 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-aware Spatiotemporal Modeling with Collaborative Domain Generalization for Cross-Subject EEG Emotion Recognition
Jan 22, 2026Cross-subject EEG-based emotion recognition (EER) remains challenging due to strong inter-subject variability, which induces substantial distribution shifts in EEG signals, as well as the high complexity of emotion-related neural representations in both spatial organization and temporal evolution. Existing approaches typically improve spatial modeling, temporal modeling, or generalization strategies in isolation, which limits their ability to align representations across subjects while capturing multi-scale dynamics and suppressing subject-specific bias within a unified framework. To address these gaps, we propose a Region-aware Spatiotemporal Modeling framework with Collaborative Domain Generalization (RSM-CoDG) for cross-subject EEG emotion recognition. RSM-CoDG incorporates neuroscience priors derived from functional brain region partitioning to construct region-level spatial representations, thereby improving cross-subject comparability. It also employs multi-scale temporal modeling to characterize the dynamic evolution of emotion-evoked neural activity. In addition, the framework employs a collaborative domain generalization strategy, incorporating multidimensional constraints to reduce subject-specific bias in a fully unseen target subject setting, which enhances the generalization to unknown individuals. Extensive experimental results on SEED series datasets demonstrate that RSM-CoDG consistently outperforms existing competing methods, providing an effective approach for improving robustness. The source code is available at https://github.com/RyanLi-X/RSM-CoDG.
LEREL: Lipschitz Continuity-Constrained Emotion Recognition Ensemble Learning For Electroencephalography
Apr 12, 2025


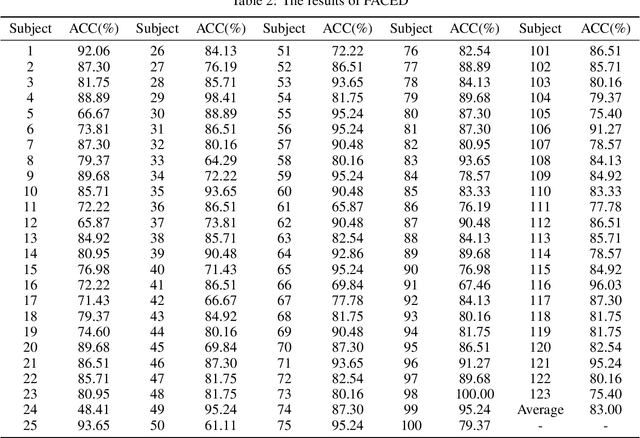
Accurate and efficient perception of emotional states in oneself and others is crucial, as emotion-related disorders are associated with severe psychosocial impairments. While electroencephalography (EEG) offers a powerful tool for emotion detection, current EEG-based emotion recognition (EER) methods face key limitations: insufficient model stability, limited accuracy in processing high-dimensional nonlinear EEG signals, and poor robustness against intra-subject variability and signal noise. To address these challenges, we propose LEREL (Lipschitz continuity-constrained Emotion Recognition Ensemble Learning), a novel framework that significantly enhances both the accuracy and robustness of emotion recognition performance. The LEREL framework employs Lipschitz continuity constraints to enhance model stability and generalization in EEG emotion recognition, reducing signal variability and noise susceptibility while maintaining strong performance on small-sample datasets. The ensemble learning strategy reduces single-model bias and variance through multi-classifier decision fusion, further optimizing overall performance. Experimental results on three public benchmark datasets (EAV, FACED and SEED) demonstrate LEREL's effectiveness, achieving average recognition accuracies of 76.43%, 83.00% and 89.22%, respectively.
Information Bottleneck-Guided Heterogeneous Graph Learning for Interpretable Neurodevelopmental Disorder Diagnosis
Feb 28, 2025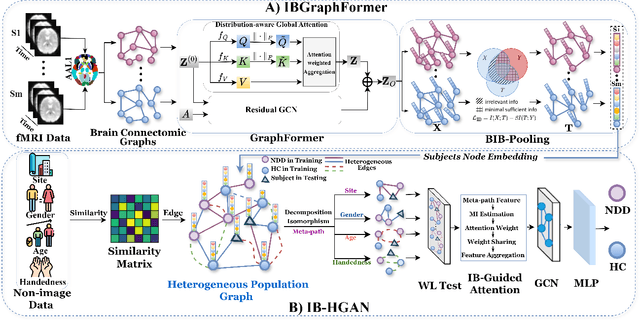
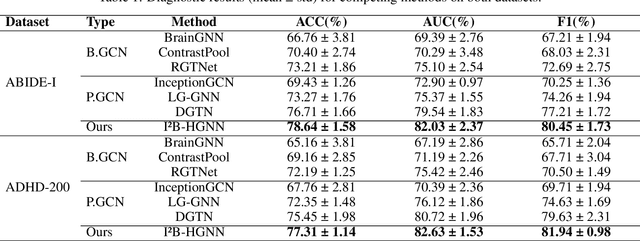

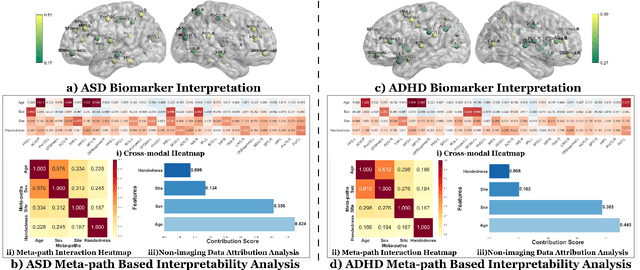
Developing interpretable models for diagnosing neurodevelopmental disorders (NDDs) is highly valuable yet challenging, primarily due to the complexity of encoding, decoding and integrating imaging and non-imaging data. Many existing machine learning models struggle to provide comprehensive interpretability, often failing to extract meaningful biomarkers from imaging data, such as functional magnetic resonance imaging (fMRI), or lacking mechanisms to explain the significance of non-imaging data. In this paper, we propose the Interpretable Information Bottleneck Heterogeneous Graph Neural Network (I2B-HGNN), a novel framework designed to learn from fine-grained local patterns to comprehensive global multi-modal interactions. This framework comprises two key modules. The first module, the Information Bottleneck Graph Transformer (IBGraphFormer) for local patterns, integrates global modeling with brain connectomic-constrained graph neural networks to identify biomarkers through information bottleneck-guided pooling. The second module, the Information Bottleneck Heterogeneous Graph Attention Network (IB-HGAN) for global multi-modal interactions, facilitates interpretable multi-modal fusion of imaging and non-imaging data using heterogeneous graph neural networks. The results of the experiments demonstrate that I2B-HGNN excels in diagnosing NDDs with high accuracy, providing interpretable biomarker identification and effective analysis of non-imaging data.
STARFormer: A Novel Spatio-Temporal Aggregation Reorganization Transformer of FMRI for Brain Disorder Diagnosis
Dec 31, 2024



Many existing methods that use functional magnetic resonance imaging (fMRI) classify brain disorders, such as autism spectrum disorder (ASD) and attention deficit hyperactivity disorder (ADHD), often overlook the integration of spatial and temporal dependencies of the blood oxygen level-dependent (BOLD) signals, which may lead to inaccurate or imprecise classification results. To solve this problem, we propose a Spatio-Temporal Aggregation eorganization ransformer (STARFormer) that effectively captures both spatial and temporal features of BOLD signals by incorporating three key modules. The region of interest (ROI) spatial structure analysis module uses eigenvector centrality (EC) to reorganize brain regions based on effective connectivity, highlighting critical spatial relationships relevant to the brain disorder. The temporal feature reorganization module systematically segments the time series into equal-dimensional window tokens and captures multiscale features through variable window and cross-window attention. The spatio-temporal feature fusion module employs a parallel transformer architecture with dedicated temporal and spatial branches to extract integrated features. The proposed STARFormer has been rigorously evaluated on two publicly available datasets for the classification of ASD and ADHD. The experimental results confirm that the STARFormer achieves state-of-the-art performance across multiple evaluation metrics, providing a more accurate and reliable tool for the diagnosis of brain disorders and biomedical research. The codes will be available at: https://github.com/NZWANG/STARFormer.
Neural-MCRL: Neural Multimodal Contrastive Representation Learning for EEG-based Visual Decoding
Dec 23, 2024



Decoding neural visual representations from electroencephalogram (EEG)-based brain activity is crucial for advancing brain-machine interfaces (BMI) and has transformative potential for neural sensory rehabilitation. While multimodal contrastive representation learning (MCRL) has shown promise in neural decoding, existing methods often overlook semantic consistency and completeness within modalities and lack effective semantic alignment across modalities. This limits their ability to capture the complex representations of visual neural responses. We propose Neural-MCRL, a novel framework that achieves multimodal alignment through semantic bridging and cross-attention mechanisms, while ensuring completeness within modalities and consistency across modalities. Our framework also features the Neural Encoder with Spectral-Temporal Adaptation (NESTA), a EEG encoder that adaptively captures spectral patterns and learns subject-specific transformations. Experimental results demonstrate significant improvements in visual decoding accuracy and model generalization compared to state-of-the-art methods, advancing the field of EEG-based neural visual representation decoding in BMI. Codes will be available at: https://github.com/NZWANG/Neural-MCRL.
Delay Minimization for Movable Antennas-Enabled Anti-Jamming Communications With Mobile Edge Computing
Sep 22, 2024



In future 6G networks, anti-jamming will become a critical challenge, particularly with the development of intelligent jammers that can initiate malicious interference, posing a significant security threat to communication transmission. Additionally, 6G networks have introduced mobile edge computing (MEC) technology to reduce system delay for edge user equipment (UEs). Thus, one of the key challenges in wireless communications is minimizing the system delay while mitigating interference and improving the communication rate. However, the current fixed-position antenna (FPA) techniques have limited degrees of freedom (DoF) and high power consumption, making them inadequate for communication in highly interfering environments. To address these challenges, this paper proposes a novel MEC anti-jamming communication architecture supported by mobile antenna (MA) technology. The core of the MA technique lies in optimizing the position of the antennas to increase DoF. The increase in DoF enhances the system's anti-jamming capabilities and reduces system delay. In this study, our goal is to reduce system delay while ensuring communication security and computational requirements. We design the position of MAs for UEs and the base station (BS), optimize the transmit beamforming at the UEs and the receive beamforming at the BS, and adjust the offloading rates and resource allocation for computation tasks at the MEC server. Since the optimization problem is a non-convex multi-variable coupled problem, we propose an algorithm based on penalty dual decomposition (PDD) combined with successive convex approximation (SCA). The simulation results demonstrate that the proposed MA architecture and the corresponding schemes offer superior anti-jamming capabilities and reduce the system delay compared to FPA.
A Tale of Single-channel Electroencephalogram: Devices, Datasets, Signal Processing, Applications, and Future Directions
Jul 20, 2024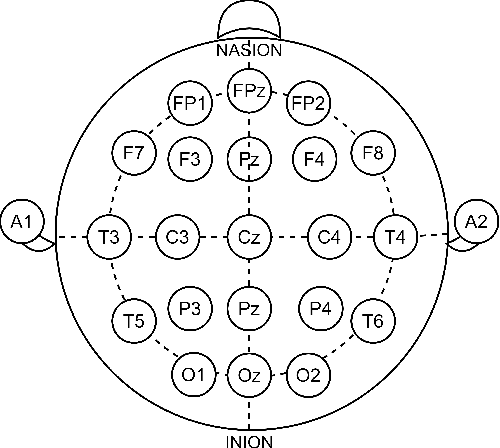
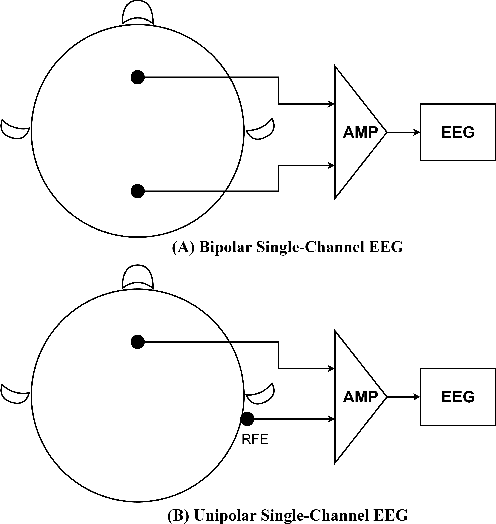
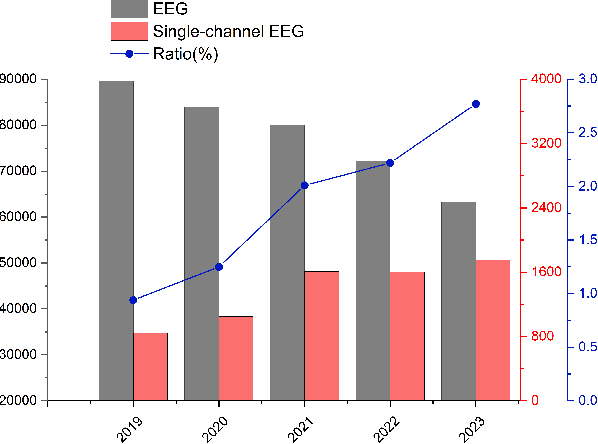

Single-channel electroencephalogram (EEG) is a cost-effective, comfortable, and non-invasive method for monitoring brain activity, widely adopted by researchers, consumers, and clinicians. The increasing number and proportion of articles on single-channel EEG underscore its growing potential. This paper provides a comprehensive review of single-channel EEG, focusing on development trends, devices, datasets, signal processing methods, recent applications, and future directions. Definitions of bipolar and unipolar configurations in single-channel EEG are clarified to guide future advancements. Applications mainly span sleep staging, emotion recognition, educational research, and clinical diagnosis. Ongoing advancements of single-channel EEG in AI-based EEG generation techniques suggest potential parity or superiority over multichannel EEG performance.
MHNet: Multi-view High-order Network for Diagnosing Neurodevelopmental Disorders Using Resting-state fMRI
Jul 03, 2024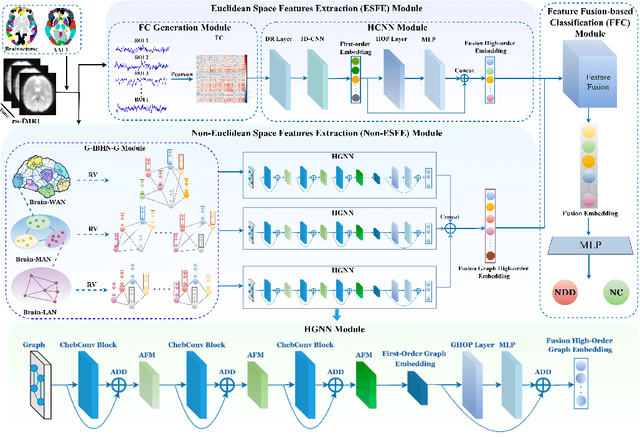
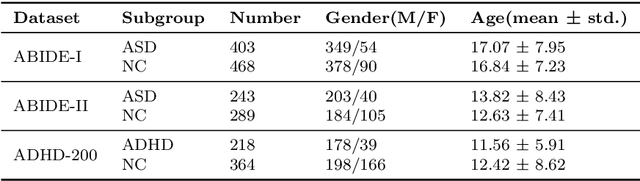
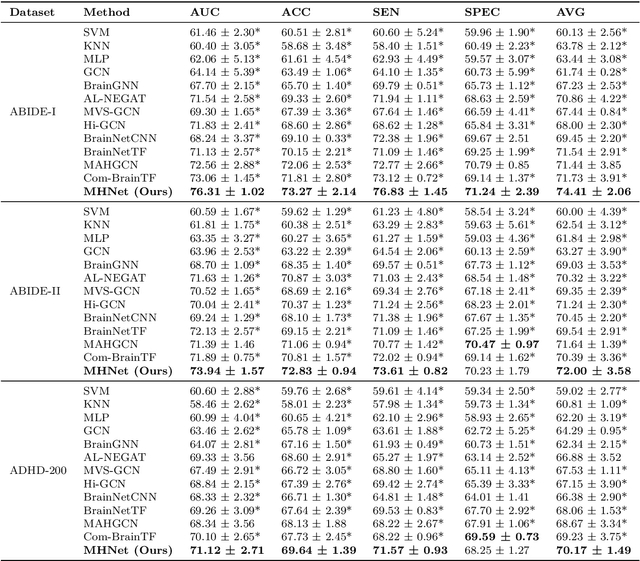
Background: Deep learning models have shown promise in diagnosing neurodevelopmental disorders (NDD) like ASD and ADHD. However, many models either use graph neural networks (GNN) to construct single-level brain functional networks (BFNs) or employ spatial convolution filtering for local information extraction from rs-fMRI data, often neglecting high-order features crucial for NDD classification. Methods: We introduce a Multi-view High-order Network (MHNet) to capture hierarchical and high-order features from multi-view BFNs derived from rs-fMRI data for NDD prediction. MHNet has two branches: the Euclidean Space Features Extraction (ESFE) module and the Non-Euclidean Space Features Extraction (Non-ESFE) module, followed by a Feature Fusion-based Classification (FFC) module for NDD identification. ESFE includes a Functional Connectivity Generation (FCG) module and a High-order Convolutional Neural Network (HCNN) module to extract local and high-order features from BFNs in Euclidean space. Non-ESFE comprises a Generic Internet-like Brain Hierarchical Network Generation (G-IBHN-G) module and a High-order Graph Neural Network (HGNN) module to capture topological and high-order features in non-Euclidean space. Results: Experiments on three public datasets show that MHNet outperforms state-of-the-art methods using both AAL1 and Brainnetome Atlas templates. Extensive ablation studies confirm the superiority of MHNet and the effectiveness of using multi-view fMRI information and high-order features. Our study also offers atlas options for constructing more sophisticated hierarchical networks and explains the association between key brain regions and NDD. Conclusion: MHNet leverages multi-view feature learning from both Euclidean and non-Euclidean spaces, incorporating high-order information from BFNs to enhance NDD classification performance.
You Only Acquire Sparse-channel (YOAS): A Unified Framework for Dense-channel EEG Generation
Jun 21, 2024



High-precision acquisition of dense-channel electroencephalogram (EEG) signals is often impeded by the costliness and lack of portability of equipment. In contrast, generating dense-channel EEG signals effectively from sparse channels shows promise and economic viability. However, sparse-channel EEG poses challenges such as reduced spatial resolution, information loss, signal mixing, and heightened susceptibility to noise and interference. To address these challenges, we first theoretically formulate the dense-channel EEG generation problem as by optimizing a set of cross-channel EEG signal generation problems. Then, we propose the YOAS framework for generating dense-channel data from sparse-channel EEG signals. The YOAS totally consists of four sequential stages: Data Preparation, Data Preprocessing, Biased-EEG Generation, and Synthetic EEG Generation. Data Preparation and Preprocessing carefully consider the distribution of EEG electrodes and low signal-to-noise ratio problem of EEG signals. Biased-EEG Generation includes sub-modules of BiasEEGGanFormer and BiasEEGDiffFormer, which facilitate long-term feature extraction with attention and generate signals by combining electrode position alignment with diffusion model, respectively. Synthetic EEG Generation synthesizes the final signals, employing a deduction paradigm for multi-channel EEG generation. Extensive experiments confirmed YOAS's feasibility, efficiency, and theoretical validity, even remarkably enhancing data discernibility. This breakthrough in dense-channel EEG signal generation from sparse-channel data opens new avenues for exploration in EEG signal processing and application.
MM-GTUNets: Unified Multi-Modal Graph Deep Learning for Brain Disorders Prediction
Jun 20, 2024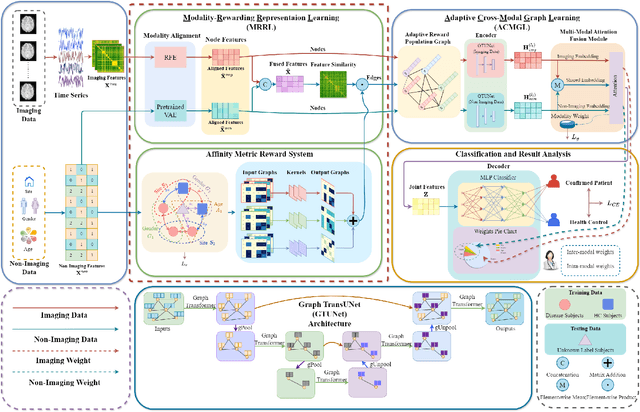

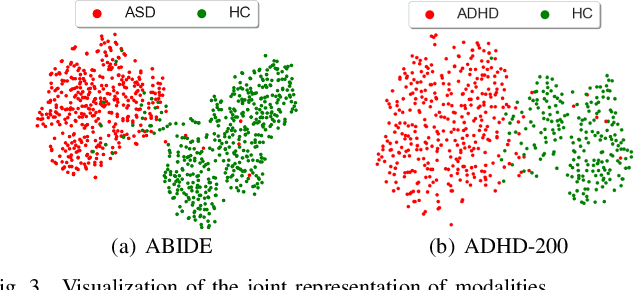
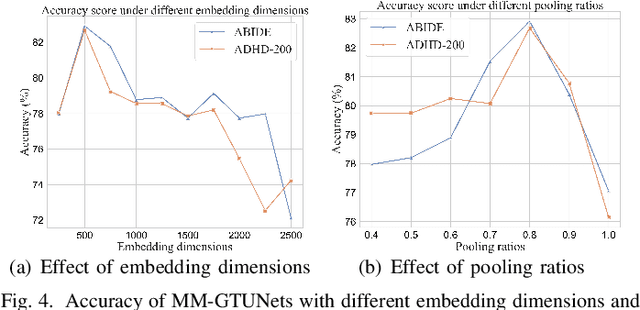
Graph deep learning (GDL) has demonstrated impressive performance in predicting population-based brain disorders (BDs) through the integration of both imaging and non-imaging data. However, the effectiveness of GDL based methods heavily depends on the quality of modeling the multi-modal population graphs and tends to degrade as the graph scale increases. Furthermore, these methods often constrain interactions between imaging and non-imaging data to node-edge interactions within the graph, overlooking complex inter-modal correlations, leading to suboptimal outcomes. To overcome these challenges, we propose MM-GTUNets, an end-to-end graph transformer based multi-modal graph deep learning (MMGDL) framework designed for brain disorders prediction at large scale. Specifically, to effectively leverage rich multi-modal information related to diseases, we introduce Modality Reward Representation Learning (MRRL) which adaptively constructs population graphs using a reward system. Additionally, we employ variational autoencoder to reconstruct latent representations of non-imaging features aligned with imaging features. Based on this, we propose Adaptive Cross-Modal Graph Learning (ACMGL), which captures critical modality-specific and modality-shared features through a unified GTUNet encoder taking advantages of Graph UNet and Graph Transformer, and feature fusion module. We validated our method on two public multi-modal datasets ABIDE and ADHD-200, demonstrating its superior performance in diagnosing BDs. Our code is available at https://github.com/NZWANG/MM-GTUNets.