 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoMorelization: Building Normalizer-Free Models from a Sample's Perspective
Paper and Code
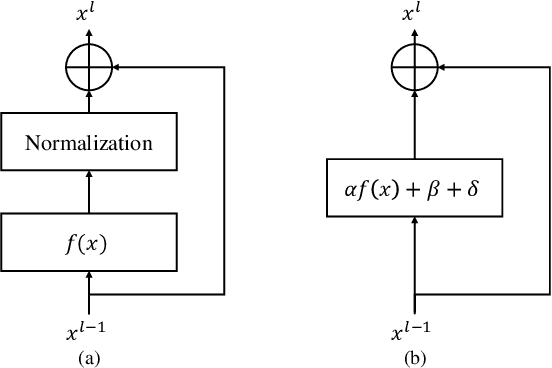
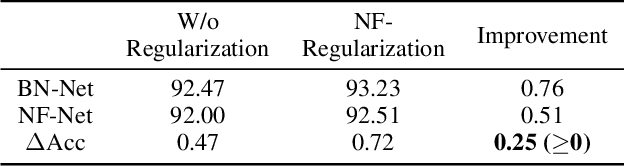
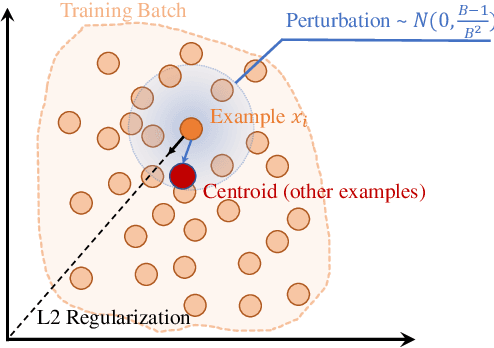
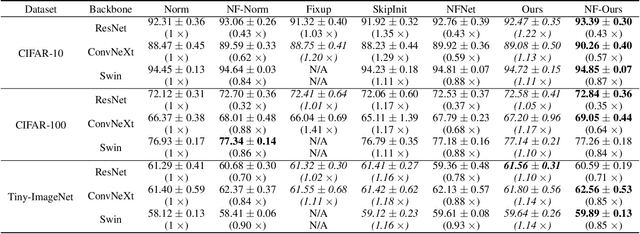
The normalizing layer has become one of the basic configurations of deep learning models, but it still suffers from computational inefficiency, interpretability difficulties, and low generality. After gaining a deeper understanding of the recent normalization and normalizer-free research works from a sample's perspective, we reveal the fact that the problem lies in the sampling noise and the inappropriate prior assumption. In this paper, we propose a simple and effective alternative to normalization, which is called "NoMorelization". NoMorelization is composed of two trainable scalars and a zero-centered noise injector. Experimental results demonstrate that NoMorelization is a general component for deep learning and is suitable for different model paradigms (e.g., convolution-based and attention-based models) to tackle different tasks (e.g., discriminative and generative tasks). Compared with existing mainstream normalizers (e.g., BN, LN, and IN) and state-of-the-art normalizer-free methods, NoMorelization shows the best speed-accuracy trade-off.