 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Goal-Conditioned Reinforcement Learning under Hybrid Contact Dynamics
May 28, 2026Learning to reach arbitrary goals from sparse feedback requires agents to infer a rich notion of reachability across state--goal pairs. Goal-conditioned reinforcement learning (GCRL) tackles this challenge by learning policies that generalize across goals, but this generalization becomes increasingly difficult as the underlying dynamics become high-dimensional, hybrid, or contact-dependent. To address this issue, physics-informed GCRL (Pi-GCRL) introduces optimal-control-inspired inductive biases into goal-conditioned value learning. While Pi-GCRL methods have proven effective in navigation and object-free goal-reaching domains, their reliability in contact-rich tasks remains unclear, where contact interactions induce hybrid dynamics, mode-dependent controllability, and nonsmooth value landscapes. In this work, we show that these structural properties can cause existing Pi-GCRL methods to degrade when applied naively to contact-rich manipulation. Motivated by this analysis, we introduce contact-aware and hierarchical formulations that apply physics-informed inductive biases selectively across the manipulation problem. Our results provide a principled step toward extending Pi-GCRL to contact-rich manipulation.
Weakly-supervised Learning for Physics-informed Neural Motion Planning via Sparse Roadmap
Apr 14, 2026The motion planning problem requires finding a collision-free path between start and goal configurations in high-dimensional, cluttered spaces. Recent learning-based methods offer promising solutions, with self-supervised physics-informed approaches such as Neural Time Fields (NTFields) solving the Eikonal equation to learn value functions without expert demonstrations. However, existing physics-informed methods struggle to scale in complex, multi-room environments, where simply increasing the number of samples cannot resolve local minima or guarantee global consistency. We propose Hierarchical Neural Time Fields (H-NTFields), a weakly-supervised framework that combines weak supervision from sparse roadmaps with physics-informed PDE regularization. The roadmap provides global topological anchors through upper and lower bounds on travel times, while PDE losses enforce local geometric fidelity and obstacle-aware propagation. Experiments on 18 Gibson environments and real robotic platforms show that H-NTFields substantially improves robustness over prior physics-informed methods, while enabling fast amortized inference through a continuous value representation.
Graph-of-Constraints Model Predictive Control for Reactive Multi-agent Task and Motion Planning
Mar 19, 2026Sequences of interdependent geometric constraints are central to many multi-agent Task and Motion Planning (TAMP) problems. However, existing methods for handling such constraint sequences struggle with partially ordered tasks and dynamic agent assignments. They typically assume static assignments and cannot adapt when disturbances alter task allocations. To overcome these limitations, we introduce Graph-of-Constraints Model Predictive Control (GoC-MPC), a generalized sequence-of-constraints framework integrated with MPC. GoC-MPC naturally supports partially ordered tasks, dynamic agent coordination, and disturbance recovery. By defining constraints over tracked 3D keypoints, our method robustly solves diverse multi-agent manipulation tasks-coordinating agents and adapting online from visual observations alone, without relying on training data or environment models. Experiments demonstrate that GoC-MPC achieves higher success rates, significantly faster TAMP computation, and shorter overall paths compared to recent baselines, establishing it as an efficient and robust solution for multi-agent manipulation under real-world disturbances. Our supplementary video and code can be found at https://sites.google.com/view/goc-mpc/home .
PPGuide: Steering Diffusion Policies with Performance Predictive Guidance
Mar 11, 2026Diffusion policies have shown to be very efficient at learning complex, multi-modal behaviors for robotic manipulation. However, errors in generated action sequences can compound over time which can potentially lead to failure. Some approaches mitigate this by augmenting datasets with expert demonstrations or learning predictive world models which might be computationally expensive. We introduce Performance Predictive Guidance (PPGuide), a lightweight, classifier-based framework that steers a pre-trained diffusion policy away from failure modes at inference time. PPGuide makes use of a novel self-supervised process: it uses attention-based multiple instance learning to automatically estimate which observation-action chunks from the policy's rollouts are relevant to success or failure. We then train a performance predictor on this self-labeled data. During inference, this predictor provides a real-time gradient to guide the policy toward more robust actions. We validated our proposed PPGuide across a diverse set of tasks from the Robomimic and MimicGen benchmarks, demonstrating consistent improvements in performance.
Multi-Agent Monte Carlo Tree Search for Makespan-Efficient Object Rearrangement in Cluttered Spaces
Feb 02, 2026Object rearrangement planning in complex, cluttered environments is a common challenge in warehouses, households, and rescue sites. Prior studies largely address monotone instances, whereas real-world tasks are often non-monotone-objects block one another and must be temporarily relocated to intermediate positions before reaching their final goals. In such settings, effective multi-agent collaboration can substantially reduce the time required to complete tasks. This paper introduces Centralized, Asynchronous, Multi-agent Monte Carlo Tree Search (CAM-MCTS), a novel framework for general-purpose makespan-efficient object rearrangement planning in challenging environments. CAM-MCTS combines centralized task assignment-where agents remain aware of each other's intended actions to facilitate globally optimized planning-with an asynchronous task execution strategy that enables agents to take on new tasks at appropriate time steps, rather than waiting for others, guided by a one-step look-ahead cost estimate. This design minimizes idle time, prevents unnecessary synchronization delays, and enhances overall system efficiency. We evaluate CAM-MCTS across a diverse set of monotone and non-monotone tasks in cluttered environments, demonstrating consistent reductions in makespan compared to strong baselines. Finally, we validate our approach on a real-world multi-agent system under different configurations, further confirming its effectiveness and robustness.
Goal Reaching with Eikonal-Constrained Hierarchical Quasimetric Reinforcement Learning
Dec 12, 2025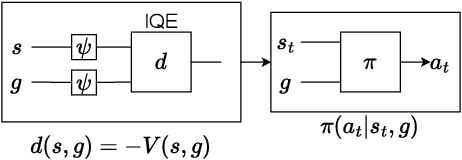
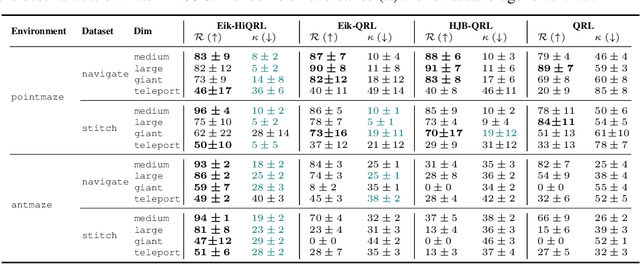

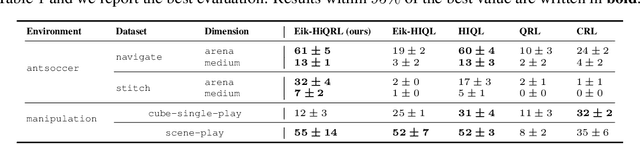
Goal-Conditioned Reinforcement Learning (GCRL) mitigates the difficulty of reward design by framing tasks as goal reaching rather than maximizing hand-crafted reward signals. In this setting, the optimal goal-conditioned value function naturally forms a quasimetric, motivating Quasimetric RL (QRL), which constrains value learning to quasimetric mappings and enforces local consistency through discrete, trajectory-based constraints. We propose Eikonal-Constrained Quasimetric RL (Eik-QRL), a continuous-time reformulation of QRL based on the Eikonal Partial Differential Equation (PDE). This PDE-based structure makes Eik-QRL trajectory-free, requiring only sampled states and goals, while improving out-of-distribution generalization. We provide theoretical guarantees for Eik-QRL and identify limitations that arise under complex dynamics. To address these challenges, we introduce Eik-Hierarchical QRL (Eik-HiQRL), which integrates Eik-QRL into a hierarchical decomposition. Empirically, Eik-HiQRL achieves state-of-the-art performance in offline goal-conditioned navigation and yields consistent gains over QRL in manipulation tasks, matching temporal-difference methods.
Manifold-constrained Hamilton-Jacobi Reachability Learning for Decentralized Multi-Agent Motion Planning
Nov 05, 2025Safe multi-agent motion planning (MAMP) under task-induced constraints is a critical challenge in robotics. Many real-world scenarios require robots to navigate dynamic environments while adhering to manifold constraints imposed by tasks. For example, service robots must carry cups upright while avoiding collisions with humans or other robots. Despite recent advances in decentralized MAMP for high-dimensional systems, incorporating manifold constraints remains difficult. To address this, we propose a manifold-constrained Hamilton-Jacobi reachability (HJR) learning framework for decentralized MAMP. Our method solves HJR problems under manifold constraints to capture task-aware safety conditions, which are then integrated into a decentralized trajectory optimization planner. This enables robots to generate motion plans that are both safe and task-feasible without requiring assumptions about other agents' policies. Our approach generalizes across diverse manifold-constrained tasks and scales effectively to high-dimensional multi-agent manipulation problems. Experiments show that our method outperforms existing constrained motion planners and operates at speeds suitable for real-world applications. Video demonstrations are available at https://youtu.be/RYcEHMnPTH8 .
Automaton Constrained Q-Learning
Oct 06, 2025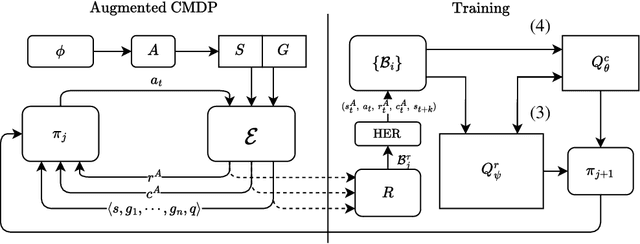
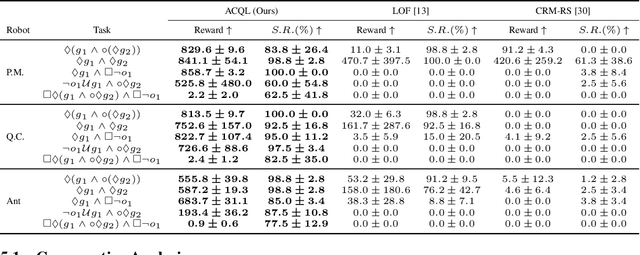

Real-world robotic tasks often require agents to achieve sequences of goals while respecting time-varying safety constraints. However, standard Reinforcement Learning (RL) paradigms are fundamentally limited in these settings. A natural approach to these problems is to combine RL with Linear-time Temporal Logic (LTL), a formal language for specifying complex, temporally extended tasks and safety constraints. Yet, existing RL methods for LTL objectives exhibit poor empirical performance in complex and continuous environments. As a result, no scalable methods support both temporally ordered goals and safety simultaneously, making them ill-suited for realistic robotics scenarios. We propose Automaton Constrained Q-Learning (ACQL), an algorithm that addresses this gap by combining goal-conditioned value learning with automaton-guided reinforcement. ACQL supports most LTL task specifications and leverages their automaton representation to explicitly encode stage-wise goal progression and both stationary and non-stationary safety constraints. We show that ACQL outperforms existing methods across a range of continuous control tasks, including cases where prior methods fail to satisfy either goal-reaching or safety constraints. We further validate its real-world applicability by deploying ACQL on a 6-DOF robotic arm performing a goal-reaching task in a cluttered, cabinet-like space with safety constraints. Our results demonstrate that ACQL is a robust and scalable solution for learning robotic behaviors according to rich temporal specifications.
Online Hierarchical Policy Learning using Physics Priors for Robot Navigation in Unknown Environments
Oct 01, 2025Robot navigation in large, complex, and unknown indoor environments is a challenging problem. The existing approaches, such as traditional sampling-based methods, struggle with resolution control and scalability, while imitation learning-based methods require a large amount of demonstration data. Active Neural Time Fields (ANTFields) have recently emerged as a promising solution by using local observations to learn cost-to-go functions without relying on demonstrations. Despite their potential, these methods are hampered by challenges such as spectral bias and catastrophic forgetting, which diminish their effectiveness in complex scenarios. To address these issues, our approach decomposes the planning problem into a hierarchical structure. At the high level, a sparse graph captures the environment's global connectivity, while at the low level, a planner based on neural fields navigates local obstacles by solving the Eikonal PDE. This physics-informed strategy overcomes common pitfalls like spectral bias and neural field fitting difficulties, resulting in a smooth and precise representation of the cost landscape. We validate our framework in large-scale environments, demonstrating its enhanced adaptability and precision compared to previous methods, and highlighting its potential for online exploration, mapping, and real-world navigation.
Continuous-Time Value Iteration for Multi-Agent Reinforcement Learning
Sep 11, 2025
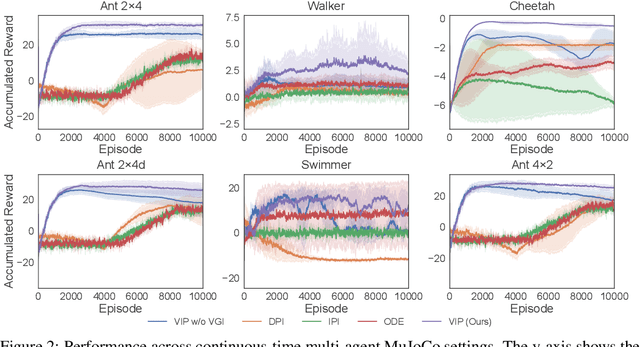

Existing reinforcement learning (RL) methods struggle with complex dynamical systems that demand interactions at high frequencies or irregular time intervals. Continuous-time RL (CTRL) has emerged as a promising alternative by replacing discrete-time Bellman recursion with differential value functions defined as viscosity solutions of the Hamilton--Jacobi--Bellman (HJB) equation. While CTRL has shown promise, its applications have been largely limited to the single-agent domain. This limitation stems from two key challenges: (i) conventional solution methods for HJB equations suffer from the curse of dimensionality (CoD), making them intractable in high-dimensional systems; and (ii) even with HJB-based learning approaches, accurately approximating centralized value functions in multi-agent settings remains difficult, which in turn destabilizes policy training. In this paper, we propose a CT-MARL framework that uses physics-informed neural networks (PINNs) to approximate HJB-based value functions at scale. To ensure the value is consistent with its differential structure, we align value learning with value-gradient learning by introducing a Value Gradient Iteration (VGI) module that iteratively refines value gradients along trajectories. This improves gradient fidelity, in turn yielding more accurate values and stronger policy learning. We evaluate our method using continuous-time variants of standard benchmarks, including multi-agent particle environment (MPE) and multi-agent MuJoCo. Our results demonstrate that our approach consistently outperforms existing continuous-time RL baselines and scales to complex multi-agent dynamics.