 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassive iFIR filters for data-driven velocity control in robotics
Mar 31, 2026We present a passive, data-driven velocity control method for nonlinear robotic manipulators that achieves better tracking performance than optimized PID with comparable design complexity. Using only three minutes of probing data, a VRFT-based design identifies passive iFIR controllers that (i) preserve closed-loop stability via passivity constraints and (ii) outperform a VRFT-tuned PID baseline on the Franka Research 3 robot in both joint-space and Cartesian-space velocity control, achieving up to a 74.5% reduction in tracking error for the Cartesian velocity tracking experiment with the most demanding reference model. When the robot end-effector dynamics change, the controller can be re-learned from new data, regaining nominal performance. This study bridges learning-based control and stability-guaranteed design: passive iFIR learns from data while retaining passivity-based stability guarantees, unlike many learning-based approaches.
SkillTester: Benchmarking Utility and Security of Agent Skills
Mar 28, 2026This technical report presents SkillTester, a tool for evaluating the utility and security of agent skills. Its evaluation framework combines paired baseline and with-skill execution conditions with a separate security probe suite. Grounded in a comparative utility principle and a user-facing simplicity principle, the framework normalizes raw execution artifacts into a utility score, a security score, and a three-level security status label. More broadly, it can be understood as a comparative quality-assurance harness for agent skills in an agent-first world. The public service is deployed at https://skilltester.ai, and the broader project is maintained at https://github.com/skilltester-ai/skilltester.
ExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Mar 16, 2026Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
PPGuide: Steering Diffusion Policies with Performance Predictive Guidance
Mar 11, 2026Diffusion policies have shown to be very efficient at learning complex, multi-modal behaviors for robotic manipulation. However, errors in generated action sequences can compound over time which can potentially lead to failure. Some approaches mitigate this by augmenting datasets with expert demonstrations or learning predictive world models which might be computationally expensive. We introduce Performance Predictive Guidance (PPGuide), a lightweight, classifier-based framework that steers a pre-trained diffusion policy away from failure modes at inference time. PPGuide makes use of a novel self-supervised process: it uses attention-based multiple instance learning to automatically estimate which observation-action chunks from the policy's rollouts are relevant to success or failure. We then train a performance predictor on this self-labeled data. During inference, this predictor provides a real-time gradient to guide the policy toward more robust actions. We validated our proposed PPGuide across a diverse set of tasks from the Robomimic and MimicGen benchmarks, demonstrating consistent improvements in performance.
FlowDet: Overcoming Perspective and Scale Challenges in Real-Time End-to-End Traffic Detection
Aug 27, 2025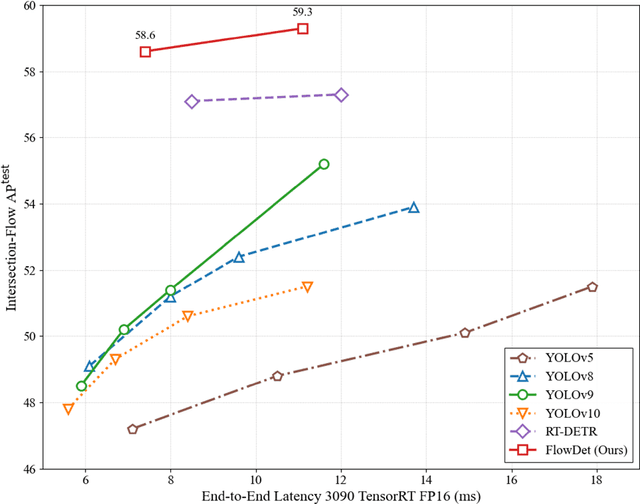
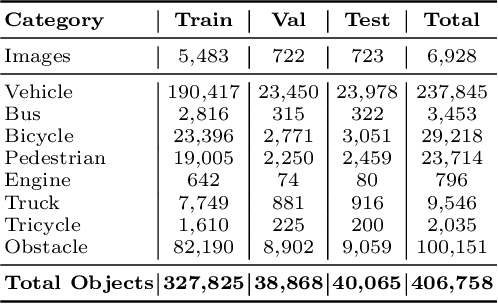
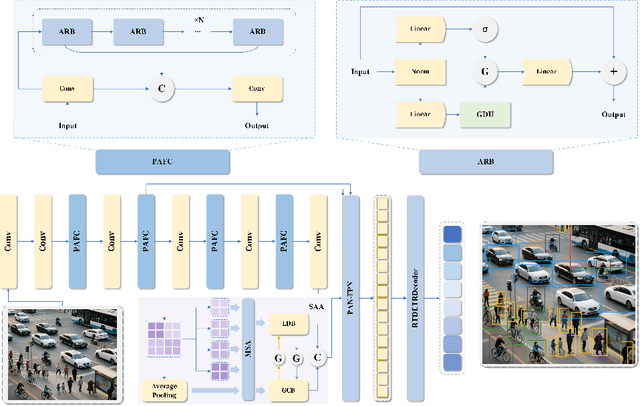
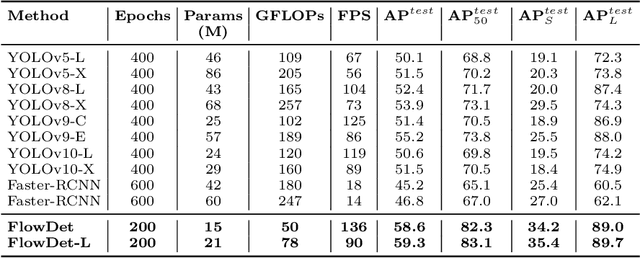
End-to-end object detectors offer a promising NMS-free paradigm for real-time applications, yet their high computational cost remains a significant barrier, particularly for complex scenarios like intersection traffic monitoring. To address this challenge, we propose FlowDet, a high-speed detector featuring a decoupled encoder optimization strategy applied to the DETR architecture. Specifically, FlowDet employs a novel Geometric Deformable Unit (GDU) for traffic-aware geometric modeling and a Scale-Aware Attention (SAA) module to maintain high representational power across extreme scale variations. To rigorously evaluate the model's performance in environments with severe occlusion and high object density, we collected the Intersection-Flow-5k dataset, a new challenging scene for this task. Evaluated on Intersection-Flow-5k, FlowDet establishes a new state-of-the-art. Compared to the strong RT-DETR baseline, it improves AP(test) by 1.5% and AP50(test) by 1.6%, while simultaneously reducing GFLOPs by 63.2% and increasing inference speed by 16.2%. Our work demonstrates a new path towards building highly efficient and accurate detectors for demanding, real-world perception systems. The Intersection-Flow-5k dataset is available at https://github.com/AstronZh/Intersection-Flow-5K.
Dynamic Robot Tool Use with Vision Language Models
May 02, 2025Tool use enhances a robot's task capabilities. Recent advances in vision-language models (VLMs) have equipped robots with sophisticated cognitive capabilities for tool-use applications. However, existing methodologies focus on elementary quasi-static tool manipulations or high-level tool selection while neglecting the critical aspect of task-appropriate tool grasping. To address this limitation, we introduce inverse Tool-Use Planning (iTUP), a novel VLM-driven framework that enables grounded fine-grained planning for versatile robotic tool use. Through an integrated pipeline of VLM-based tool and contact point grounding, position-velocity trajectory planning, and physics-informed grasp generation and selection, iTUP demonstrates versatility across (1) quasi-static and more challenging (2) dynamic and (3) cluster tool-use tasks. To ensure robust planning, our framework integrates stable and safe task-aware grasping by reasoning over semantic affordances and physical constraints. We evaluate iTUP and baselines on a comprehensive range of realistic tool use tasks including precision hammering, object scooping, and cluster sweeping. Experimental results demonstrate that iTUP ensures a thorough grounding of cognition and planning for challenging robot tool use across diverse environments.
Implicit Physics-aware Policy for Dynamic Manipulation of Rigid Objects via Soft Body Tools
Feb 08, 2025



Recent advancements in robot tool use have unlocked their usage for novel tasks, yet the predominant focus is on rigid-body tools, while the investigation of soft-body tools and their dynamic interaction with rigid bodies remains unexplored. This paper takes a pioneering step towards dynamic one-shot soft tool use for manipulating rigid objects, a challenging problem posed by complex interactions and unobservable physical properties. To address these problems, we propose the Implicit Physics-aware (IPA) policy, designed to facilitate effective soft tool use across various environmental configurations. The IPA policy conducts system identification to implicitly identify physics information and predict goal-conditioned, one-shot actions accordingly. We validate our approach through a challenging task, i.e., transporting rigid objects using soft tools such as ropes to distant target positions in a single attempt under unknown environment physics parameters. Our experimental results indicate the effectiveness of our method in efficiently identifying physical properties, accurately predicting actions, and smoothly generalizing to real-world environments. The related video is available at: https://youtu.be/4hPrUDTc4Rg?si=WUZrT2vjLMt8qRWA
Passive iFIR filters for data-driven control
Mar 11, 2024



We consider the design of a new class of passive iFIR controllers given by the parallel action of an integrator and a finite impulse response filter. iFIRs are more expressive than PID controllers but retain their features and simplicity. The paper provides a model-free data-driven design for passive iFIR controllers based on virtual reference feedback tuning. Passivity is enforced through constrained optimization (three different formulations are discussed). The proposed design does not rely on large datasets or accurate plant models.
DeRi-IGP: Manipulating Rigid Objects Using Deformable Objects via Iterative Grasp-Pull
Sep 09, 2023



Heterogeneous systems manipulation, i.e., manipulating rigid objects via deformable (soft) objects, is an emerging field that remains in its early stages of research. Existing works in this field suffer from limited action and operational space, poor generalization ability, and expensive development. To address these challenges, we propose a universally applicable and effective moving primitive, Iterative Grasp-Pull (IGP), and a sample-based framework, DeRi-IGP, to solve the heterogeneous system manipulation task. The DeRi-IGP framework uses local onboard robots' RGBD sensors to observe the environment, comprising a soft-rigid body system. It then uses this information to iteratively grasp and pull a soft body (e.g., rope) to move the attached rigid body to a desired location. We evaluate the effectiveness of our framework in solving various heterogeneous manipulation tasks and compare its performance with several state-of-the-art baselines. The result shows that DeRi-IGP outperforms other methods by a significant margin. In addition, we also demonstrate the advantage of the large operational space of IGP in the long-distance object acquisition task within both simulated and real environments.
AnyPose: Anytime 3D Human Pose Forecasting via Neural Ordinary Differential Equations
Sep 09, 2023Anytime 3D human pose forecasting is crucial to synchronous real-world human-machine interaction, where the term ``anytime" corresponds to predicting human pose at any real-valued time step. However, to the best of our knowledge, all the existing methods in human pose forecasting perform predictions at preset, discrete time intervals. Therefore, we introduce AnyPose, a lightweight continuous-time neural architecture that models human behavior dynamics with neural ordinary differential equations. We validate our framework on the Human3.6M, AMASS, and 3DPW dataset and conduct a series of comprehensive analyses towards comparison with existing methods and the intersection of human pose and neural ordinary differential equations. Our results demonstrate that AnyPose exhibits high-performance accuracy in predicting future poses and takes significantly lower computational time than traditional methods in solving anytime prediction tasks.