 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel gesture interaction control method for rehabilitation lower extremity exoskeleton
Apr 02, 2025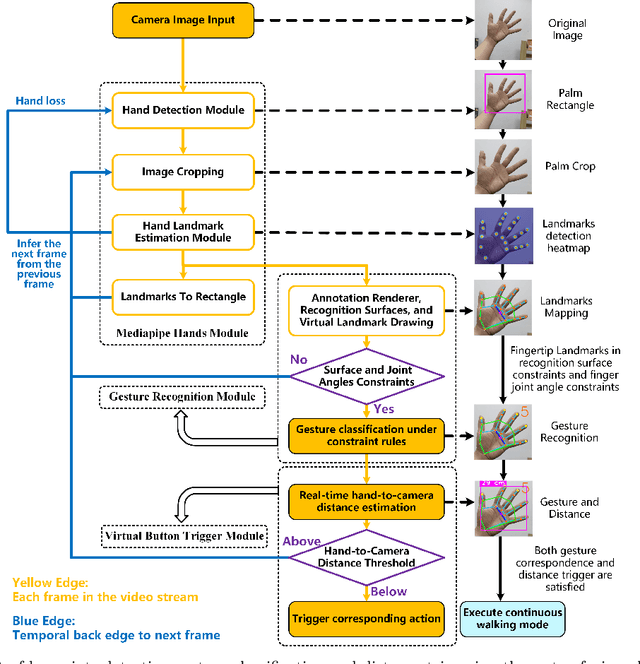
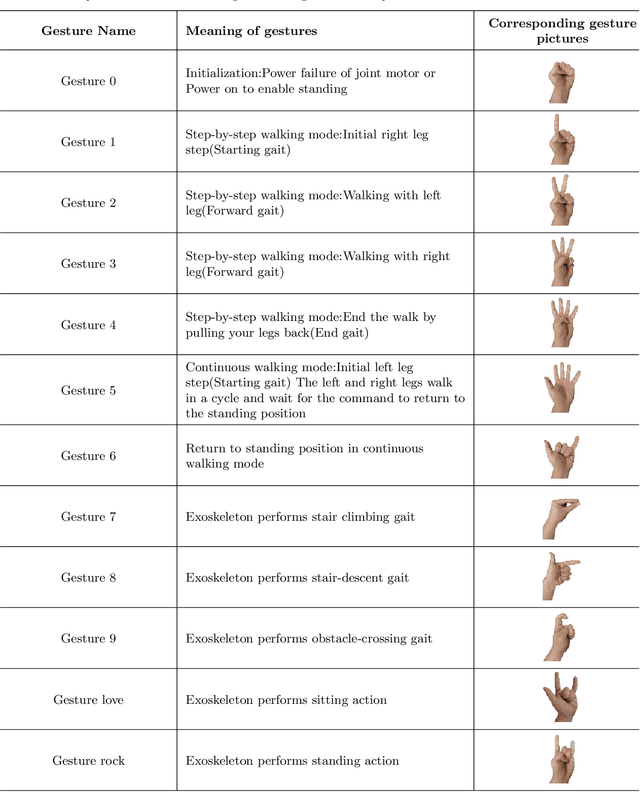
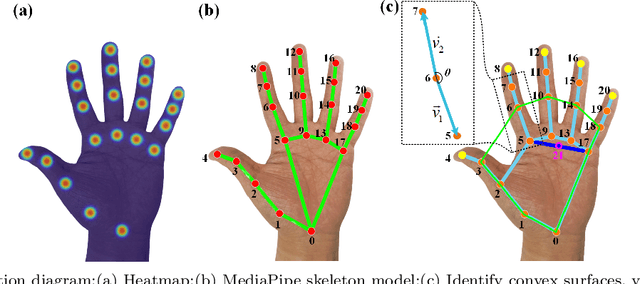
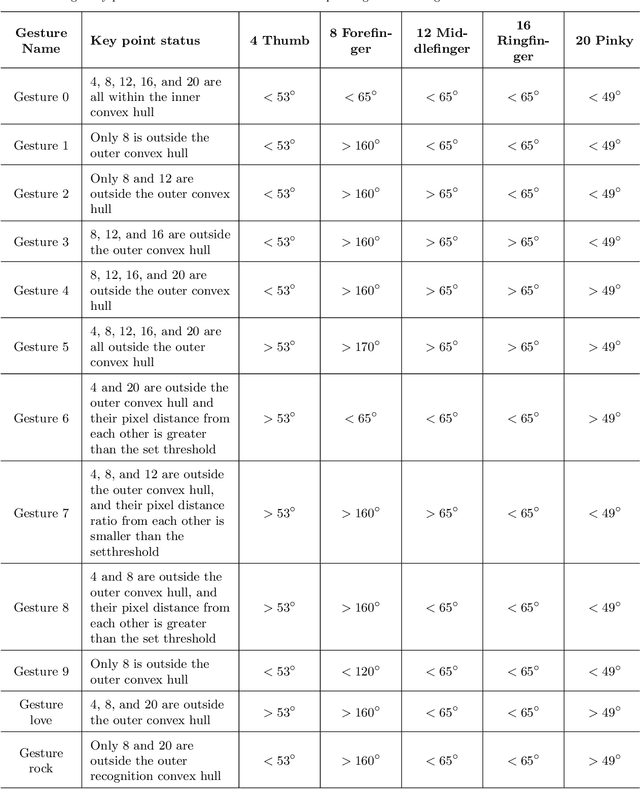
With the rapid development of Rehabilitation Lower Extremity Robotic Exoskeletons (RLEEX) technology, significant advancements have been made in Human-Robot Interaction (HRI) methods. These include traditional physical HRI methods that are easily recognizable and various bio-electrical signal-based HRI methods that can visualize and predict actions. However, most of these HRI methods are contact-based, facing challenges such as operational complexity, sensitivity to interference, risks associated with implantable devices, and, most importantly, limitations in comfort. These challenges render the interaction less intuitive and natural, which can negatively impact patient motivation for rehabilitation. To address these issues, this paper proposes a novel non-contact gesture interaction control method for RLEEX, based on RGB monocular camera depth estimation. This method integrates three key steps: detecting keypoints, recognizing gestures, and assessing distance, thereby applying gesture information and augmented reality triggering technology to control gait movements of RLEEX. Results indicate that this approach provides a feasible solution to the problems of poor comfort, low reliability, and high latency in HRI for RLEEX platforms. Specifically, it achieves a gesture-controlled exoskeleton motion accuracy of 94.11\% and an average system response time of 0.615 seconds through non-contact HRI. The proposed non-contact HRI method represents a pioneering advancement in control interactions for RLEEX, paving the way for further exploration and development in this field.
Domain Generalization for Zero-calibration BCIs with Knowledge Distillation-based Phase Invariant Feature Extraction
May 18, 2024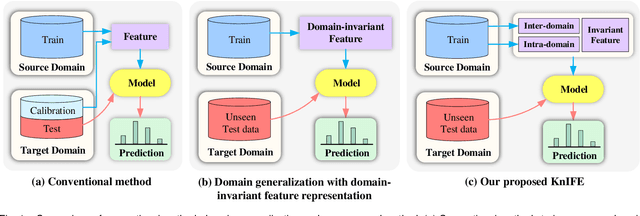
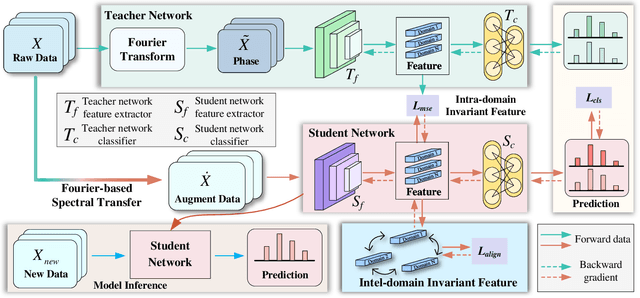
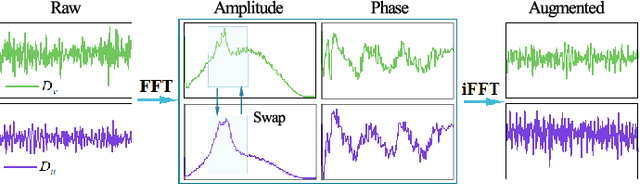
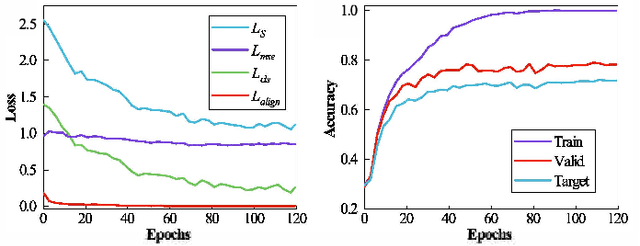
The distribution shift of electroencephalography (EEG) data causes poor generalization of braincomputer interfaces (BCIs) in unseen domains. Some methods try to tackle this challenge by collecting a portion of user data for calibration. However, it is time-consuming, mentally fatiguing, and user-unfriendly. To achieve zerocalibration BCIs, most studies employ domain generalization (DG) techniques to learn invariant features across different domains in the training set. However, they fail to fully explore invariant features within the same domain, leading to limited performance. In this paper, we present an novel method to learn domain-invariant features from both interdomain and intra-domain perspectives. For intra-domain invariant features, we propose a knowledge distillation framework to extract EEG phase-invariant features within one domain. As for inter-domain invariant features, correlation alignment is used to bridge distribution gaps across multiple domains. Experimental results on three public datasets validate the effectiveness of our method, showcasing stateof-the-art performance. To the best of our knowledge, this is the first domain generalization study that exploit Fourier phase information as an intra-domain invariant feature to facilitate EEG generalization. More importantly, the zerocalibration BCI based on inter- and intra-domain invariant features has significant potential to advance the practical applications of BCIs in real world.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation and Completion
Nov 13, 2023Over the past few years, monocular depth estimation and completion have been paid more and more attention from the computer vision community because of their widespread applications. In this paper, we introduce novel physics (geometry)-driven deep learning frameworks for these two tasks by assuming that 3D scenes are constituted with piece-wise planes. Instead of directly estimating the depth map or completing the sparse depth map, we propose to estimate the surface normal and plane-to-origin distance maps or complete the sparse surface normal and distance maps as intermediate outputs. To this end, we develop a normal-distance head that outputs pixel-level surface normal and distance. Meanwhile, the surface normal and distance maps are regularized by a developed plane-aware consistency constraint, which are then transformed into depth maps. Furthermore, we integrate an additional depth head to strengthen the robustness of the proposed frameworks. Extensive experiments on the NYU-Depth-v2, KITTI and SUN RGB-D datasets demonstrate that our method exceeds in performance prior state-of-the-art monocular depth estimation and completion competitors. The source code will be available at https://github.com/ShuweiShao/NDDepth.
MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
Nov 13, 2023Over the past few years, self-supervised monocular depth estimation that does not depend on ground-truth during the training phase has received widespread attention. Most efforts focus on designing different types of network architectures and loss functions or handling edge cases, e.g., occlusion and dynamic objects. In this work, we introduce a novel self-supervised depth estimation framework, dubbed MonoDiffusion, by formulating it as an iterative denoising process. Because the depth ground-truth is unavailable in the training phase, we develop a pseudo ground-truth diffusion process to assist the diffusion in MonoDiffusion. The pseudo ground-truth diffusion gradually adds noise to the depth map generated by a pre-trained teacher model. Moreover,the teacher model allows applying a distillation loss to guide the denoised depth. Further, we develop a masked visual condition mechanism to enhance the denoising ability of model. Extensive experiments are conducted on the KITTI and Make3D datasets and the proposed MonoDiffusion outperforms prior state-of-the-art competitors. The source code will be available at https://github.com/ShuweiShao/MonoDiffusion.
IEBins: Iterative Elastic Bins for Monocular Depth Estimation
Sep 25, 2023Monocular depth estimation (MDE) is a fundamental topic of geometric computer vision and a core technique for many downstream applications. Recently, several methods reframe the MDE as a classification-regression problem where a linear combination of probabilistic distribution and bin centers is used to predict depth. In this paper, we propose a novel concept of iterative elastic bins (IEBins) for the classification-regression-based MDE. The proposed IEBins aims to search for high-quality depth by progressively optimizing the search range, which involves multiple stages and each stage performs a finer-grained depth search in the target bin on top of its previous stage. To alleviate the possible error accumulation during the iterative process, we utilize a novel elastic target bin to replace the original target bin, the width of which is adjusted elastically based on the depth uncertainty. Furthermore, we develop a dedicated framework composed of a feature extractor and an iterative optimizer that has powerful temporal context modeling capabilities benefiting from the GRU-based architecture. Extensive experiments on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets demonstrate that the proposed method surpasses prior state-of-the-art competitors. The source code is publicly available at https://github.com/ShuweiShao/IEBins.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation
Sep 24, 2023Monocular depth estimation has drawn widespread attention from the vision community due to its broad applications. In this paper, we propose a novel physics (geometry)-driven deep learning framework for monocular depth estimation by assuming that 3D scenes are constituted by piece-wise planes. Particularly, we introduce a new normal-distance head that outputs pixel-level surface normal and plane-to-origin distance for deriving depth at each position. Meanwhile, the normal and distance are regularized by a developed plane-aware consistency constraint. We further integrate an additional depth head to improve the robustness of the proposed framework. To fully exploit the strengths of these two heads, we develop an effective contrastive iterative refinement module that refines depth in a complementary manner according to the depth uncertainty. Extensive experiments indicate that the proposed method exceeds previous state-of-the-art competitors on the NYU-Depth-v2, KITTI and SUN RGB-D datasets. Notably, it ranks 1st among all submissions on the KITTI depth prediction online benchmark at the submission time.
StairNetV3: Depth-aware Stair Modeling using Deep Learning
Aug 13, 2023Vision-based stair perception can help autonomous mobile robots deal with the challenge of climbing stairs, especially in unfamiliar environments. To address the problem that current monocular vision methods are difficult to model stairs accurately without depth information, this paper proposes a depth-aware stair modeling method for monocular vision. Specifically, we take the extraction of stair geometric features and the prediction of depth images as joint tasks in a convolutional neural network (CNN), with the designed information propagation architecture, we can achieve effective supervision for stair geometric feature learning by depth information. In addition, to complete the stair modeling, we take the convex lines, concave lines, tread surfaces and riser surfaces as stair geometric features and apply Gaussian kernels to enable the network to predict contextual information within the stair lines. Combined with the depth information obtained by depth sensors, we propose a stair point cloud reconstruction method that can quickly get point clouds belonging to the stair step surfaces. Experiments on our dataset show that our method has a significant improvement over the previous best monocular vision method, with an intersection over union (IOU) increase of 3.4 %, and the lightweight version has a fast detection speed and can meet the requirements of most real-time applications. Our dataset is available at https://data.mendeley.com/datasets/6kffmjt7g2/1.
URCDC-Depth: Uncertainty Rectified Cross-Distillation with CutFlip for Monocular Depth Estimation
Feb 17, 2023



This work aims to estimate a high-quality depth map from a single RGB image. Due to the lack of depth clues, making full use of the long-range correlation and the local information is critical for accurate depth estimation. Towards this end, we introduce an uncertainty rectified cross-distillation between Transformer and convolutional neural network (CNN) to learn a unified depth estimator. Specifically, we use the depth estimates from the Transformer branch and the CNN branch as pseudo labels to teach each other. Meanwhile, we model the pixel-wise depth uncertainty to rectify the loss weights of noisy pseudo labels. To avoid the large capacity gap induced by the strong Transformer branch deteriorating the cross-distillation, we transfer the feature maps from Transformer to CNN and design coupling units to assist the weak CNN branch to leverage the transferred features. Furthermore, we propose a surprisingly simple yet highly effective data augmentation technique CutFlip, which enforces the model to exploit more valuable clues apart from the vertical image position for depth inference. Extensive experiments demonstrate that our model, termed~\textbf{URCDC-Depth}, exceeds previous state-of-the-art methods on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets, even with no additional computational burden at inference time. The source code is publicly available at \url{https://github.com/ShuweiShao/URCDC-Depth}.
RGB-D-based Stair Detection using Deep Learning for Autonomous Stair Climbing
Dec 09, 2022Stairs are common building structures in urban environments, and stair detection is an important part of environment perception for autonomous mobile robots. Most existing algorithms have difficulty combining the visual information from binocular sensors effectively and ensuring reliable detection at night and in the case of extremely fuzzy visual clues. To solve these problems, we propose a neural network architecture with RGB and depth map inputs. Specifically, we design a selective module, which can make the network learn the complementary relationship between the RGB map and the depth map and effectively combine the information from the RGB map and the depth map in different scenes. In addition, we design a line clustering algorithm for the postprocessing of detection results, which can make full use of the detection results to obtain the geometric stair parameters. Experiments on our dataset show that our method can achieve better accuracy and recall compared with existing state-of-the-art deep learning methods, which are 5.64% and 7.97%, respectively, and our method also has extremely fast detection speed. A lightweight version can achieve 300 + frames per second with the same resolution, which can meet the needs of most real-time detection scenes.
SMUDLP: Self-Teaching Multi-Frame Unsupervised Endoscopic Depth Estimation with Learnable Patchmatch
May 30, 2022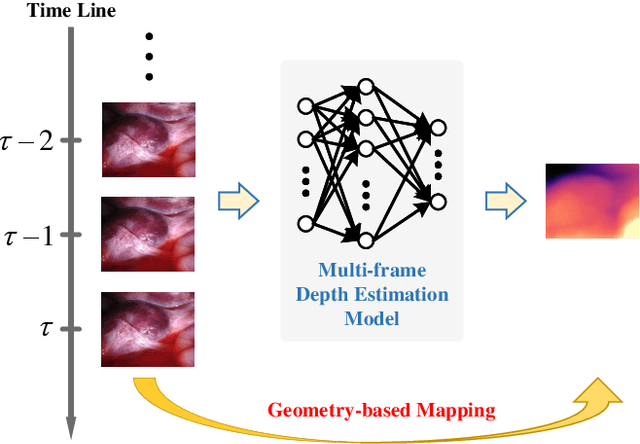


Unsupervised monocular trained depth estimation models make use of adjacent frames as a supervisory signal during the training phase. However, temporally correlated frames are also available at inference time for many clinical applications, e.g., surgical navigation. The vast majority of monocular systems do not exploit this valuable signal that could be deployed to enhance the depth estimates. Those that do, achieve only limited gains due to the unique challenges in endoscopic scenes, such as low and homogeneous textures and inter-frame brightness fluctuations. In this work, we present SMUDLP, a novel and unsupervised paradigm for multi-frame monocular endoscopic depth estimation. The SMUDLP integrates a learnable patchmatch module to adaptively increase the discriminative ability in low-texture and homogeneous-texture regions, and enforces cross-teaching and self-teaching consistencies to provide efficacious regularizations towards brightness fluctuations. Our detailed experiments on both SCARED and Hamlyn datasets indicate that the SMUDLP exceeds state-of-the-art competitors by a large margin, including those that use single or multiple frames at inference time. The source code and trained models will be publicly available upon the acceptance.