Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-UGCN: A Unified Graph Convolutional Network for Robust 3D Human Pose Estimation from Monocular RGB Images
Jul 23, 2024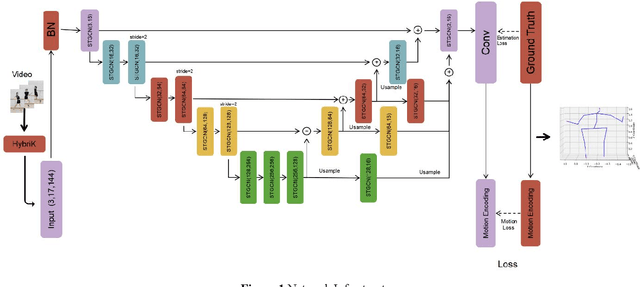
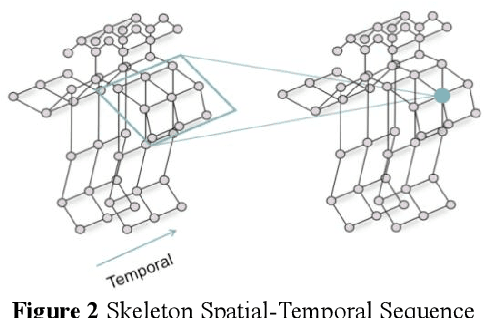
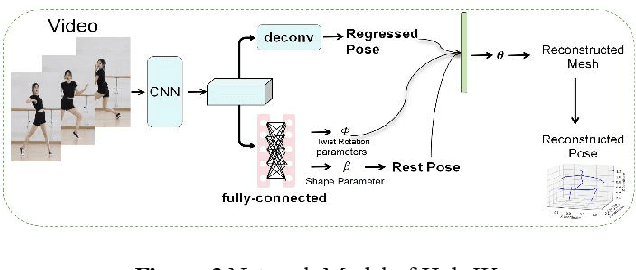
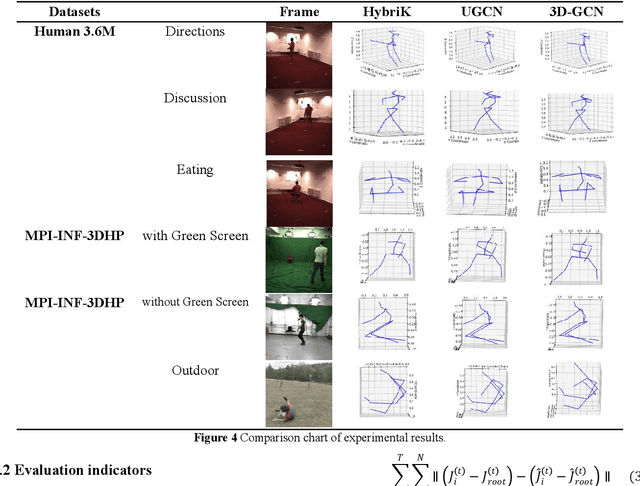
Human pose estimation remains a multifaceted challenge in computer vision, pivotal across diverse domains such as behavior recognition, human-computer interaction, and pedestrian tracking. This paper proposes an improved method based on the spatial-temporal graph convolution net-work (UGCN) to address the issue of missing human posture skeleton sequences in single-view videos. We present the improved UGCN, which allows the network to process 3D human pose data and improves the 3D human pose skeleton sequence, thereby resolving the occlusion issue.
* Proceedings of IEEE AICON2024
Via