 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation
Apr 04, 2024Tuning-free diffusion-based models have demonstrated significant potential in the realm of image personalization and customization. However, despite this notable progress, current models continue to grapple with several complex challenges in producing style-consistent image generation. Firstly, the concept of style is inherently underdetermined, encompassing a multitude of elements such as color, material, atmosphere, design, and structure, among others. Secondly, inversion-based methods are prone to style degradation, often resulting in the loss of fine-grained details. Lastly, adapter-based approaches frequently require meticulous weight tuning for each reference image to achieve a balance between style intensity and text controllability. In this paper, we commence by examining several compelling yet frequently overlooked observations. We then proceed to introduce InstantStyle, a framework designed to address these issues through the implementation of two key strategies: 1) A straightforward mechanism that decouples style and content from reference images within the feature space, predicated on the assumption that features within the same space can be either added to or subtracted from one another. 2) The injection of reference image features exclusively into style-specific blocks, thereby preventing style leaks and eschewing the need for cumbersome weight tuning, which often characterizes more parameter-heavy designs.Our work demonstrates superior visual stylization outcomes, striking an optimal balance between the intensity of style and the controllability of textual elements. Our codes will be available at https://github.com/InstantStyle/InstantStyle.
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Feb 02, 2024
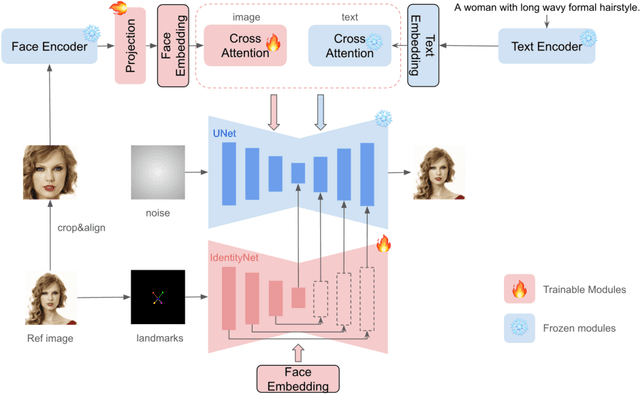


There has been significant progress in personalized image synthesis with methods such as Textual Inversion, DreamBooth, and LoRA. Yet, their real-world applicability is hindered by high storage demands, lengthy fine-tuning processes, and the need for multiple reference images. Conversely, existing ID embedding-based methods, while requiring only a single forward inference, face challenges: they either necessitate extensive fine-tuning across numerous model parameters, lack compatibility with community pre-trained models, or fail to maintain high face fidelity. Addressing these limitations, we introduce InstantID, a powerful diffusion model-based solution. Our plug-and-play module adeptly handles image personalization in various styles using just a single facial image, while ensuring high fidelity. To achieve this, we design a novel IdentityNet by imposing strong semantic and weak spatial conditions, integrating facial and landmark images with textual prompts to steer the image generation. InstantID demonstrates exceptional performance and efficiency, proving highly beneficial in real-world applications where identity preservation is paramount. Moreover, our work seamlessly integrates with popular pre-trained text-to-image diffusion models like SD1.5 and SDXL, serving as an adaptable plugin. Our codes and pre-trained checkpoints will be available at https://github.com/InstantID/InstantID.
BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation
Oct 22, 2021



Generative Adversarial Networks (GANs) have made a dramatic leap in high-fidelity image synthesis and stylized face generation. Recently, a layer-swapping mechanism has been developed to improve the stylization performance. However, this method is incapable of fitting arbitrary styles in a single model and requires hundreds of style-consistent training images for each style. To address the above issues, we propose BlendGAN for arbitrary stylized face generation by leveraging a flexible blending strategy and a generic artistic dataset. Specifically, we first train a self-supervised style encoder on the generic artistic dataset to extract the representations of arbitrary styles. In addition, a weighted blending module (WBM) is proposed to blend face and style representations implicitly and control the arbitrary stylization effect. By doing so, BlendGAN can gracefully fit arbitrary styles in a unified model while avoiding case-by-case preparation of style-consistent training images. To this end, we also present a novel large-scale artistic face dataset AAHQ. Extensive experiments demonstrate that BlendGAN outperforms state-of-the-art methods in terms of visual quality and style diversity for both latent-guided and reference-guided stylized face synthesis.
Siamese Keypoint Prediction Network for Visual Object Tracking
Jun 07, 2020
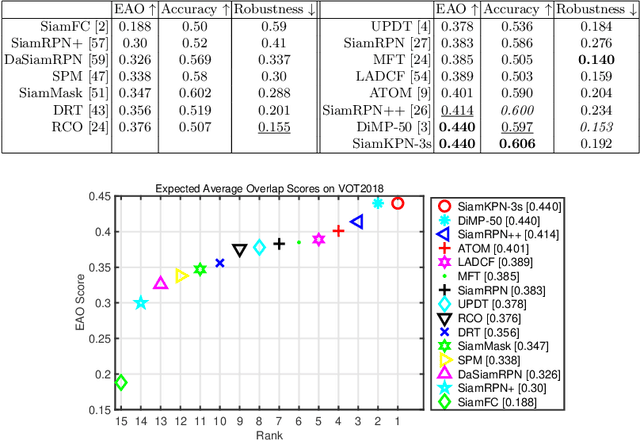
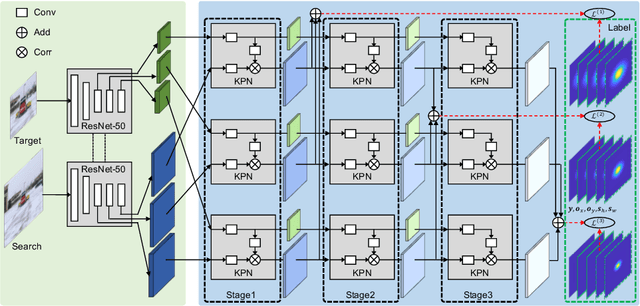
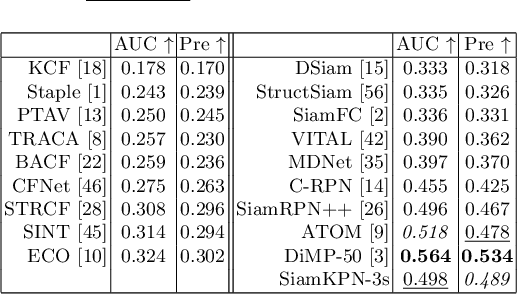
Visual object tracking aims to estimate the location of an arbitrary target in a video sequence given its initial bounding box. By utilizing offline feature learning, the siamese paradigm has recently been the leading framework for high performance tracking. However, current existing siamese trackers either heavily rely on complicated anchor-based detection networks or lack the ability to resist to distractors. In this paper, we propose the Siamese keypoint prediction network (SiamKPN) to address these challenges. Upon a Siamese backbone for feature embedding, SiamKPN benefits from a cascade heatmap strategy for coarse-to-fine prediction modeling. In particular, the strategy is implemented by sequentially shrinking the coverage of the label heatmap along the cascade to apply loose-to-strict intermediate supervisions. During inference, we find the predicted heatmaps of successive stages to be gradually concentrated to the target and reduced to the distractors. SiamKPN performs well against state-of-the-art trackers for visual object tracking on four benchmark datasets including OTB-100, VOT2018, LaSOT and GOT-10k, while running at real-time speed.