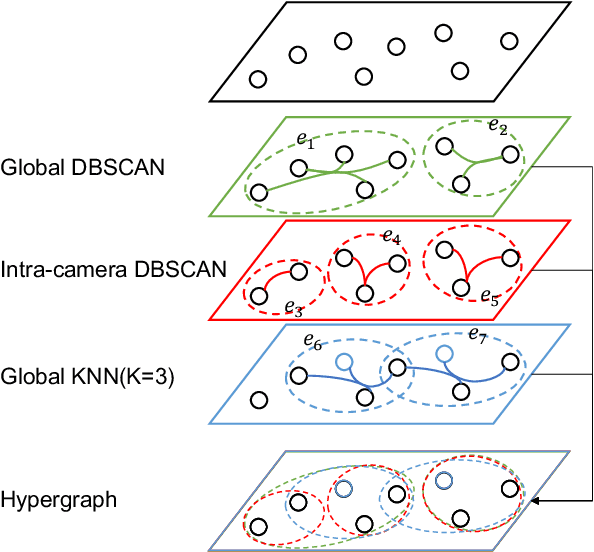
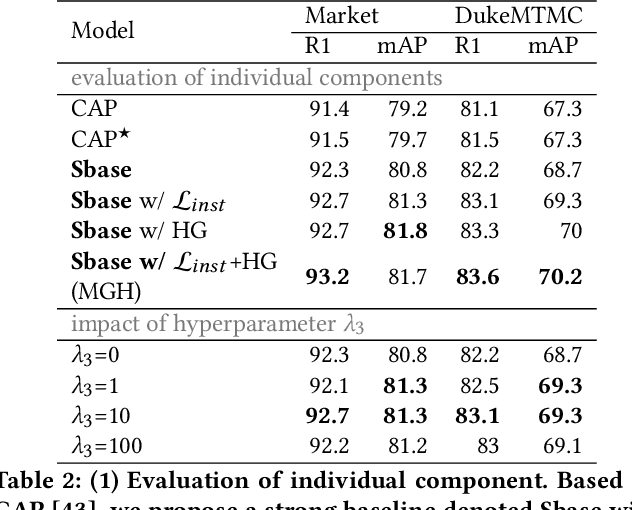
As a challenging task, unsupervised person ReID aims to match the same identity with query images which does not require any labeled information. In general, most existing approaches focus on the visual cues only, leaving potentially valuable auxiliary metadata information (e.g., spatio-temporal context) unexplored. In the real world, such metadata is normally available alongside captured images, and thus plays an important role in separating several hard ReID matches. With this motivation in mind, we propose~\textbf{MGH}, a novel unsupervised person ReID approach that uses meta information to construct a hypergraph for feature learning and label refinement. In principle, the hypergraph is composed of camera-topology-aware hyperedges, which can model the heterogeneous data correlations across cameras. Taking advantage of label propagation on the hypergraph, the proposed approach is able to effectively refine the ReID results, such as correcting the wrong labels or smoothing the noisy labels. Given the refined results, We further present a memory-based listwise loss to directly optimize the average precision in an approximate manner. Extensive experiments on three benchmarks demonstrate the effectiveness of the proposed approach against the state-of-the-art.
Unsupervised Domain Adaptation for Image Classification via Structure-Conditioned Adversarial Learning
Mar 04, 2021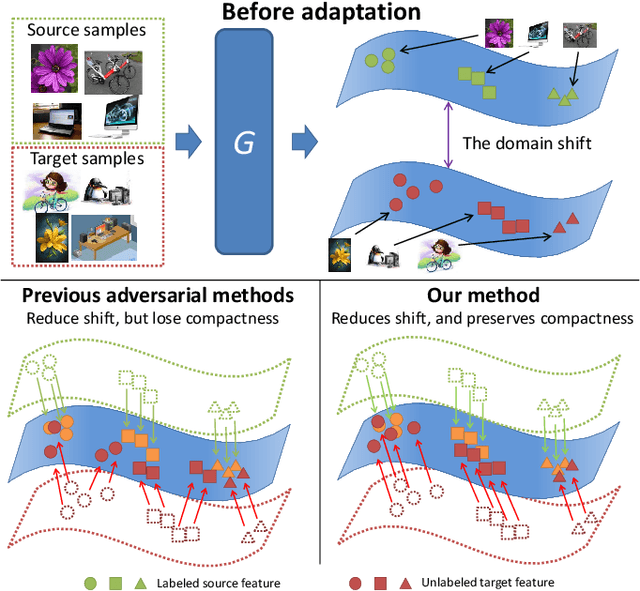
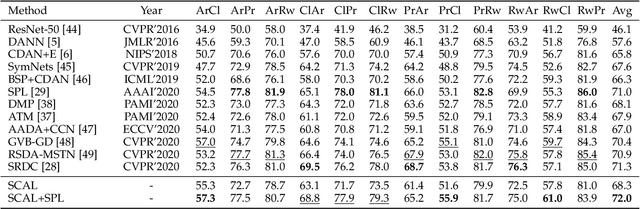
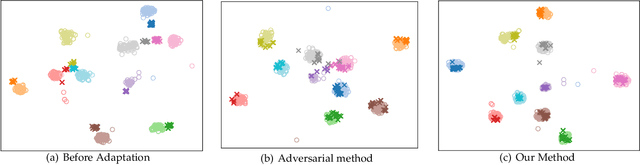
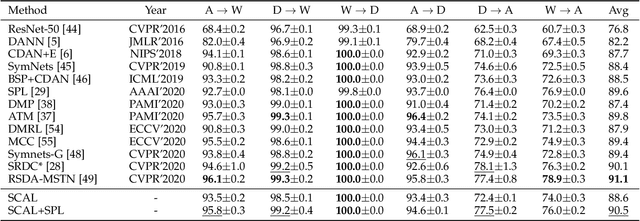
Unsupervised domain adaptation (UDA) typically carries out knowledge transfer from a label-rich source domain to an unlabeled target domain by adversarial learning. In principle, existing UDA approaches mainly focus on the global distribution alignment between domains while ignoring the intrinsic local distribution properties. Motivated by this observation, we propose an end-to-end structure-conditioned adversarial learning scheme (SCAL) that is able to preserve the intra-class compactness during domain distribution alignment. By using local structures as structure-aware conditions, the proposed scheme is implemented in a structure-conditioned adversarial learning pipeline. The above learning procedure is iteratively performed by alternating between local structures establishment and structure-conditioned adversarial learning. Experimental results demonstrate the effectiveness of the proposed scheme in UDA scenarios.
Multitask Non-Autoregressive Model for Human Motion Prediction
Jul 13, 2020

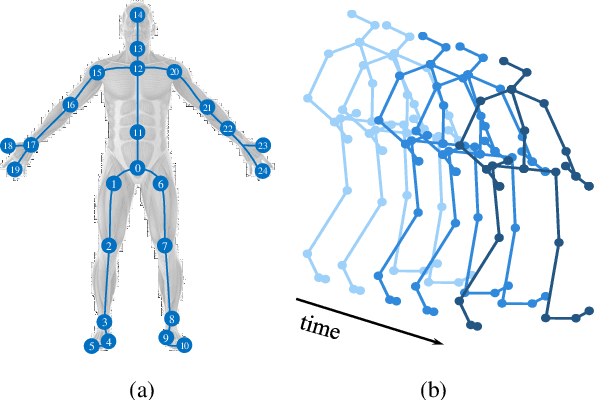
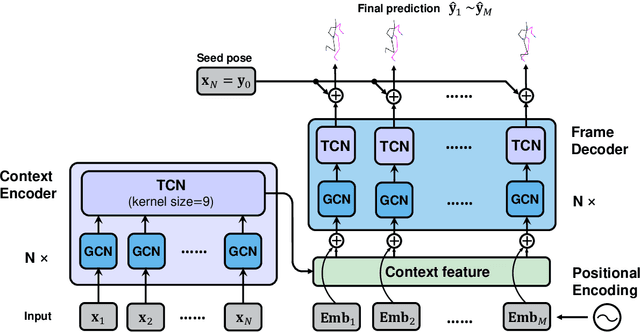
Human motion prediction, which aims at predicting future human skeletons given the past ones, is a typical sequence-to-sequence problem. Therefore, extensive efforts have been continued on exploring different RNN-based encoder-decoder architectures. However, by generating target poses conditioned on the previously generated ones, these models are prone to bringing issues such as error accumulation problem. In this paper, we argue that such issue is mainly caused by adopting autoregressive manner. Hence, a novel Non-auToregressive Model (NAT) is proposed with a complete non-autoregressive decoding scheme, as well as a context encoder and a positional encoding module. More specifically, the context encoder embeds the given poses from temporal and spatial perspectives. The frame decoder is responsible for predicting each future pose independently. The positional encoding module injects positional signal into the model to indicate temporal order. Moreover, a multitask training paradigm is presented for both low-level human skeleton prediction and high-level human action recognition, resulting in the convincing improvement for the prediction task. Our approach is evaluated on Human3.6M and CMU-Mocap benchmarks and outperforms state-of-the-art autoregressive methods.