 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanGS: A Scalable and Efficient Architecture for Geometrically Accurate Large-Scene Reconstruction
Feb 02, 2026While 3D Gaussian Splatting (3DGS) enables high-quality, real-time rendering for bounded scenes, its extension to large-scale urban environments gives rise to critical challenges in terms of geometric consistency, memory efficiency, and computational scalability. To address these issues, we present UrbanGS, a scalable reconstruction framework that effectively tackles these challenges for city-scale applications. First, we propose a Depth-Consistent D-Normal Regularization module. Unlike existing approaches that rely solely on monocular normal estimators, which can effectively update rotation parameters yet struggle to update position parameters, our method integrates D-Normal constraints with external depth supervision. This allows for comprehensive updates of all geometric parameters. By further incorporating an adaptive confidence weighting mechanism based on gradient consistency and inverse depth deviation, our approach significantly enhances multi-view depth alignment and geometric coherence, which effectively resolves the issue of geometric accuracy in complex large-scale scenes. To improve scalability, we introduce a Spatially Adaptive Gaussian Pruning (SAGP) strategy, which dynamically adjusts Gaussian density based on local geometric complexity and visibility to reduce redundancy. Additionally, a unified partitioning and view assignment scheme is designed to eliminate boundary artifacts and optimize computational load. Extensive experiments on multiple urban datasets demonstrate that UrbanGS achieves superior performance in rendering quality, geometric accuracy, and memory efficiency, providing a systematic solution for high-fidelity large-scale scene reconstruction.
Surf3R: Rapid Surface Reconstruction from Sparse RGB Views in Seconds
Aug 06, 2025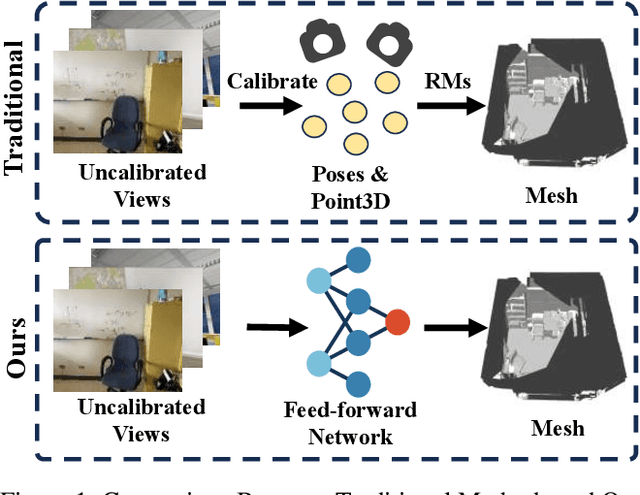
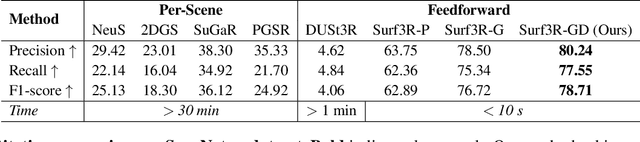
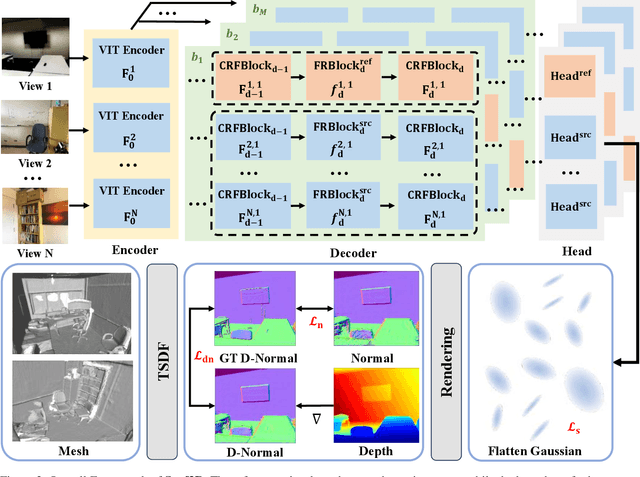

Current multi-view 3D reconstruction methods rely on accurate camera calibration and pose estimation, requiring complex and time-intensive pre-processing that hinders their practical deployment. To address this challenge, we introduce Surf3R, an end-to-end feedforward approach that reconstructs 3D surfaces from sparse views without estimating camera poses and completes an entire scene in under 10 seconds. Our method employs a multi-branch and multi-view decoding architecture in which multiple reference views jointly guide the reconstruction process. Through the proposed branch-wise processing, cross-view attention, and inter-branch fusion, the model effectively captures complementary geometric cues without requiring camera calibration. Moreover, we introduce a D-Normal regularizer based on an explicit 3D Gaussian representation for surface reconstruction. It couples surface normals with other geometric parameters to jointly optimize the 3D geometry, significantly improving 3D consistency and surface detail accuracy. Experimental results demonstrate that Surf3R achieves state-of-the-art performance on multiple surface reconstruction metrics on ScanNet++ and Replica datasets, exhibiting excellent generalization and efficiency.
Squeeze10-LLM: Squeezing LLMs' Weights by 10 Times via a Staged Mixed-Precision Quantization Method
Jul 24, 2025Deploying large language models (LLMs) is challenging due to their massive parameters and high computational costs. Ultra low-bit quantization can significantly reduce storage and accelerate inference, but extreme compression (i.e., mean bit-width <= 2) often leads to severe performance degradation. To address this, we propose Squeeze10-LLM, effectively "squeezing" 16-bit LLMs' weights by 10 times. Specifically, Squeeze10-LLM is a staged mixed-precision post-training quantization (PTQ) framework and achieves an average of 1.6 bits per weight by quantizing 80% of the weights to 1 bit and 20% to 4 bits. We introduce Squeeze10LLM with two key innovations: Post-Binarization Activation Robustness (PBAR) and Full Information Activation Supervision (FIAS). PBAR is a refined weight significance metric that accounts for the impact of quantization on activations, improving accuracy in low-bit settings. FIAS is a strategy that preserves full activation information during quantization to mitigate cumulative error propagation across layers. Experiments on LLaMA and LLaMA2 show that Squeeze10-LLM achieves state-of-the-art performance for sub-2bit weight-only quantization, improving average accuracy from 43% to 56% on six zero-shot classification tasks--a significant boost over existing PTQ methods. Our code will be released upon publication.
HRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Jun 17, 2025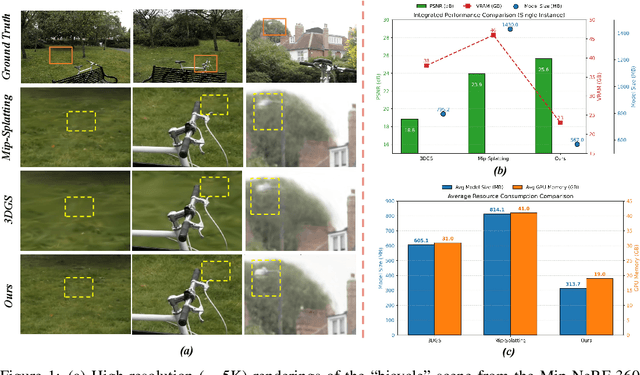

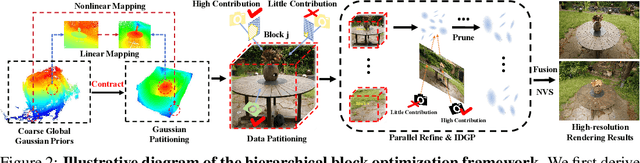

3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
Fusion-Mamba for Cross-modality Object Detection
Apr 14, 2024
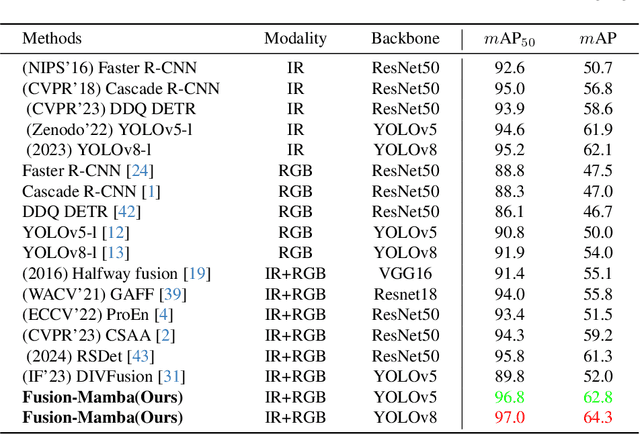
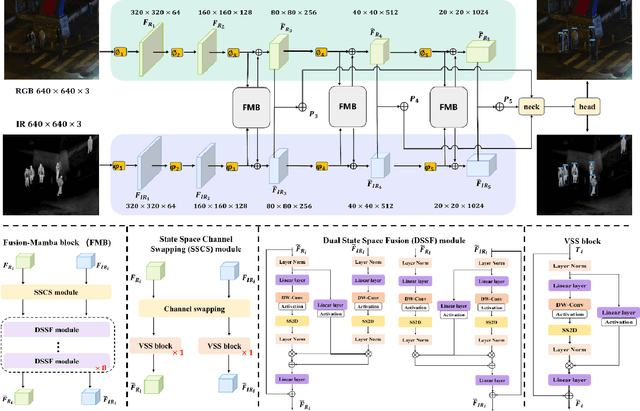
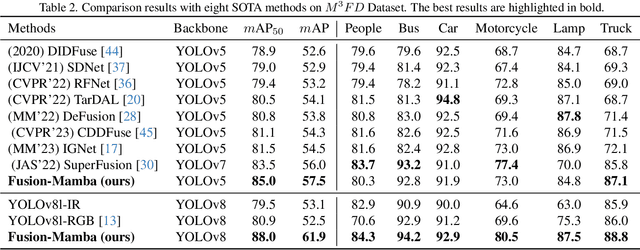
Cross-modality fusing complementary information from different modalities effectively improves object detection performance, making it more useful and robust for a wider range of applications. Existing fusion strategies combine different types of images or merge different backbone features through elaborated neural network modules. However, these methods neglect that modality disparities affect cross-modality fusion performance, as different modalities with different camera focal lengths, placements, and angles are hardly fused. In this paper, we investigate cross-modality fusion by associating cross-modal features in a hidden state space based on an improved Mamba with a gating mechanism. We design a Fusion-Mamba block (FMB) to map cross-modal features into a hidden state space for interaction, thereby reducing disparities between cross-modal features and enhancing the representation consistency of fused features. FMB contains two modules: the State Space Channel Swapping (SSCS) module facilitates shallow feature fusion, and the Dual State Space Fusion (DSSF) enables deep fusion in a hidden state space. Through extensive experiments on public datasets, our proposed approach outperforms the state-of-the-art methods on $m$AP with 5.9% on $M^3FD$ and 4.9% on FLIR-Aligned datasets, demonstrating superior object detection performance. To the best of our knowledge, this is the first work to explore the potential of Mamba for cross-modal fusion and establish a new baseline for cross-modality object detection.