 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?
Oct 02, 2025Large language models (LLMs) have recently demonstrated strong capabilities as autonomous agents, showing promise in reasoning, tool use, and sequential decision-making. While prior benchmarks have evaluated LLM agents in domains such as software engineering and scientific discovery, the finance domain remains underexplored, despite its direct relevance to economic value and high-stakes decision-making. Existing financial benchmarks primarily test static knowledge through question answering, but they fall short of capturing the dynamic and iterative nature of trading. To address this gap, we introduce StockBench, a contamination-free benchmark designed to evaluate LLM agents in realistic, multi-month stock trading environments. Agents receive daily market signals -- including prices, fundamentals, and news -- and must make sequential buy, sell, or hold decisions. Performance is assessed using financial metrics such as cumulative return, maximum drawdown, and the Sortino ratio. Our evaluation of state-of-the-art proprietary (e.g., GPT-5, Claude-4) and open-weight (e.g., Qwen3, Kimi-K2, GLM-4.5) models shows that while most LLM agents struggle to outperform the simple buy-and-hold baseline, several models demonstrate the potential to deliver higher returns and manage risk more effectively. These findings highlight both the challenges and opportunities in developing LLM-powered financial agents, showing that excelling at static financial knowledge tasks does not necessarily translate into successful trading strategies. We release StockBench as an open-source resource to support reproducibility and advance future research in this domain.
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Jun 12, 2024



Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Rethinking Human-AI Collaboration in Complex Medical Decision Making: A Case Study in Sepsis Diagnosis
Sep 17, 2023

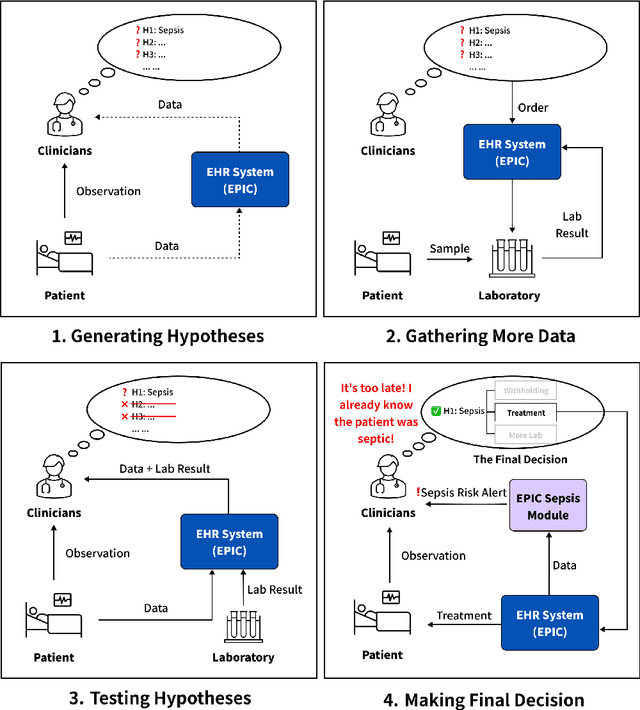

Today's AI systems for medical decision support often succeed on benchmark datasets in research papers but fail in real-world deployment. This work focuses on the decision making of sepsis, an acute life-threatening systematic infection that requires an early diagnosis with high uncertainty from the clinician. Our aim is to explore the design requirements for AI systems that can support clinical experts in making better decisions for the early diagnosis of sepsis. The study begins with a formative study investigating why clinical experts abandon an existing AI-powered Sepsis predictive module in their electrical health record (EHR) system. We argue that a human-centered AI system needs to support human experts in the intermediate stages of a medical decision-making process (e.g., generating hypotheses or gathering data), instead of focusing only on the final decision. Therefore, we build SepsisLab based on a state-of-the-art AI algorithm and extend it to predict the future projection of sepsis development, visualize the prediction uncertainty, and propose actionable suggestions (i.e., which additional laboratory tests can be collected) to reduce such uncertainty. Through heuristic evaluation with six clinicians using our prototype system, we demonstrate that SepsisLab enables a promising human-AI collaboration paradigm for the future of AI-assisted sepsis diagnosis and other high-stakes medical decision making.