 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Feature Integration network for Fine-grained Visual Classification
Paper and Code
Feb 13, 2023

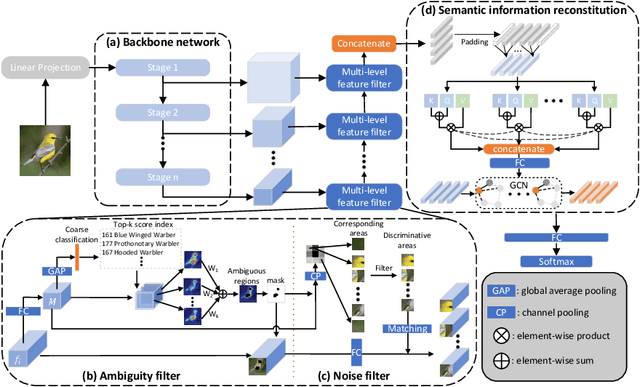

Fine-Grained Visual Classification (FGVC) is known as a challenging task due to subtle differences among subordinate categories. Many current FGVC approaches focus on identifying and locating discriminative regions by using the attention mechanism, but neglect the presence of unnecessary features that hinder the understanding of object structure. These unnecessary features, including 1) ambiguous parts resulting from the visual similarity in object appearances and 2) noninformative parts (e.g., background noise), can have a significant adverse impact on classification results. In this paper, we propose the Semantic Feature Integration network (SFI-Net) to address the above difficulties. By eliminating unnecessary features and reconstructing the semantic relations among discriminative features, our SFI-Net has achieved satisfying performance. The network consists of two modules: 1) the multi-level feature filter (MFF) module is proposed to remove unnecessary features with different receptive field, and then concatenate the preserved features on pixel level for subsequent disposal; 2) the semantic information reconstitution (SIR) module is presented to further establish semantic relations among discriminative features obtained from the MFF module. These two modules are carefully designed to be light-weighted and can be trained end-to-end in a weakly-supervised way. Extensive experiments on four challenging fine-grained benchmarks demonstrate that our proposed SFI-Net achieves the state-of-the-arts performance. Especially, the classification accuracy of our model on CUB-200-2011 and Stanford Dogs reaches 92.64% and 93.03%, respectively.