 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratifying Reinforcement Learning with Signal Temporal Logic
Apr 06, 2026In this paper, we develop a stratification-based semantics for Signal Temporal Logic (STL) in which each atomic predicate is interpreted as a membership test in a stratified space. This perspective reveals a novel correspondence principle between stratification theory and STL, showing that most STL formulas can be viewed as inducing a stratification of space-time. The significance of this interpretation is twofold. First, it offers a fresh theoretical framework for analyzing the structure of the embedding space generated by deep reinforcement learning (DRL) and relates it to the geometry of the ambient decision space. Second, it provides a principled framework that both enables the reuse of existing high-dimensional analysis tools and motivates the creation of novel computational techniques. To ground the theory, we (1) illustrate the role of stratification theory in Minigrid games and (2) apply numerical techniques to the latent embeddings of a DRL agent playing such a game where the robustness of STL formulas is used as the reward. In the process, we propose computationally efficient signatures that, based on preliminary evidence, appear promising for uncovering the stratification structure of such embedding spaces.
Distributionally Robust Imitation Learning: Layered Control Architecture for Certifiable Autonomy
Dec 19, 2025Imitation learning (IL) enables autonomous behavior by learning from expert demonstrations. While more sample-efficient than comparative alternatives like reinforcement learning, IL is sensitive to compounding errors induced by distribution shifts. There are two significant sources of distribution shifts when using IL-based feedback laws on systems: distribution shifts caused by policy error and distribution shifts due to exogenous disturbances and endogenous model errors due to lack of learning. Our previously developed approaches, Taylor Series Imitation Learning (TaSIL) and $\mathcal{L}_1$ -Distributionally Robust Adaptive Control (\ellonedrac), address the challenge of distribution shifts in complementary ways. While TaSIL offers robustness against policy error-induced distribution shifts, \ellonedrac offers robustness against distribution shifts due to aleatoric and epistemic uncertainties. To enable certifiable IL for learned and/or uncertain dynamical systems, we formulate \textit{Distributionally Robust Imitation Policy (DRIP)} architecture, a Layered Control Architecture (LCA) that integrates TaSIL and~\ellonedrac. By judiciously designing individual layer-centric input and output requirements, we show how we can guarantee certificates for the entire control pipeline. Our solution paves the path for designing fully certifiable autonomy pipelines, by integrating learning-based components, such as perception, with certifiable model-based decision-making through the proposed LCA approach.
Exploring the Stratified Space Structure of an RL Game with the Volume Growth Transform
Jul 29, 2025



In this work, we explore the structure of the embedding space of a transformer model trained for playing a particular reinforcement learning (RL) game. Specifically, we investigate how a transformer-based Proximal Policy Optimization (PPO) model embeds visual inputs in a simple environment where an agent must collect "coins" while avoiding dynamic obstacles consisting of "spotlights." By adapting Robinson et al.'s study of the volume growth transform for LLMs to the RL setting, we find that the token embedding space for our visual coin collecting game is also not a manifold, and is better modeled as a stratified space, where local dimension can vary from point to point. We further strengthen Robinson's method by proving that fairly general volume growth curves can be realized by stratified spaces. Finally, we carry out an analysis that suggests that as an RL agent acts, its latent representation alternates between periods of low local dimension, while following a fixed sub-strategy, and bursts of high local dimension, where the agent achieves a sub-goal (e.g., collecting an object) or where the environmental complexity increases (e.g., more obstacles appear). Consequently, our work suggests that the distribution of dimensions in a stratified latent space may provide a new geometric indicator of complexity for RL games.
Epistemic Exploration for Generalizable Planning and Learning in Non-Stationary Settings
Feb 13, 2024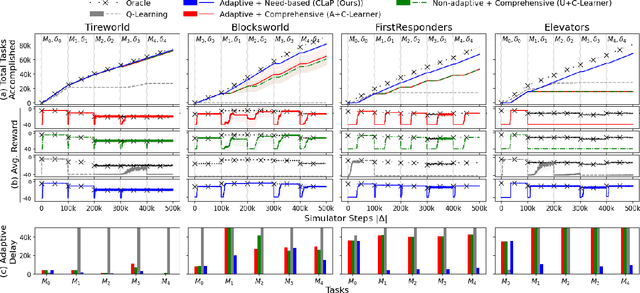
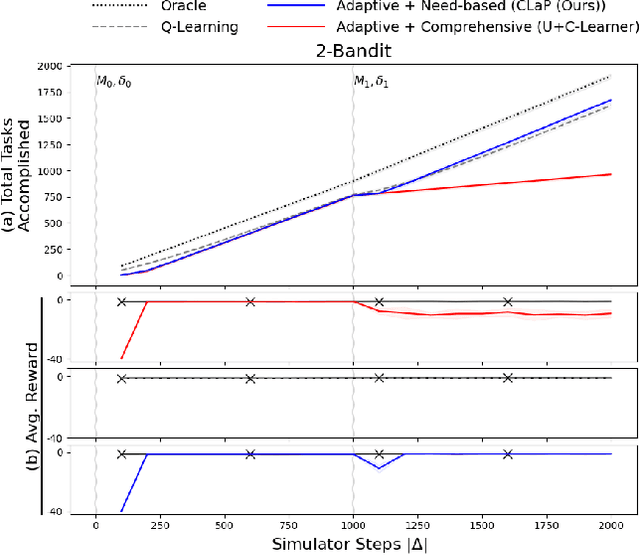
This paper introduces a new approach for continual planning and model learning in non-stationary stochastic environments expressed using relational representations. Such capabilities are essential for the deployment of sequential decision-making systems in the uncertain, constantly evolving real world. Working in such practical settings with unknown (and non-stationary) transition systems and changing tasks, the proposed framework models gaps in the agent's current state of knowledge and uses them to conduct focused, investigative explorations. Data collected using these explorations is used for learning generalizable probabilistic models for solving the current task despite continual changes in the environment dynamics. Empirical evaluations on several benchmark domains show that this approach significantly outperforms planning and RL baselines in terms of sample complexity in non-stationary settings. Theoretical results show that the system reverts to exhibit desirable convergence properties when stationarity holds.
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Dec 18, 2023



This paper proposes an approach to build 3D scene graphs in arbitrary (indoor and outdoor) environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., "a beach contains sand"), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
A perspective on multi-agent communication for information fusion
Nov 09, 2019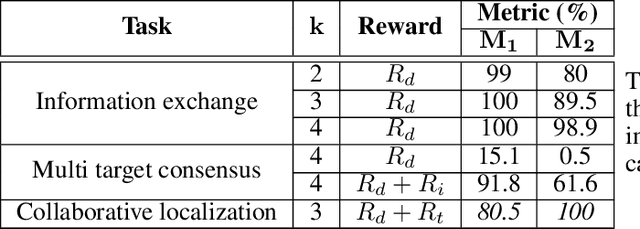
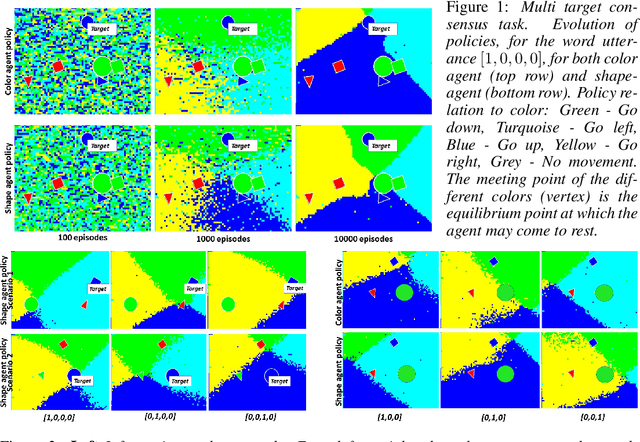
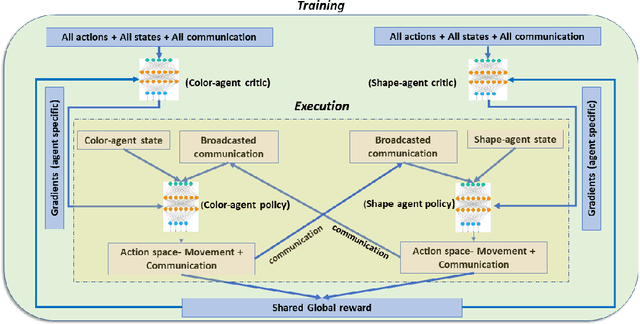

Collaborative decision making in multi-agent systems typically requires a predefined communication protocol among agents. Usually, agent-level observations are locally processed and information is exchanged using the predefined protocol, enabling the team to perform more efficiently than each agent operating in isolation. In this work, we consider the situation where agents, with complementary sensing modalities must co-operate to achieve a common goal/task by learning an efficient communication protocol. We frame the problem within an actor-critic scheme, where the agents learn optimal policies in a centralized fashion, while taking action in a distributed manner. We provide an interpretation of the emergent communication between the agents. We observe that the information exchanged is not just an encoding of the raw sensor data but is, rather, a specific set of directive actions that depend on the overall task. Simulation results demonstrate the interpretability of the learnt communication in a variety of tasks.
ECO: Egocentric Cognitive Mapping
Dec 02, 2018


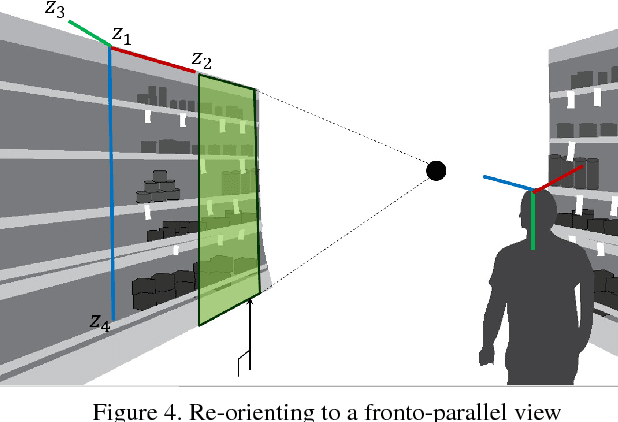
We present a new method to localize a camera within a previously unseen environment perceived from an egocentric point of view. Although this is, in general, an ill-posed problem, humans can effortlessly and efficiently determine their relative location and orientation and navigate into a previously unseen environments, e.g., finding a specific item in a new grocery store. To enable such a capability, we design a new egocentric representation, which we call ECO (Egocentric COgnitive map). ECO is biologically inspired, by the cognitive map that allows human navigation, and it encodes the surrounding visual semantics with respect to both distance and orientation. ECO possesses three main properties: (1) reconfigurability: complex semantics and geometry is captured via the synthesis of atomic visual representations (e.g., image patch); (2) robustness: the visual semantics are registered in a geometrically consistent way (e.g., aligning with respect to the gravity vector, frontalizing, and rescaling to canonical depth), thus enabling us to learn meaningful atomic representations; (3) adaptability: a domain adaptation framework is designed to generalize the learned representation without manual calibration. As a proof-of-concept, we use ECO to localize a camera within real-world scenes---various grocery stores---and demonstrate performance improvements when compared to existing semantic localization approaches.
Robust Belief Roadmap: Planning Under Intermittent Sensing
Sep 15, 2013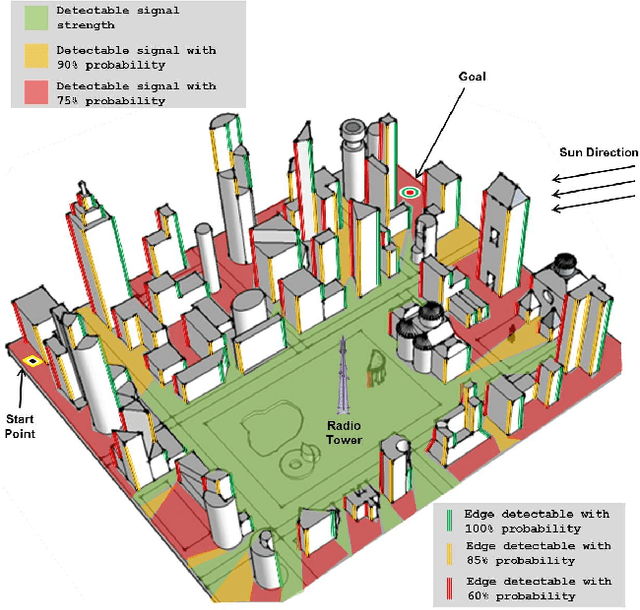
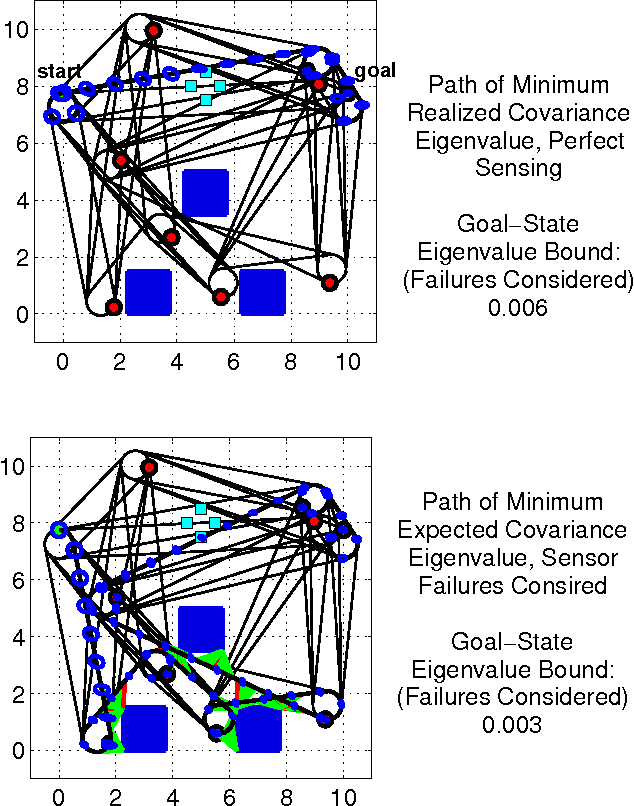
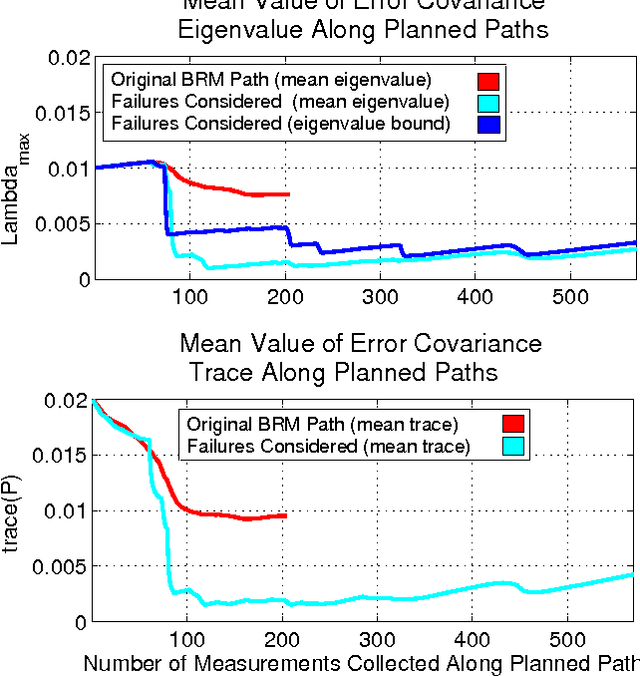
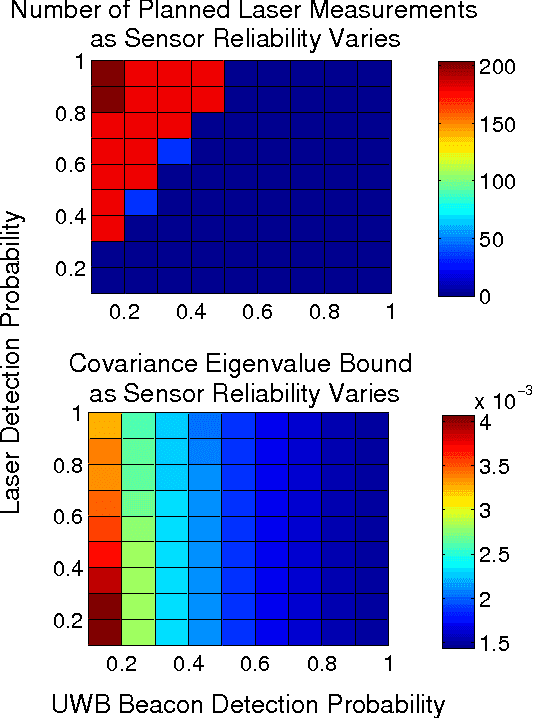
In this paper, we extend the recent body of work on planning under uncertainty to include the fact that sensors may not provide any measurement owing to misdetection. This is caused either by adverse environmental conditions that prevent the sensors from making measurements or by the fundamental limitations of the sensors. Examples include RF-based ranging devices that intermittently do not receive the signal from beacons because of obstacles; the misdetection of features by a camera system in detrimental lighting conditions; a LIDAR sensor that is pointed at a glass-based material such as a window, etc. The main contribution of this paper is twofold. We first show that it is possible to obtain an analytical bound on the performance of a state estimator under sensor misdetection occurring stochastically over time in the environment. We then show how this bound can be used in a sample-based path planning algorithm to produce a path that trades off accuracy and robustness. Computational results demonstrate the benefit of the approach and comparisons are made with the state of the art in path planning under state uncertainty.