 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Jun 17, 2025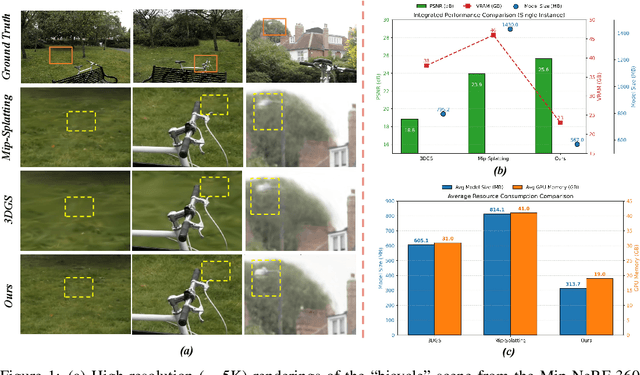

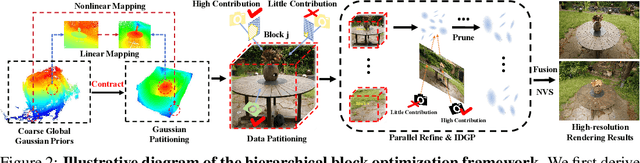

3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
Information Bottleneck-Guided Heterogeneous Graph Learning for Interpretable Neurodevelopmental Disorder Diagnosis
Feb 28, 2025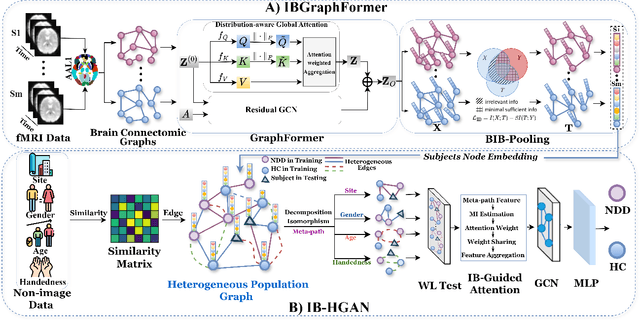
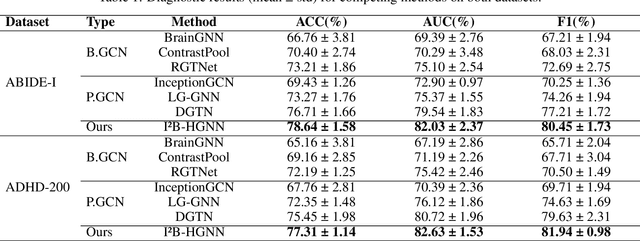

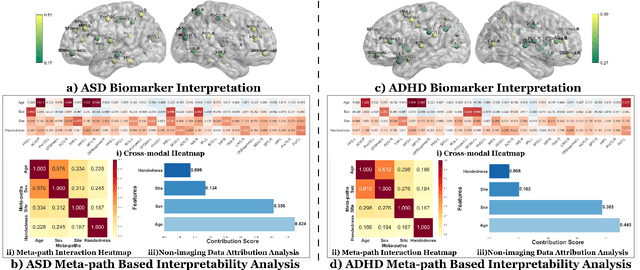
Developing interpretable models for diagnosing neurodevelopmental disorders (NDDs) is highly valuable yet challenging, primarily due to the complexity of encoding, decoding and integrating imaging and non-imaging data. Many existing machine learning models struggle to provide comprehensive interpretability, often failing to extract meaningful biomarkers from imaging data, such as functional magnetic resonance imaging (fMRI), or lacking mechanisms to explain the significance of non-imaging data. In this paper, we propose the Interpretable Information Bottleneck Heterogeneous Graph Neural Network (I2B-HGNN), a novel framework designed to learn from fine-grained local patterns to comprehensive global multi-modal interactions. This framework comprises two key modules. The first module, the Information Bottleneck Graph Transformer (IBGraphFormer) for local patterns, integrates global modeling with brain connectomic-constrained graph neural networks to identify biomarkers through information bottleneck-guided pooling. The second module, the Information Bottleneck Heterogeneous Graph Attention Network (IB-HGAN) for global multi-modal interactions, facilitates interpretable multi-modal fusion of imaging and non-imaging data using heterogeneous graph neural networks. The results of the experiments demonstrate that I2B-HGNN excels in diagnosing NDDs with high accuracy, providing interpretable biomarker identification and effective analysis of non-imaging data.
STARFormer: A Novel Spatio-Temporal Aggregation Reorganization Transformer of FMRI for Brain Disorder Diagnosis
Dec 31, 2024



Many existing methods that use functional magnetic resonance imaging (fMRI) classify brain disorders, such as autism spectrum disorder (ASD) and attention deficit hyperactivity disorder (ADHD), often overlook the integration of spatial and temporal dependencies of the blood oxygen level-dependent (BOLD) signals, which may lead to inaccurate or imprecise classification results. To solve this problem, we propose a Spatio-Temporal Aggregation eorganization ransformer (STARFormer) that effectively captures both spatial and temporal features of BOLD signals by incorporating three key modules. The region of interest (ROI) spatial structure analysis module uses eigenvector centrality (EC) to reorganize brain regions based on effective connectivity, highlighting critical spatial relationships relevant to the brain disorder. The temporal feature reorganization module systematically segments the time series into equal-dimensional window tokens and captures multiscale features through variable window and cross-window attention. The spatio-temporal feature fusion module employs a parallel transformer architecture with dedicated temporal and spatial branches to extract integrated features. The proposed STARFormer has been rigorously evaluated on two publicly available datasets for the classification of ASD and ADHD. The experimental results confirm that the STARFormer achieves state-of-the-art performance across multiple evaluation metrics, providing a more accurate and reliable tool for the diagnosis of brain disorders and biomedical research. The codes will be available at: https://github.com/NZWANG/STARFormer.
Neural-MCRL: Neural Multimodal Contrastive Representation Learning for EEG-based Visual Decoding
Dec 23, 2024



Decoding neural visual representations from electroencephalogram (EEG)-based brain activity is crucial for advancing brain-machine interfaces (BMI) and has transformative potential for neural sensory rehabilitation. While multimodal contrastive representation learning (MCRL) has shown promise in neural decoding, existing methods often overlook semantic consistency and completeness within modalities and lack effective semantic alignment across modalities. This limits their ability to capture the complex representations of visual neural responses. We propose Neural-MCRL, a novel framework that achieves multimodal alignment through semantic bridging and cross-attention mechanisms, while ensuring completeness within modalities and consistency across modalities. Our framework also features the Neural Encoder with Spectral-Temporal Adaptation (NESTA), a EEG encoder that adaptively captures spectral patterns and learns subject-specific transformations. Experimental results demonstrate significant improvements in visual decoding accuracy and model generalization compared to state-of-the-art methods, advancing the field of EEG-based neural visual representation decoding in BMI. Codes will be available at: https://github.com/NZWANG/Neural-MCRL.
A Tale of Single-channel Electroencephalogram: Devices, Datasets, Signal Processing, Applications, and Future Directions
Jul 20, 2024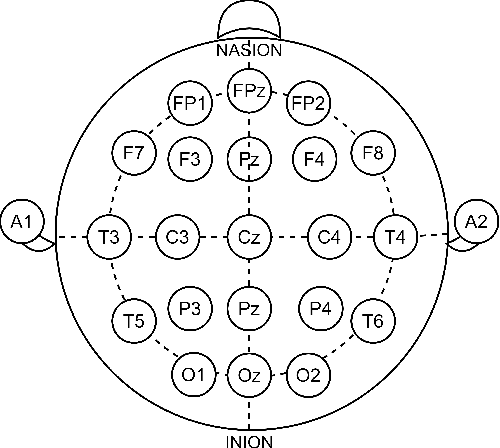
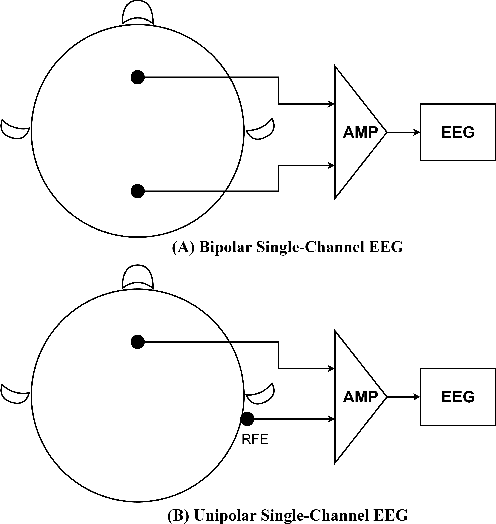
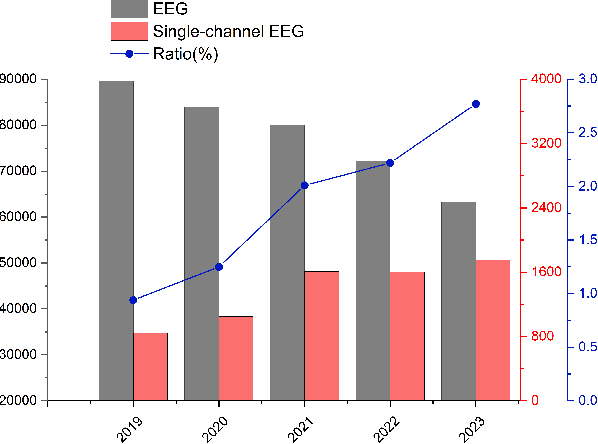

Single-channel electroencephalogram (EEG) is a cost-effective, comfortable, and non-invasive method for monitoring brain activity, widely adopted by researchers, consumers, and clinicians. The increasing number and proportion of articles on single-channel EEG underscore its growing potential. This paper provides a comprehensive review of single-channel EEG, focusing on development trends, devices, datasets, signal processing methods, recent applications, and future directions. Definitions of bipolar and unipolar configurations in single-channel EEG are clarified to guide future advancements. Applications mainly span sleep staging, emotion recognition, educational research, and clinical diagnosis. Ongoing advancements of single-channel EEG in AI-based EEG generation techniques suggest potential parity or superiority over multichannel EEG performance.
MHNet: Multi-view High-order Network for Diagnosing Neurodevelopmental Disorders Using Resting-state fMRI
Jul 03, 2024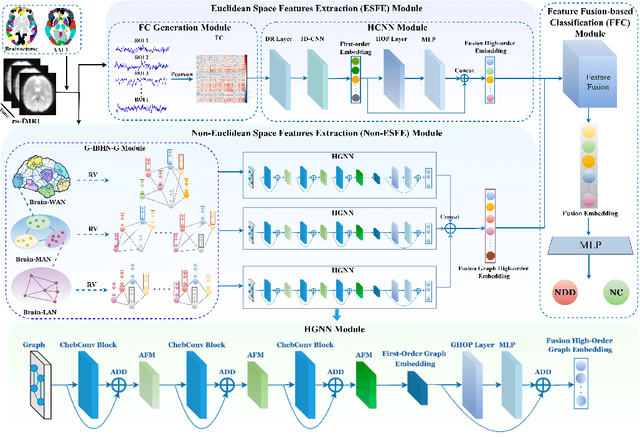
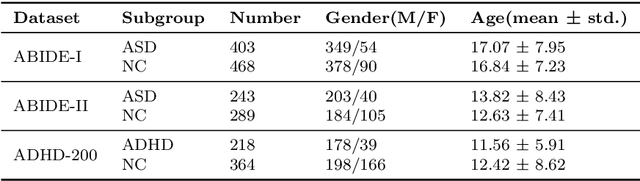
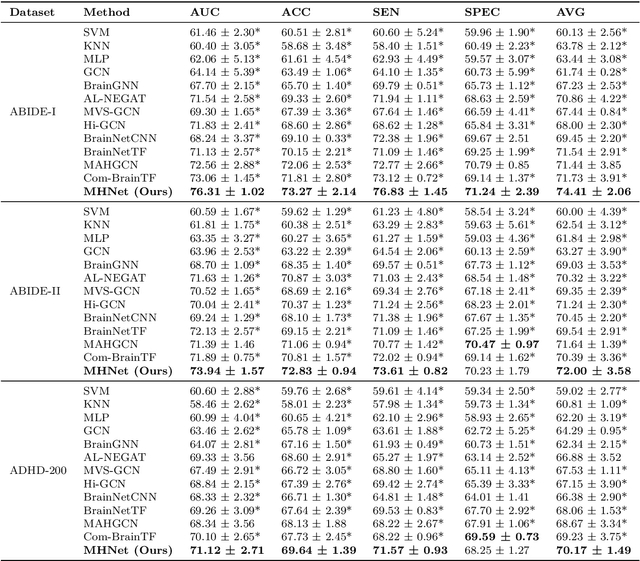
Background: Deep learning models have shown promise in diagnosing neurodevelopmental disorders (NDD) like ASD and ADHD. However, many models either use graph neural networks (GNN) to construct single-level brain functional networks (BFNs) or employ spatial convolution filtering for local information extraction from rs-fMRI data, often neglecting high-order features crucial for NDD classification. Methods: We introduce a Multi-view High-order Network (MHNet) to capture hierarchical and high-order features from multi-view BFNs derived from rs-fMRI data for NDD prediction. MHNet has two branches: the Euclidean Space Features Extraction (ESFE) module and the Non-Euclidean Space Features Extraction (Non-ESFE) module, followed by a Feature Fusion-based Classification (FFC) module for NDD identification. ESFE includes a Functional Connectivity Generation (FCG) module and a High-order Convolutional Neural Network (HCNN) module to extract local and high-order features from BFNs in Euclidean space. Non-ESFE comprises a Generic Internet-like Brain Hierarchical Network Generation (G-IBHN-G) module and a High-order Graph Neural Network (HGNN) module to capture topological and high-order features in non-Euclidean space. Results: Experiments on three public datasets show that MHNet outperforms state-of-the-art methods using both AAL1 and Brainnetome Atlas templates. Extensive ablation studies confirm the superiority of MHNet and the effectiveness of using multi-view fMRI information and high-order features. Our study also offers atlas options for constructing more sophisticated hierarchical networks and explains the association between key brain regions and NDD. Conclusion: MHNet leverages multi-view feature learning from both Euclidean and non-Euclidean spaces, incorporating high-order information from BFNs to enhance NDD classification performance.
Fusion-Mamba for Cross-modality Object Detection
Apr 14, 2024
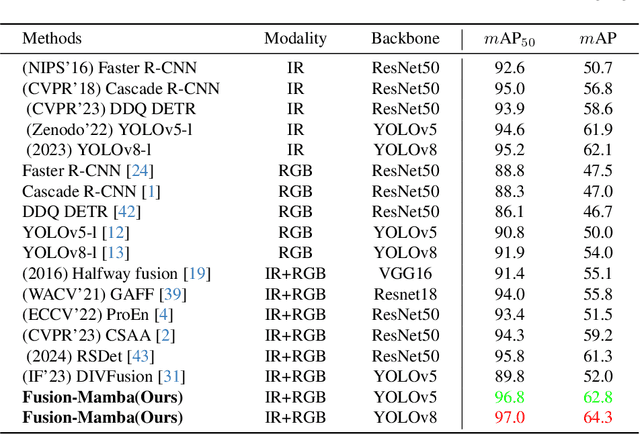
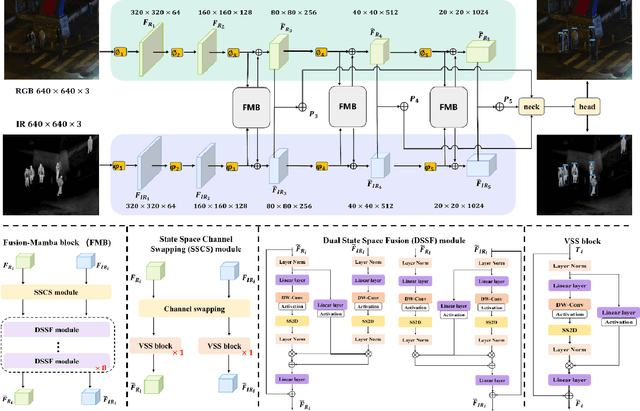
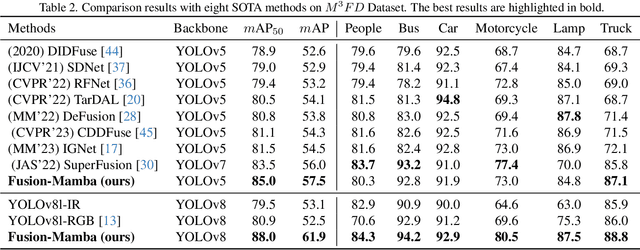
Cross-modality fusing complementary information from different modalities effectively improves object detection performance, making it more useful and robust for a wider range of applications. Existing fusion strategies combine different types of images or merge different backbone features through elaborated neural network modules. However, these methods neglect that modality disparities affect cross-modality fusion performance, as different modalities with different camera focal lengths, placements, and angles are hardly fused. In this paper, we investigate cross-modality fusion by associating cross-modal features in a hidden state space based on an improved Mamba with a gating mechanism. We design a Fusion-Mamba block (FMB) to map cross-modal features into a hidden state space for interaction, thereby reducing disparities between cross-modal features and enhancing the representation consistency of fused features. FMB contains two modules: the State Space Channel Swapping (SSCS) module facilitates shallow feature fusion, and the Dual State Space Fusion (DSSF) enables deep fusion in a hidden state space. Through extensive experiments on public datasets, our proposed approach outperforms the state-of-the-art methods on $m$AP with 5.9% on $M^3FD$ and 4.9% on FLIR-Aligned datasets, demonstrating superior object detection performance. To the best of our knowledge, this is the first work to explore the potential of Mamba for cross-modal fusion and establish a new baseline for cross-modality object detection.