 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-BERT: Adversarial Cross-modal Enhanced BERT for E-commerce Retrieval
Paper and Code
Dec 14, 2021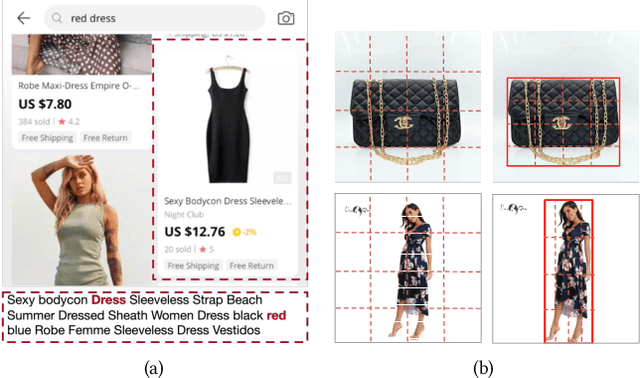

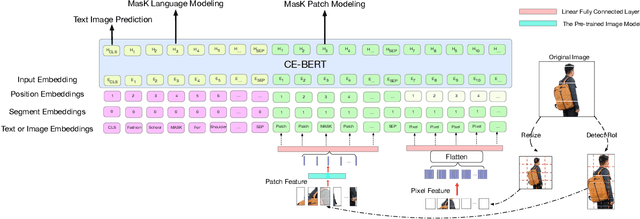

Nowadays on E-commerce platforms, products are presented to the customers with multiple modalities. These multiple modalities are significant for a retrieval system while providing attracted products for customers. Therefore, how to take into account those multiple modalities simultaneously to boost the retrieval performance is crucial. This problem is a huge challenge to us due to the following reasons: (1) the way of extracting patch features with the pre-trained image model (e.g., CNN-based model) has much inductive bias. It is difficult to capture the efficient information from the product image in E-commerce. (2) The heterogeneity of multimodal data makes it challenging to construct the representations of query text and product including title and image in a common subspace. We propose a novel Adversarial Cross-modal Enhanced BERT (ACE-BERT) for efficient E-commerce retrieval. In detail, ACE-BERT leverages the patch features and pixel features as image representation. Thus the Transformer architecture can be applied directly to the raw image sequences. With the pre-trained enhanced BERT as the backbone network, ACE-BERT further adopts adversarial learning by adding a domain classifier to ensure the distribution consistency of different modality representations for the purpose of narrowing down the representation gap between query and product. Experimental results demonstrate that ACE-BERT outperforms the state-of-the-art approaches on the retrieval task. It is remarkable that ACE-BERT has already been deployed in our E-commerce's search engine, leading to 1.46% increase in revenue.