 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference as Reward, Maximum Preference Optimization with Importance Sampling
Jan 08, 2024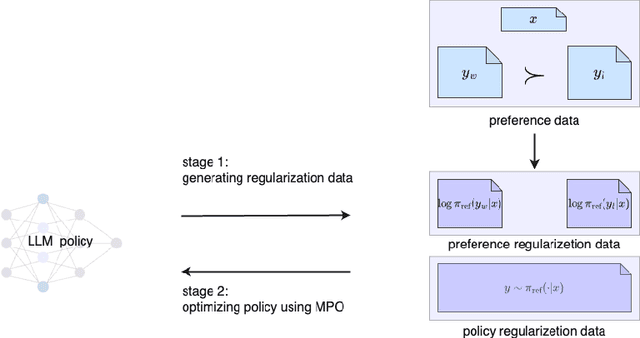
Preference learning is a key technology for aligning language models with human values. Reinforcement Learning from Human Feedback (RLHF) is a model based algorithm to optimize preference learning, which first fitting a reward model for preference score, and then optimizing generating policy with on-policy PPO algorithm to maximize the reward. The processing of RLHF is complex, time-consuming and unstable. Direct Preference Optimization (DPO) algorithm using off-policy algorithm to direct optimize generating policy and eliminating the need for reward model, which is data efficient and stable. DPO use Bradley-Terry model and log-loss which leads to over-fitting to the preference data at the expense of ignoring KL-regularization term when preference is deterministic. IPO uses a root-finding MSE loss to solve the ignoring KL-regularization problem. In this paper, we'll figure out, although IPO fix the problem when preference is deterministic, but both DPO and IPO fails the KL-regularization term because the support of preference distribution not equal to reference distribution. Then, we design a simple and intuitive off-policy preference optimization algorithm from an importance sampling view, which we call Maximum Preference Optimization (MPO), and add off-policy KL-regularization terms which makes KL-regularization truly effective. The objective of MPO bears resemblance to RLHF's objective, and likes IPO, MPO is off-policy. So, MPO attains the best of both worlds. To simplify the learning process and save memory usage, MPO eliminates the needs for both reward model and reference policy.