 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA perspective on multi-agent communication for information fusion
Nov 09, 2019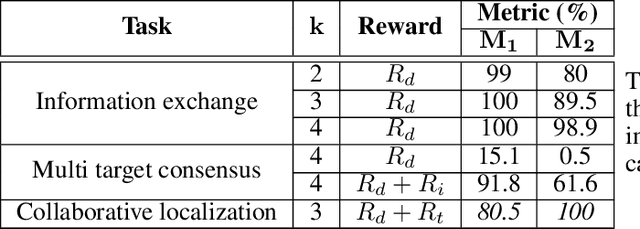
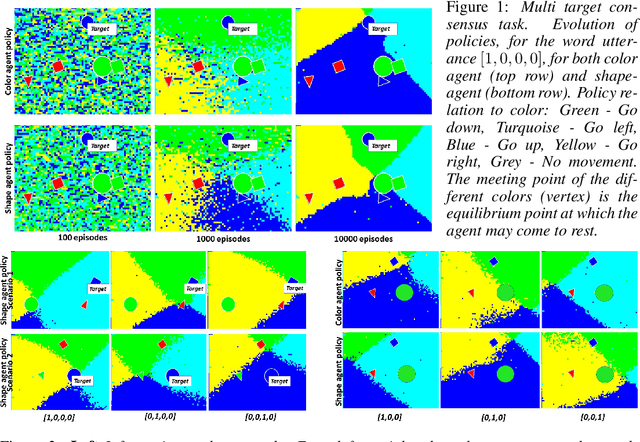
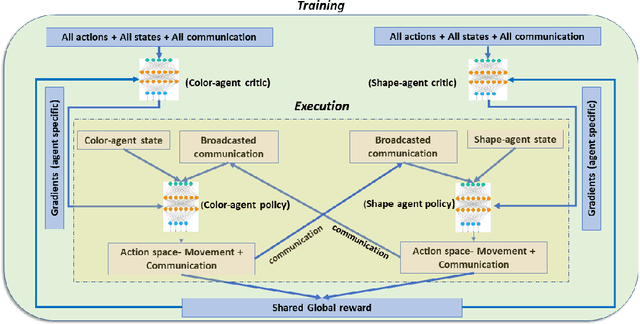

Collaborative decision making in multi-agent systems typically requires a predefined communication protocol among agents. Usually, agent-level observations are locally processed and information is exchanged using the predefined protocol, enabling the team to perform more efficiently than each agent operating in isolation. In this work, we consider the situation where agents, with complementary sensing modalities must co-operate to achieve a common goal/task by learning an efficient communication protocol. We frame the problem within an actor-critic scheme, where the agents learn optimal policies in a centralized fashion, while taking action in a distributed manner. We provide an interpretation of the emergent communication between the agents. We observe that the information exchanged is not just an encoding of the raw sensor data but is, rather, a specific set of directive actions that depend on the overall task. Simulation results demonstrate the interpretability of the learnt communication in a variety of tasks.
ECO: Egocentric Cognitive Mapping
Dec 02, 2018


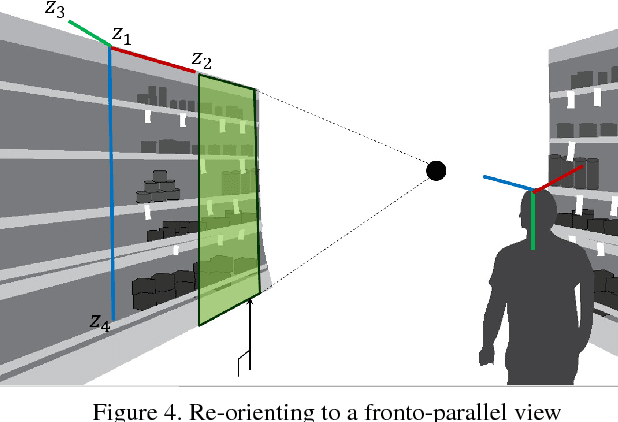
We present a new method to localize a camera within a previously unseen environment perceived from an egocentric point of view. Although this is, in general, an ill-posed problem, humans can effortlessly and efficiently determine their relative location and orientation and navigate into a previously unseen environments, e.g., finding a specific item in a new grocery store. To enable such a capability, we design a new egocentric representation, which we call ECO (Egocentric COgnitive map). ECO is biologically inspired, by the cognitive map that allows human navigation, and it encodes the surrounding visual semantics with respect to both distance and orientation. ECO possesses three main properties: (1) reconfigurability: complex semantics and geometry is captured via the synthesis of atomic visual representations (e.g., image patch); (2) robustness: the visual semantics are registered in a geometrically consistent way (e.g., aligning with respect to the gravity vector, frontalizing, and rescaling to canonical depth), thus enabling us to learn meaningful atomic representations; (3) adaptability: a domain adaptation framework is designed to generalize the learned representation without manual calibration. As a proof-of-concept, we use ECO to localize a camera within real-world scenes---various grocery stores---and demonstrate performance improvements when compared to existing semantic localization approaches.