 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstaInpaint: Instant 3D-Scene Inpainting with Masked Large Reconstruction Model
Jun 12, 2025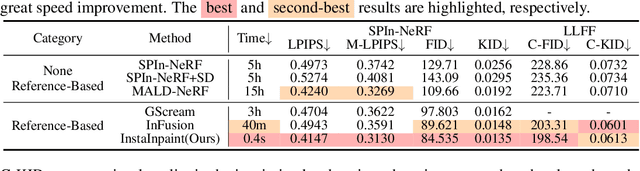


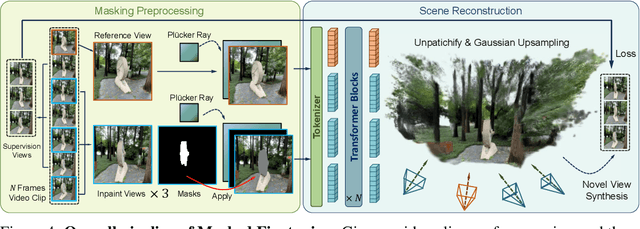
Recent advances in 3D scene reconstruction enable real-time viewing in virtual and augmented reality. To support interactive operations for better immersiveness, such as moving or editing objects, 3D scene inpainting methods are proposed to repair or complete the altered geometry. However, current approaches rely on lengthy and computationally intensive optimization, making them impractical for real-time or online applications. We propose InstaInpaint, a reference-based feed-forward framework that produces 3D-scene inpainting from a 2D inpainting proposal within 0.4 seconds. We develop a self-supervised masked-finetuning strategy to enable training of our custom large reconstruction model (LRM) on the large-scale dataset. Through extensive experiments, we analyze and identify several key designs that improve generalization, textural consistency, and geometric correctness. InstaInpaint achieves a 1000x speed-up from prior methods while maintaining a state-of-the-art performance across two standard benchmarks. Moreover, we show that InstaInpaint generalizes well to flexible downstream applications such as object insertion and multi-region inpainting. More video results are available at our project page: https://dhmbb2.github.io/InstaInpaint_page/.
DriveTransformer: Unified Transformer for Scalable End-to-End Autonomous Driving
Mar 07, 2025End-to-end autonomous driving (E2E-AD) has emerged as a trend in the field of autonomous driving, promising a data-driven, scalable approach to system design. However, existing E2E-AD methods usually adopt the sequential paradigm of perception-prediction-planning, which leads to cumulative errors and training instability. The manual ordering of tasks also limits the system`s ability to leverage synergies between tasks (for example, planning-aware perception and game-theoretic interactive prediction and planning). Moreover, the dense BEV representation adopted by existing methods brings computational challenges for long-range perception and long-term temporal fusion. To address these challenges, we present DriveTransformer, a simplified E2E-AD framework for the ease of scaling up, characterized by three key features: Task Parallelism (All agent, map, and planning queries direct interact with each other at each block), Sparse Representation (Task queries direct interact with raw sensor features), and Streaming Processing (Task queries are stored and passed as history information). As a result, the new framework is composed of three unified operations: task self-attention, sensor cross-attention, temporal cross-attention, which significantly reduces the complexity of system and leads to better training stability. DriveTransformer achieves state-of-the-art performance in both simulated closed-loop benchmark Bench2Drive and real world open-loop benchmark nuScenes with high FPS.
Bench2Drive-R: Turning Real World Data into Reactive Closed-Loop Autonomous Driving Benchmark by Generative Model
Dec 11, 2024
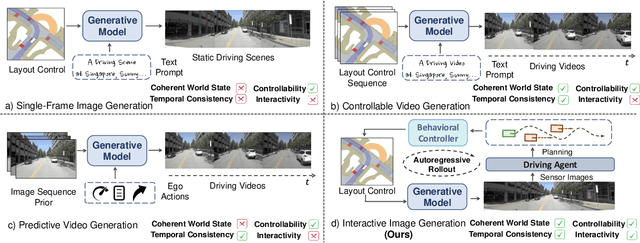
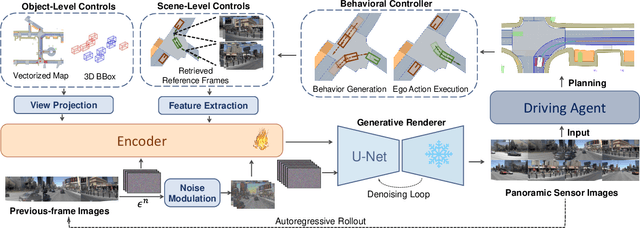
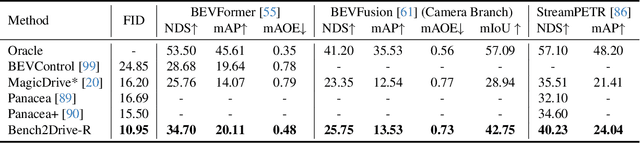
For end-to-end autonomous driving (E2E-AD), the evaluation system remains an open problem. Existing closed-loop evaluation protocols usually rely on simulators like CARLA being less realistic; while NAVSIM using real-world vision data, yet is limited to fixed planning trajectories in short horizon and assumes other agents are not reactive. We introduce Bench2Drive-R, a generative framework that enables reactive closed-loop evaluation. Unlike existing video generative models for AD, the proposed designs are tailored for interactive simulation, where sensor rendering and behavior rollout are decoupled by applying a separate behavioral controller to simulate the reactions of surrounding agents. As a result, the renderer could focus on image fidelity, control adherence, and spatial-temporal coherence. For temporal consistency, due to the step-wise interaction nature of simulation, we design a noise modulating temporal encoder with Gaussian blurring to encourage long-horizon autoregressive rollout of image sequences without deteriorating distribution shifts. For spatial consistency, a retrieval mechanism, which takes the spatially nearest images as references, is introduced to to ensure scene-level rendering fidelity during the generation process. The spatial relations between target and reference are explicitly modeled with 3D relative position encodings and the potential over-reliance of reference images is mitigated with hierarchical sampling and classifier-free guidance. We compare the generation quality of Bench2Drive-R with existing generative models and achieve state-of-the-art performance. We further integrate Bench2Drive-R into nuPlan and evaluate the generative qualities with closed-loop simulation results. We will open source our code.
Shadow Generation for Composite Image Using Diffusion model
Mar 22, 2024In the realm of image composition, generating realistic shadow for the inserted foreground remains a formidable challenge. Previous works have developed image-to-image translation models which are trained on paired training data. However, they are struggling to generate shadows with accurate shapes and intensities, hindered by data scarcity and inherent task complexity. In this paper, we resort to foundation model with rich prior knowledge of natural shadow images. Specifically, we first adapt ControlNet to our task and then propose intensity modulation modules to improve the shadow intensity. Moreover, we extend the small-scale DESOBA dataset to DESOBAv2 using a novel data acquisition pipeline. Experimental results on both DESOBA and DESOBAv2 datasets as well as real composite images demonstrate the superior capability of our model for shadow generation task. The dataset, code, and model are released at https://github.com/bcmi/Object-Shadow-Generation-Dataset-DESOBAv2.