 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Understanding: Preserving Collaborative Frequency Components in LLM-based Recommendation
Aug 14, 2025Recommender systems in concert with Large Language Models (LLMs) present promising avenues for generating semantically-informed recommendations. However, LLM-based recommenders exhibit a tendency to overemphasize semantic correlations within users' interaction history. When taking pretrained collaborative ID embeddings as input, LLM-based recommenders progressively weaken the inherent collaborative signals as the embeddings propagate through LLM backbones layer by layer, as opposed to traditional Transformer-based sequential models in which collaborative signals are typically preserved or even enhanced for state-of-the-art performance. To address this limitation, we introduce FreLLM4Rec, an approach designed to balance semantic and collaborative information from a spectral perspective. Item embeddings that incorporate both semantic and collaborative information are first purified using a Global Graph Low-Pass Filter (G-LPF) to preliminarily remove irrelevant high-frequency noise. Temporal Frequency Modulation (TFM) then actively preserves collaborative signal layer by layer. Note that the collaborative preservation capability of TFM is theoretically guaranteed by establishing a connection between the optimal but hard-to-implement local graph fourier filters and the suboptimal yet computationally efficient frequency-domain filters. Extensive experiments on four benchmark datasets demonstrate that FreLLM4Rec successfully mitigates collaborative signal attenuation and achieves competitive performance, with improvements of up to 8.00\% in NDCG@10 over the best baseline. Our findings provide insights into how LLMs process collaborative information and offer a principled approach for improving LLM-based recommendation systems.
Exploring Feature-based Knowledge Distillation For Recommender System: A Frequency Perspective
Nov 16, 2024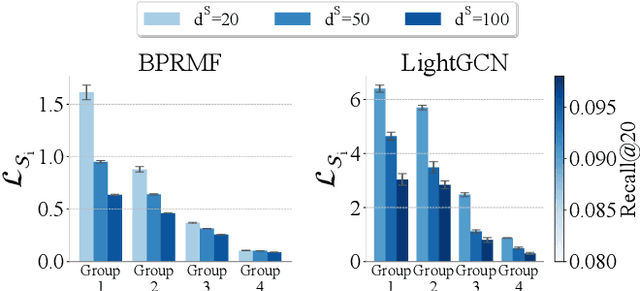


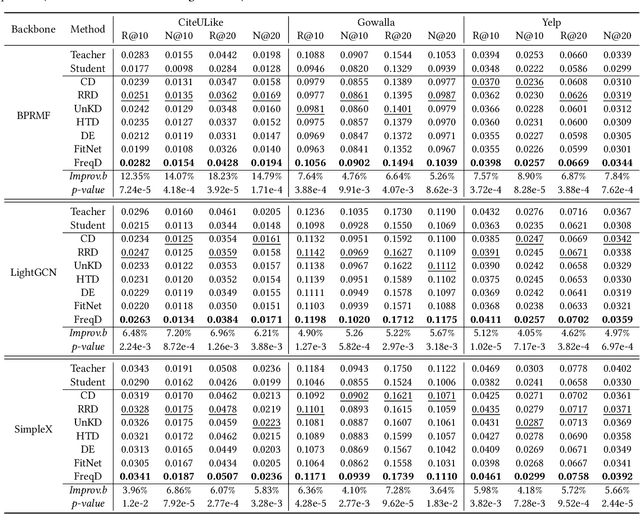
In this paper, we analyze the feature-based knowledge distillation for recommendation from the frequency perspective. By defining knowledge as different frequency components of the features, we theoretically demonstrate that regular feature-based knowledge distillation is equivalent to equally minimizing losses on all knowledge and further analyze how this equal loss weight allocation method leads to important knowledge being overlooked. In light of this, we propose to emphasize important knowledge by redistributing knowledge weights. Furthermore, we propose FreqD, a lightweight knowledge reweighting method, to avoid the computational cost of calculating losses on each knowledge. Extensive experiments demonstrate that FreqD consistently and significantly outperforms state-of-the-art knowledge distillation methods for recommender systems. Our code is available at \url{https://anonymous.4open.science/r/FreqKD/}
Are LLM-based Recommenders Already the Best? Simple Scaled Cross-entropy Unleashes the Potential of Traditional Sequential Recommenders
Aug 26, 2024
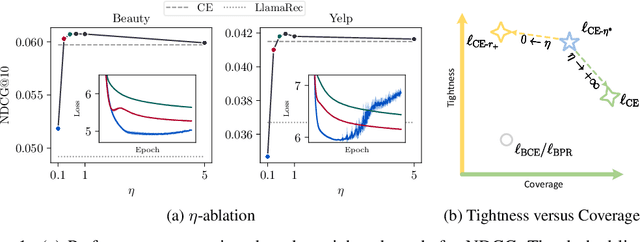
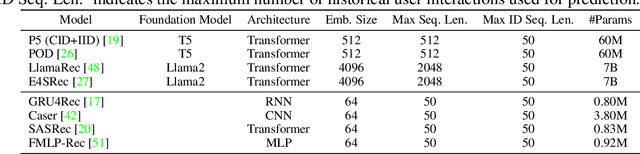
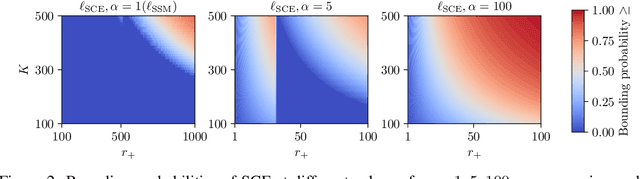
Large language models (LLMs) have been garnering increasing attention in the recommendation community. Some studies have observed that LLMs, when fine-tuned by the cross-entropy (CE) loss with a full softmax, could achieve `state-of-the-art' performance in sequential recommendation. However, most of the baselines used for comparison are trained using a pointwise/pairwise loss function. This inconsistent experimental setting leads to the underestimation of traditional methods and further fosters over-confidence in the ranking capability of LLMs. In this study, we provide theoretical justification for the superiority of the cross-entropy loss by demonstrating its two desirable properties: tightness and coverage. Furthermore, this study sheds light on additional novel insights: 1) Taking into account only the recommendation performance, CE is not yet optimal as it is not a quite tight bound in terms of some ranking metrics. 2) In scenarios that full softmax cannot be performed, an effective alternative is to scale up the sampled normalizing term. These findings then help unleash the potential of traditional recommendation models, allowing them to surpass LLM-based counterparts. Given the substantial computational burden, existing LLM-based methods are not as effective as claimed for sequential recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.
Understanding the Role of Cross-Entropy Loss in Fairly Evaluating Large Language Model-based Recommendation
Feb 22, 2024


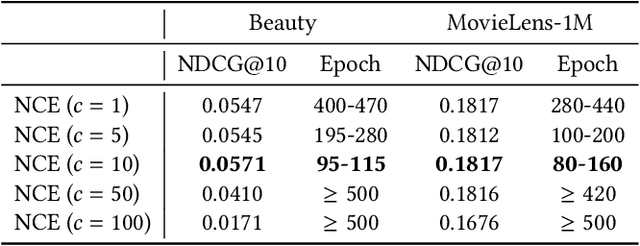
Large language models (LLMs) have gained much attention in the recommendation community; some studies have observed that LLMs, fine-tuned by the cross-entropy loss with a full softmax, could achieve state-of-the-art performance already. However, these claims are drawn from unobjective and unfair comparisons. In view of the substantial quantity of items in reality, conventional recommenders typically adopt a pointwise/pairwise loss function instead for training. This substitute however causes severe performance degradation, leading to under-estimation of conventional methods and over-confidence in the ranking capability of LLMs. In this work, we theoretically justify the superiority of cross-entropy, and showcase that it can be adequately replaced by some elementary approximations with certain necessary modifications. The remarkable results across three public datasets corroborate that even in a practical sense, existing LLM-based methods are not as effective as claimed for next-item recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.
Contrastive Learning with Negative Sampling Correction
Jan 13, 2024As one of the most effective self-supervised representation learning methods, contrastive learning (CL) relies on multiple negative pairs to contrast against each positive pair. In the standard practice of contrastive learning, data augmentation methods are utilized to generate both positive and negative pairs. While existing works have been focusing on improving the positive sampling, the negative sampling process is often overlooked. In fact, the generated negative samples are often polluted by positive samples, which leads to a biased loss and performance degradation. To correct the negative sampling bias, we propose a novel contrastive learning method named Positive-Unlabeled Contrastive Learning (PUCL). PUCL treats the generated negative samples as unlabeled samples and uses information from positive samples to correct bias in contrastive loss. We prove that the corrected loss used in PUCL only incurs a negligible bias compared to the unbiased contrastive loss. PUCL can be applied to general contrastive learning problems and outperforms state-of-the-art methods on various image and graph classification tasks. The code of PUCL is in the supplementary file.
From Input to Output: A Multi-layer Knowledge Distillation Framework for Compressing Recommendation Models
Nov 08, 2023



To reduce the size of recommendation models, there have been many studies on compressing recommendation models using knowledge distillation. In this paper, we decompose recommendation models into three layers, i.e., the input layer, the intermediate layer, and the output layer, and address deficiencies layer by layer. First, previous methods focus only on two layers, neglecting the input layer. Second, in the intermediate layer, existing methods ignore the inconsistency of user preferences induced by the projectors. Third, in the output layer, existing methods use only hard labels rather than soft labels from the teacher. To address these deficiencies, we propose \textbf{M}ulti-layer \textbf{K}nowledge \textbf{D}istillation (MKD), which consists of three components: 1) Distillation with Neighbor-based Knowledge (NKD) utilizes the teacher's knowledge about entities with similar characteristics in the input layer to enable the student to learn robust representations. 2) Distillation with Consistent Preference (CPD) reduces the inconsistency of user preferences caused by projectors in the intermediate layer by two regularization terms. 3) Distillation with Soft Labels (SLD) constructs soft labels in the output layer by considering the predictions of both the teacher and the student. Our extensive experiments show that MKD even outperforms the teacher with one-tenth of the model size.
Robust Positive-Unlabeled Learning via Noise Negative Sample Self-correction
Aug 01, 2023



Learning from positive and unlabeled data is known as positive-unlabeled (PU) learning in literature and has attracted much attention in recent years. One common approach in PU learning is to sample a set of pseudo-negatives from the unlabeled data using ad-hoc thresholds so that conventional supervised methods can be applied with both positive and negative samples. Owing to the label uncertainty among the unlabeled data, errors of misclassifying unlabeled positive samples as negative samples inevitably appear and may even accumulate during the training processes. Those errors often lead to performance degradation and model instability. To mitigate the impact of label uncertainty and improve the robustness of learning with positive and unlabeled data, we propose a new robust PU learning method with a training strategy motivated by the nature of human learning: easy cases should be learned first. Similar intuition has been utilized in curriculum learning to only use easier cases in the early stage of training before introducing more complex cases. Specifically, we utilize a novel ``hardness'' measure to distinguish unlabeled samples with a high chance of being negative from unlabeled samples with large label noise. An iterative training strategy is then implemented to fine-tune the selection of negative samples during the training process in an iterative manner to include more ``easy'' samples in the early stage of training. Extensive experimental validations over a wide range of learning tasks show that this approach can effectively improve the accuracy and stability of learning with positive and unlabeled data. Our code is available at https://github.com/woriazzc/Robust-PU