 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflection Generation for Composite Image Using Diffusion Model
Apr 02, 2026Image composition involves inserting a foreground object into the background while synthesizing environment-consistent effects such as shadows and reflections. Although shadow generation has been extensively studied, reflection generation remains largely underexplored. In this work, we focus on reflection generation. We inject the prior information of reflection placement and reflection appearance into foundation diffusion model. We also divide reflections into two types and adopt type-aware model design. To support training, we construct the first large-scale object reflection dataset DEROBA. Experiments demonstrate that our method generates reflections that are physically coherent and visually realistic, establishing a new benchmark for reflection generation.
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Nov 17, 2025The rapid evolution of video generative models has shifted their focus from producing visually plausible outputs to tackling tasks requiring physical plausibility and logical consistency. However, despite recent breakthroughs such as Veo 3's chain-of-frames reasoning, it remains unclear whether these models can exhibit reasoning capabilities similar to large language models (LLMs). Existing benchmarks predominantly evaluate visual fidelity and temporal coherence, failing to capture higher-order reasoning abilities. To bridge this gap, we propose TiViBench, a hierarchical benchmark specifically designed to evaluate the reasoning capabilities of image-to-video (I2V) generation models. TiViBench systematically assesses reasoning across four dimensions: i) Structural Reasoning & Search, ii) Spatial & Visual Pattern Reasoning, iii) Symbolic & Logical Reasoning, and iv) Action Planning & Task Execution, spanning 24 diverse task scenarios across 3 difficulty levels. Through extensive evaluations, we show that commercial models (e.g., Sora 2, Veo 3.1) demonstrate stronger reasoning potential, while open-source models reveal untapped potential that remains hindered by limited training scale and data diversity. To further unlock this potential, we introduce VideoTPO, a simple yet effective test-time strategy inspired by preference optimization. By performing LLM self-analysis on generated candidates to identify strengths and weaknesses, VideoTPO significantly enhances reasoning performance without requiring additional training, data, or reward models. Together, TiViBench and VideoTPO pave the way for evaluating and advancing reasoning in video generation models, setting a foundation for future research in this emerging field.
D$^{3}$ToM: Decider-Guided Dynamic Token Merging for Accelerating Diffusion MLLMs
Nov 15, 2025Diffusion-based multimodal large language models (Diffusion MLLMs) have recently demonstrated impressive non-autoregressive generative capabilities across vision-and-language tasks. However, Diffusion MLLMs exhibit substantially slower inference than autoregressive models: Each denoising step employs full bidirectional self-attention over the entire sequence, resulting in cubic decoding complexity that becomes computationally impractical with thousands of visual tokens. To address this challenge, we propose D$^{3}$ToM, a Decider-guided dynamic token merging method that dynamically merges redundant visual tokens at different denoising steps to accelerate inference in Diffusion MLLMs. At each denoising step, D$^{3}$ToM uses decider tokens-the tokens generated in the previous denoising step-to build an importance map over all visual tokens. Then it maintains a proportion of the most salient tokens and merges the remainder through similarity-based aggregation. This plug-and-play module integrates into a single transformer layer, physically shortening the visual token sequence for all subsequent layers without altering model parameters. Moreover, D$^{3}$ToM employs a merge ratio that dynamically varies with each denoising step, aligns with the native decoding process of Diffusion MLLMs, achieving superior performance under equivalent computational budgets. Extensive experiments show that D$^{3}$ToM accelerates inference while preserving competitive performance. The code is released at https://github.com/bcmi/D3ToM-Diffusion-MLLM.
The Telephone Game: Evaluating Semantic Drift in Unified Models
Sep 04, 2025Employing a single, unified model (UM) for both visual understanding (image-to-text: I2T) and and visual generation (text-to-image: T2I) has opened a new direction in Visual Language Model (VLM) research. While UMs can also support broader unimodal tasks (e.g., text-to-text, image-to-image), we focus on the core cross-modal pair T2I and I2T, as consistency between understanding and generation is critical for downstream use. Existing evaluations consider these capabilities in isolation: FID and GenEval for T2I, and benchmarks such as MME, MMBench for I2T. These single-pass metrics do not reveal whether a model that understands a concept can also render it, nor whether meaning is preserved when cycling between image and text modalities. To address this, we introduce the Unified Consistency Framework for Unified Models (UCF-UM), a cyclic evaluation protocol that alternates I2T and T2I over multiple generations to quantify semantic drift. UCF formulates 3 metrics: (i) Mean Cumulative Drift (MCD), an embedding-based measure of overall semantic loss; (ii) Semantic Drift Rate (SDR), that summarizes semantic decay rate; and (iii) Multi-Generation GenEval (MGG), an object-level compliance score extending GenEval. To assess generalization beyond COCO, which is widely used in training; we create a new benchmark ND400, sampled from NoCaps and DOCCI and evaluate on seven recent models. UCF-UM reveals substantial variation in cross-modal stability: some models like BAGEL maintain semantics over many alternations, whereas others like Vila-u drift quickly despite strong single-pass scores. Our results highlight cyclic consistency as a necessary complement to standard I2T and T2I evaluations, and provide practical metrics to consistently assess unified model's cross-modal stability and strength of their shared representations. Code: https://github.com/mollahsabbir/Semantic-Drift-in-Unified-Models
A Robust Monotonic Single-Index Model for Skewed and Heavy-Tailed Data: A Deep Neural Network Approach Applied to Periodontal Studies
May 04, 2025Periodontal pocket depth is a widely used biomarker for diagnosing risk of periodontal disease. However, pocket depth typically exhibits skewness and heavy-tailedness, and its relationship with clinical risk factors is often nonlinear. Motivated by periodontal studies, this paper develops a robust single-index modal regression framework for analyzing skewed and heavy-tailed data. Our method has the following novel features: (1) a flexible two-piece scale Student-$t$ error distribution that generalizes both normal and two-piece scale normal distributions; (2) a deep neural network with guaranteed monotonicity constraints to estimate the unknown single-index function; and (3) theoretical guarantees, including model identifiability and a universal approximation theorem. Our single-index model combines the flexibility of neural networks and the two-piece scale Student-$t$ distribution, delivering robust mode-based estimation that is resistant to outliers, while retaining clinical interpretability through parametric index coefficients. We demonstrate the performance of our method through simulation studies and an application to periodontal disease data from the HealthPartners Institute of Minnesota. The proposed methodology is implemented in the \textsf{R} package \href{https://doi.org/10.32614/CRAN.package.DNNSIM}{\textsc{DNNSIM}}.
TiM4Rec: An Efficient Sequential Recommendation Model Based on Time-Aware Structured State Space Duality Model
Sep 24, 2024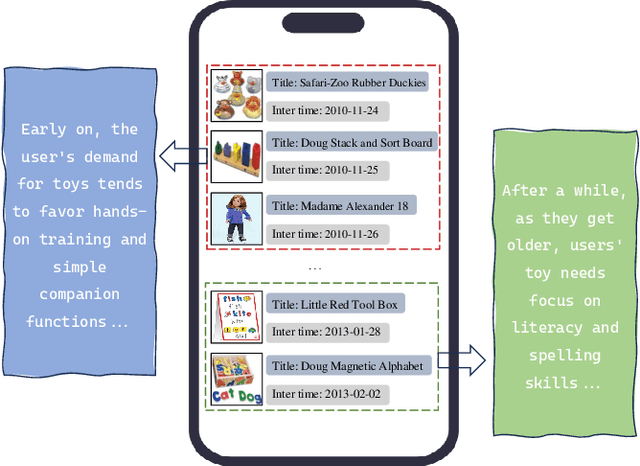
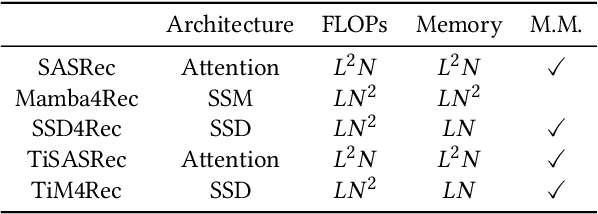
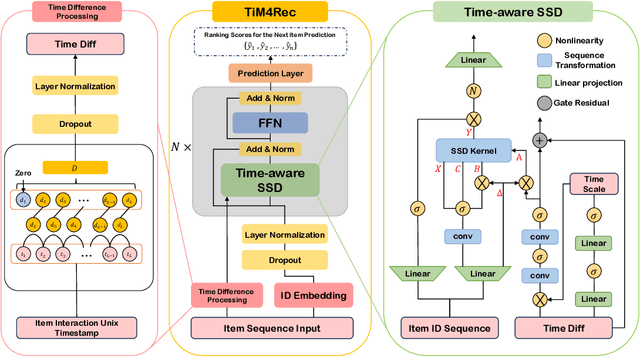
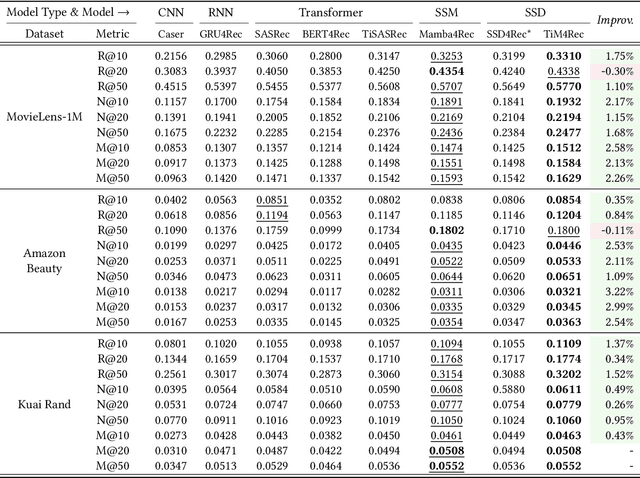
Sequential recommendation represents a pivotal branch of recommendation systems, centered around dynamically analyzing the sequential dependencies between user preferences and their interactive behaviors. Despite the Transformer architecture-based models achieving commendable performance within this domain, their quadratic computational complexity relative to the sequence dimension impedes efficient modeling. In response, the innovative Mamba architecture, characterized by linear computational complexity, has emerged. Mamba4Rec further pioneers the application of Mamba in sequential recommendation. Nonetheless, Mamba 1's hardware-aware algorithm struggles to efficiently leverage modern matrix computational units, which lead to the proposal of the improved State Space Duality (SSD), also known as Mamba 2. While the SSD4Rec successfully adapts the SSD architecture for sequential recommendation, showing promising results in high-dimensional contexts, it suffers significant performance drops in low-dimensional scenarios crucial for pure ID sequential recommendation tasks. Addressing this challenge, we propose a novel sequential recommendation backbone model, TiM4Rec, which ameliorates the low-dimensional performance loss of the SSD architecture while preserving its computational efficiency. Drawing inspiration from TiSASRec, we develop a time-aware enhancement method tailored for the linear computation demands of the SSD architecture, thereby enhancing its adaptability and achieving state-of-the-art (SOTA) performance in both low and high-dimensional modeling. The code for our model is publicly accessible at https://github.com/AlwaysFHao/TiM4Rec.
Shadow Generation for Composite Image Using Diffusion model
Mar 22, 2024In the realm of image composition, generating realistic shadow for the inserted foreground remains a formidable challenge. Previous works have developed image-to-image translation models which are trained on paired training data. However, they are struggling to generate shadows with accurate shapes and intensities, hindered by data scarcity and inherent task complexity. In this paper, we resort to foundation model with rich prior knowledge of natural shadow images. Specifically, we first adapt ControlNet to our task and then propose intensity modulation modules to improve the shadow intensity. Moreover, we extend the small-scale DESOBA dataset to DESOBAv2 using a novel data acquisition pipeline. Experimental results on both DESOBA and DESOBAv2 datasets as well as real composite images demonstrate the superior capability of our model for shadow generation task. The dataset, code, and model are released at https://github.com/bcmi/Object-Shadow-Generation-Dataset-DESOBAv2.
DESOBAv2: Towards Large-scale Real-world Dataset for Shadow Generation
Aug 19, 2023


Image composition refers to inserting a foreground object into a background image to obtain a composite image. In this work, we focus on generating plausible shadow for the inserted foreground object to make the composite image more realistic. To supplement the existing small-scale dataset DESOBA, we create a large-scale dataset called DESOBAv2 by using object-shadow detection and inpainting techniques. Specifically, we collect a large number of outdoor scene images with object-shadow pairs. Then, we use pretrained inpainting model to inpaint the shadow region, resulting in the deshadowed images. Based on real images and deshadowed images, we can construct pairs of synthetic composite images and ground-truth target images. Dataset is available at https://github.com/bcmi/Object-Shadow-Generation-Dataset-DESOBAv2.
Fast Object Placement Assessment
May 28, 2022

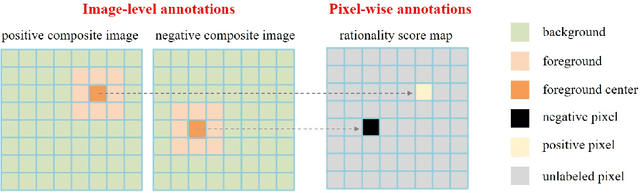

Object placement assessment (OPA) aims to predict the rationality score of a composite image in terms of the placement (e.g., scale, location) of inserted foreground object. However, given a pair of scaled foreground and background, to enumerate all the reasonable locations, existing OPA model needs to place the foreground at each location on the background and pass the obtained composite image through the model one at a time, which is very time-consuming. In this work, we investigate a new task named as fast OPA. Specifically, provided with a scaled foreground and a background, we only pass them through the model once and predict the rationality scores for all locations. To accomplish this task, we propose a pioneering fast OPA model with several innovations (i.e., foreground dynamic filter, background prior transfer, and composite feature mimicking) to bridge the performance gap between slow OPA model and fast OPA model. Extensive experiments on OPA dataset show that our proposed fast OPA model performs on par with slow OPA model but runs significantly faster.
OPA: Object Placement Assessment Dataset
Jul 05, 2021Image composition aims to generate realistic composite image by inserting an object from one image into another background image, where the placement (e.g., location, size, occlusion) of inserted object may be unreasonable, which would significantly degrade the quality of the composite image. Although some works attempted to learn object placement to create realistic composite images, they did not focus on assessing the plausibility of object placement. In this paper, we focus on object placement assessment task, which verifies whether a composite image is plausible in terms of the object placement. To accomplish this task, we construct the first Object Placement Assessment (OPA) dataset consisting of composite images and their rationality labels. Dataset is available at https://github.com/bcmi/Object-Placement-Assessment-Dataset-OPA.