 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Branch Reconstruction Network for Industrial Anomaly Detection with RGB-D Data
Nov 12, 2023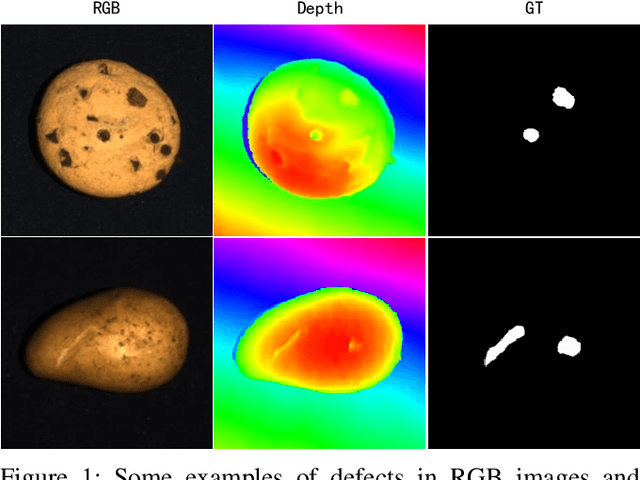
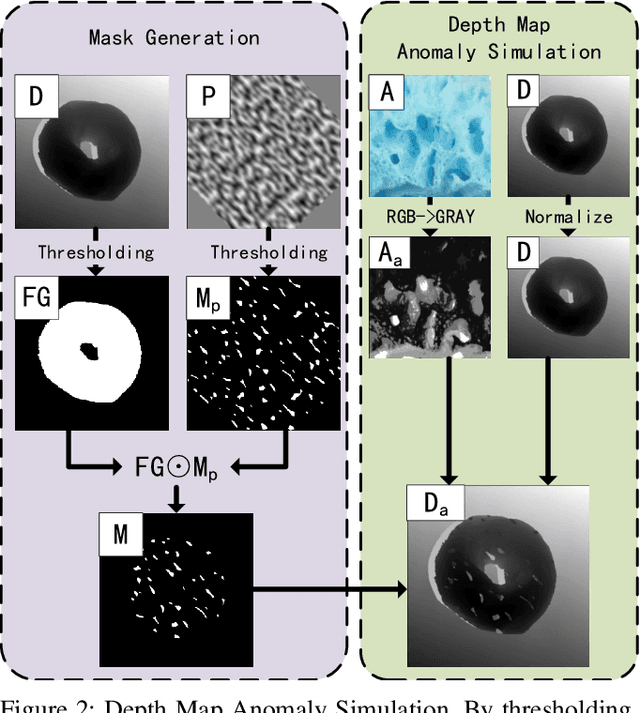
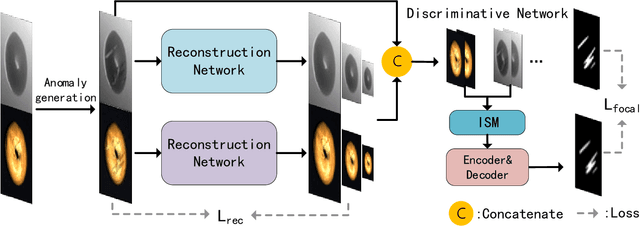
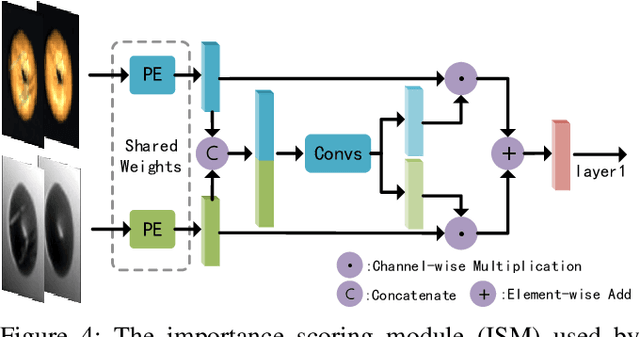
Unsupervised anomaly detection methods are at the forefront of industrial anomaly detection efforts and have made notable progress. Previous work primarily used 2D information as input, but multi-modal industrial anomaly detection based on 3D point clouds and RGB images is just beginning to emerge. The regular approach involves utilizing large pre-trained models for feature representation and storing them in memory banks. However, the above methods require a longer inference time and higher memory usage, which cannot meet the real-time requirements of the industry. To overcome these issues, we propose a lightweight dual-branch reconstruction network(DBRN) based on RGB-D input, learning the decision boundary between normal and abnormal examples. The requirement for alignment between the two modalities is eliminated by using depth maps instead of point cloud input. Furthermore, we introduce an importance scoring module in the discriminative network to assist in fusing features from these two modalities, thereby obtaining a comprehensive discriminative result. DBRN achieves 92.8% AUROC with high inference efficiency on the MVTec 3D-AD dataset without large pre-trained models and memory banks.
CL-Flow:Strengthening the Normalizing Flows by Contrastive Learning for Better Anomaly Detection
Nov 12, 2023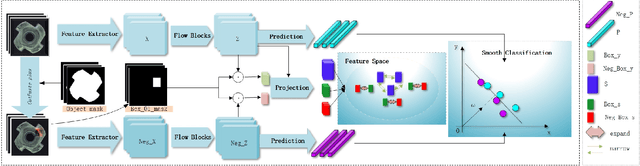

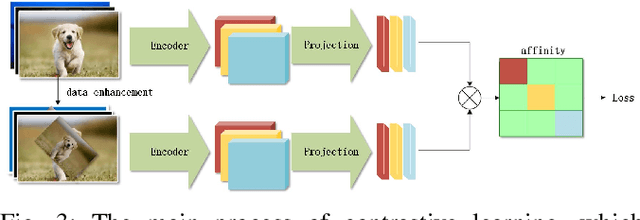
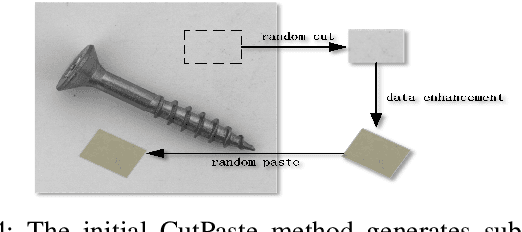
In the anomaly detection field, the scarcity of anomalous samples has directed the current research emphasis towards unsupervised anomaly detection. While these unsupervised anomaly detection methods offer convenience, they also overlook the crucial prior information embedded within anomalous samples. Moreover, among numerous deep learning methods, supervised methods generally exhibit superior performance compared to unsupervised methods. Considering the reasons mentioned above, we propose a self-supervised anomaly detection approach that combines contrastive learning with 2D-Flow to achieve more precise detection outcomes and expedited inference processes. On one hand, we introduce a novel approach to anomaly synthesis, yielding anomalous samples in accordance with authentic industrial scenarios, alongside their surrogate annotations. On the other hand, having obtained a substantial number of anomalous samples, we enhance the 2D-Flow framework by incorporating contrastive learning, leveraging diverse proxy tasks to fine-tune the network. Our approach enables the network to learn more precise mapping relationships from self-generated labels while retaining the lightweight characteristics of the 2D-Flow. Compared to mainstream unsupervised approaches, our self-supervised method demonstrates superior detection accuracy, fewer additional model parameters, and faster inference speed. Furthermore, the entire training and inference process is end-to-end. Our approach showcases new state-of-the-art results, achieving a performance of 99.6\% in image-level AUROC on the MVTecAD dataset and 96.8\% in image-level AUROC on the BTAD dataset.
Semantic Feature Integration network for Fine-grained Visual Classification
Feb 13, 2023

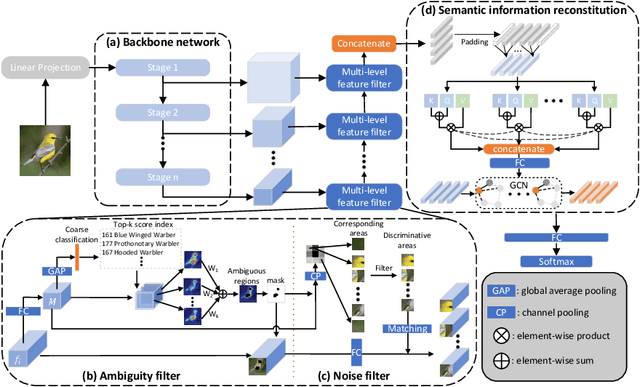

Fine-Grained Visual Classification (FGVC) is known as a challenging task due to subtle differences among subordinate categories. Many current FGVC approaches focus on identifying and locating discriminative regions by using the attention mechanism, but neglect the presence of unnecessary features that hinder the understanding of object structure. These unnecessary features, including 1) ambiguous parts resulting from the visual similarity in object appearances and 2) noninformative parts (e.g., background noise), can have a significant adverse impact on classification results. In this paper, we propose the Semantic Feature Integration network (SFI-Net) to address the above difficulties. By eliminating unnecessary features and reconstructing the semantic relations among discriminative features, our SFI-Net has achieved satisfying performance. The network consists of two modules: 1) the multi-level feature filter (MFF) module is proposed to remove unnecessary features with different receptive field, and then concatenate the preserved features on pixel level for subsequent disposal; 2) the semantic information reconstitution (SIR) module is presented to further establish semantic relations among discriminative features obtained from the MFF module. These two modules are carefully designed to be light-weighted and can be trained end-to-end in a weakly-supervised way. Extensive experiments on four challenging fine-grained benchmarks demonstrate that our proposed SFI-Net achieves the state-of-the-arts performance. Especially, the classification accuracy of our model on CUB-200-2011 and Stanford Dogs reaches 92.64% and 93.03%, respectively.