 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-UGCN: A Unified Graph Convolutional Network for Robust 3D Human Pose Estimation from Monocular RGB Images
Jul 23, 2024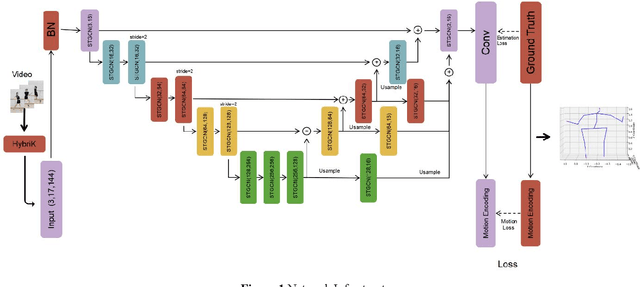
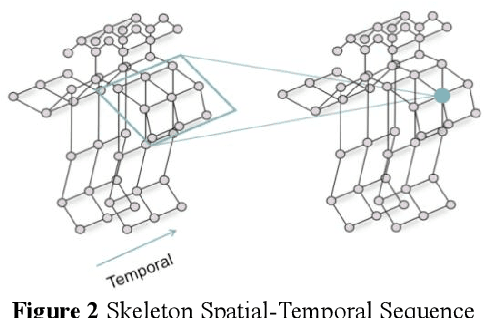
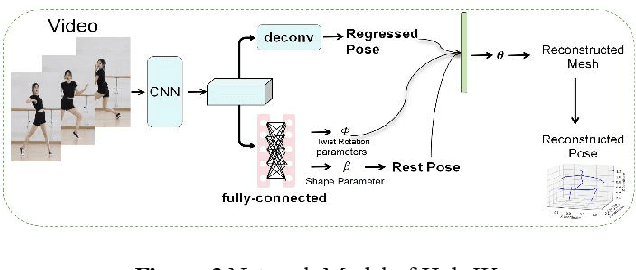
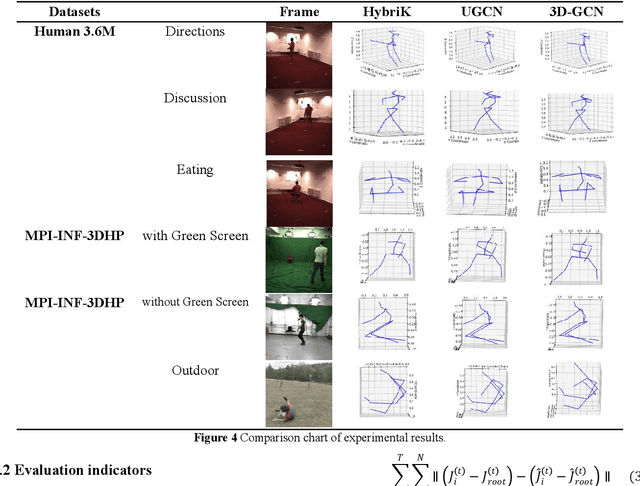
Human pose estimation remains a multifaceted challenge in computer vision, pivotal across diverse domains such as behavior recognition, human-computer interaction, and pedestrian tracking. This paper proposes an improved method based on the spatial-temporal graph convolution net-work (UGCN) to address the issue of missing human posture skeleton sequences in single-view videos. We present the improved UGCN, which allows the network to process 3D human pose data and improves the 3D human pose skeleton sequence, thereby resolving the occlusion issue.
Language-guided Active Sensing of Confined, Cluttered Environments via Object Rearrangement Planning
Feb 04, 2024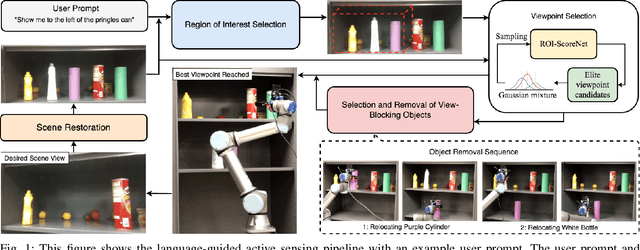

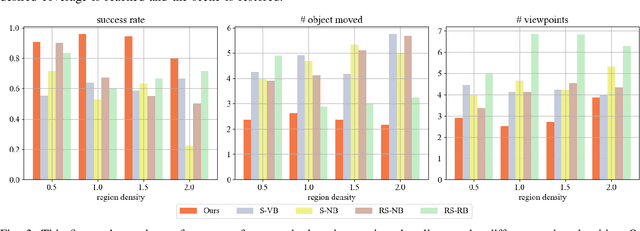
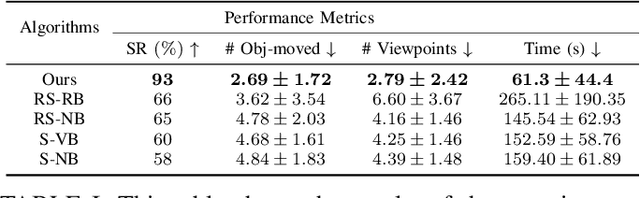
Language-guided active sensing is a robotics subtask where a robot with an onboard sensor interacts efficiently with the environment via object manipulation to maximize perceptual information, following given language instructions. These tasks appear in various practical robotics applications, such as household service, search and rescue, and environment monitoring. Despite many applications, the existing works do not account for language instructions and have mainly focused on surface sensing, i.e., perceiving the environment from the outside without rearranging it for dense sensing. Therefore, in this paper, we introduce the first language-guided active sensing approach that allows users to observe specific parts of the environment via object manipulation. Our method spatially associates the environment with language instructions, determines the best camera viewpoints for perception, and then iteratively selects and relocates the best view-blocking objects to provide the dense perception of the region of interest. We evaluate our method against different baseline algorithms in simulation and also demonstrate it in real-world confined cabinet-like settings with multiple unknown objects. Our results show that the proposed method exhibits better performance across different metrics and successfully generalizes to real-world complex scenarios.
Towards Mixed-Precision Quantization of Neural Networks via Constrained Optimization
Oct 13, 2021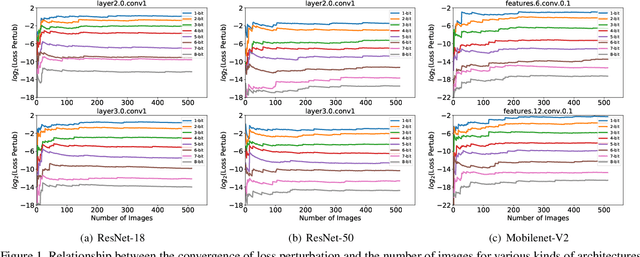
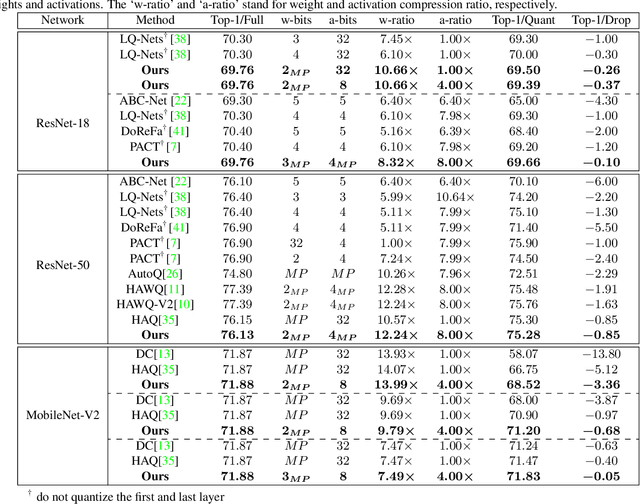
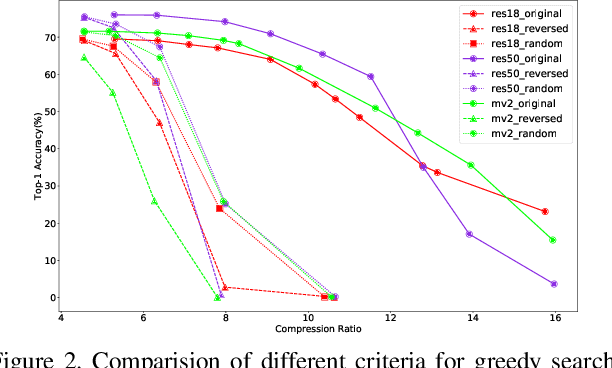
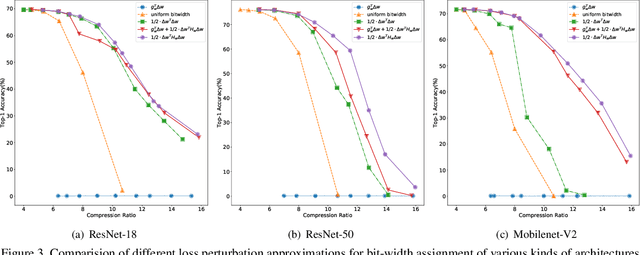
Quantization is a widely used technique to compress and accelerate deep neural networks. However, conventional quantization methods use the same bit-width for all (or most of) the layers, which often suffer significant accuracy degradation in the ultra-low precision regime and ignore the fact that emergent hardware accelerators begin to support mixed-precision computation. Consequently, we present a novel and principled framework to solve the mixed-precision quantization problem in this paper. Briefly speaking, we first formulate the mixed-precision quantization as a discrete constrained optimization problem. Then, to make the optimization tractable, we approximate the objective function with second-order Taylor expansion and propose an efficient approach to compute its Hessian matrix. Finally, based on the above simplification, we show that the original problem can be reformulated as a Multiple-Choice Knapsack Problem (MCKP) and propose a greedy search algorithm to solve it efficiently. Compared with existing mixed-precision quantization works, our method is derived in a principled way and much more computationally efficient. Moreover, extensive experiments conducted on the ImageNet dataset and various kinds of network architectures also demonstrate its superiority over existing uniform and mixed-precision quantization approaches.