 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Cross-Entropy Loss in Fairly Evaluating Large Language Model-based Recommendation
Paper and Code



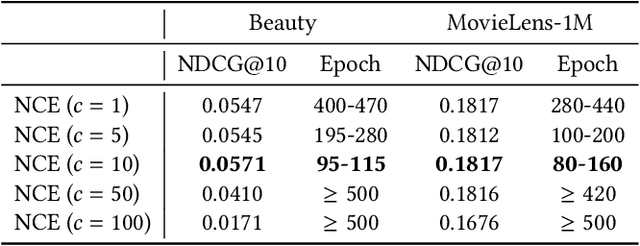
Large language models (LLMs) have gained much attention in the recommendation community; some studies have observed that LLMs, fine-tuned by the cross-entropy loss with a full softmax, could achieve state-of-the-art performance already. However, these claims are drawn from unobjective and unfair comparisons. In view of the substantial quantity of items in reality, conventional recommenders typically adopt a pointwise/pairwise loss function instead for training. This substitute however causes severe performance degradation, leading to under-estimation of conventional methods and over-confidence in the ranking capability of LLMs. In this work, we theoretically justify the superiority of cross-entropy, and showcase that it can be adequately replaced by some elementary approximations with certain necessary modifications. The remarkable results across three public datasets corroborate that even in a practical sense, existing LLM-based methods are not as effective as claimed for next-item recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.