 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021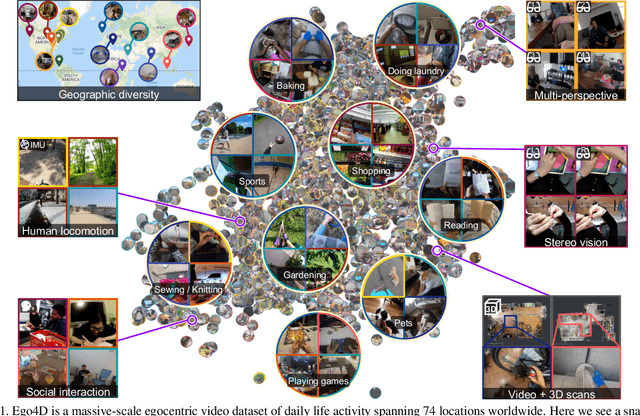
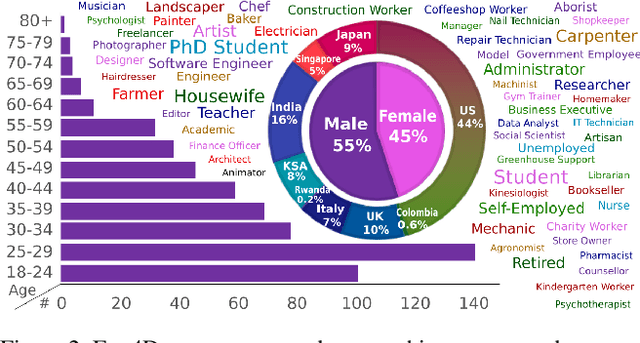

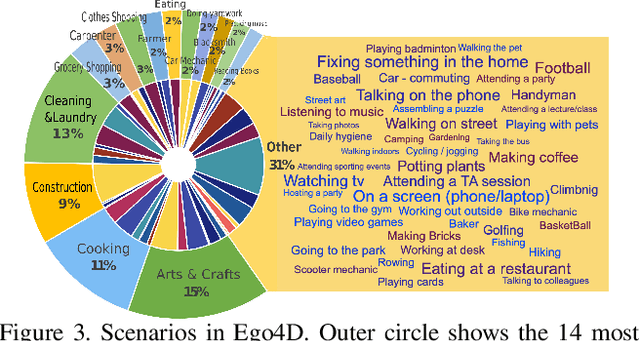
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
ECO: Egocentric Cognitive Mapping
Dec 02, 2018


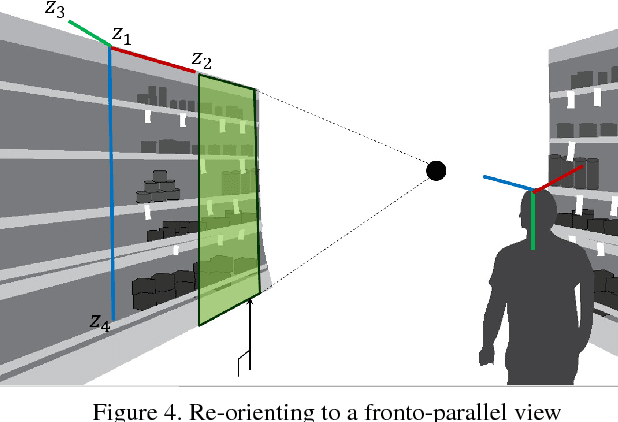
We present a new method to localize a camera within a previously unseen environment perceived from an egocentric point of view. Although this is, in general, an ill-posed problem, humans can effortlessly and efficiently determine their relative location and orientation and navigate into a previously unseen environments, e.g., finding a specific item in a new grocery store. To enable such a capability, we design a new egocentric representation, which we call ECO (Egocentric COgnitive map). ECO is biologically inspired, by the cognitive map that allows human navigation, and it encodes the surrounding visual semantics with respect to both distance and orientation. ECO possesses three main properties: (1) reconfigurability: complex semantics and geometry is captured via the synthesis of atomic visual representations (e.g., image patch); (2) robustness: the visual semantics are registered in a geometrically consistent way (e.g., aligning with respect to the gravity vector, frontalizing, and rescaling to canonical depth), thus enabling us to learn meaningful atomic representations; (3) adaptability: a domain adaptation framework is designed to generalize the learned representation without manual calibration. As a proof-of-concept, we use ECO to localize a camera within real-world scenes---various grocery stores---and demonstrate performance improvements when compared to existing semantic localization approaches.