 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLM-based Recommenders Already the Best? Simple Scaled Cross-entropy Unleashes the Potential of Traditional Sequential Recommenders
Paper and Code

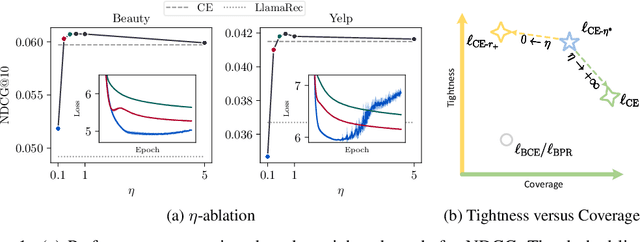
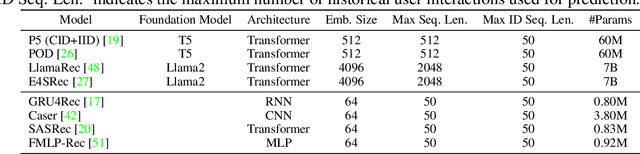
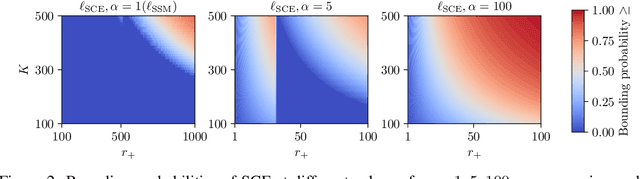
Large language models (LLMs) have been garnering increasing attention in the recommendation community. Some studies have observed that LLMs, when fine-tuned by the cross-entropy (CE) loss with a full softmax, could achieve `state-of-the-art' performance in sequential recommendation. However, most of the baselines used for comparison are trained using a pointwise/pairwise loss function. This inconsistent experimental setting leads to the underestimation of traditional methods and further fosters over-confidence in the ranking capability of LLMs. In this study, we provide theoretical justification for the superiority of the cross-entropy loss by demonstrating its two desirable properties: tightness and coverage. Furthermore, this study sheds light on additional novel insights: 1) Taking into account only the recommendation performance, CE is not yet optimal as it is not a quite tight bound in terms of some ranking metrics. 2) In scenarios that full softmax cannot be performed, an effective alternative is to scale up the sampled normalizing term. These findings then help unleash the potential of traditional recommendation models, allowing them to surpass LLM-based counterparts. Given the substantial computational burden, existing LLM-based methods are not as effective as claimed for sequential recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.