 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAN: Self-Locator Aided Network for Cross-Modal Understanding
Dec 08, 2022



Learning fine-grained interplay between vision and language allows to a more accurate understanding for VisionLanguage tasks. However, it remains challenging to extract key image regions according to the texts for semantic alignments. Most existing works are either limited by textagnostic and redundant regions obtained with the frozen detectors, or failing to scale further due to its heavy reliance on scarce grounding (gold) data to pre-train detectors. To solve these problems, we propose Self-Locator Aided Network (SLAN) for cross-modal understanding tasks without any extra gold data. SLAN consists of a region filter and a region adaptor to localize regions of interest conditioned on different texts. By aggregating cross-modal information, the region filter selects key regions and the region adaptor updates their coordinates with text guidance. With detailed region-word alignments, SLAN can be easily generalized to many downstream tasks. It achieves fairly competitive results on five cross-modal understanding tasks (e.g., 85.7% and 69.2% on COCO image-to-text and text-to-image retrieval, surpassing previous SOTA methods). SLAN also demonstrates strong zero-shot and fine-tuned transferability to two localization tasks.
Supervised and Self-supervised Pretraining Based COVID-19 Detection Using Acoustic Breathing/Cough/Speech Signals
Jan 22, 2022

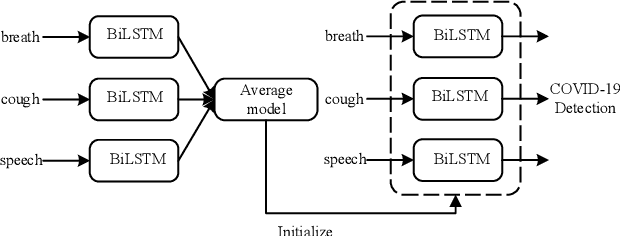
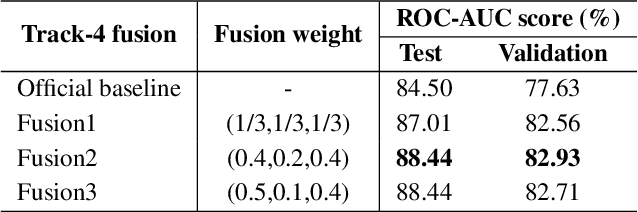
In this work, we propose a bi-directional long short-term memory (BiLSTM) network based COVID-19 detection method using breath/speech/cough signals. By using the acoustic signals to train the network, respectively, we can build individual models for three tasks, whose parameters are averaged to obtain an average model, which is then used as the initialization for the BiLSTM model training of each task. This initialization method can significantly improve the performance on the three tasks, which surpasses the official baseline results. Besides, we also utilize a public pre-trained model wav2vec2.0 and pre-train it using the official DiCOVA datasets. This wav2vec2.0 model is utilized to extract high-level features of the sound as the model input to replace conventional mel-frequency cepstral coefficients (MFCC) features. Experimental results reveal that using high-level features together with MFCC features can improve the performance. To further improve the performance, we also deploy some preprocessing techniques like silent segment removal, amplitude normalization and time-frequency mask. The proposed detection model is evaluated on the DiCOVA dataset and results show that our method achieves an area under curve (AUC) score of 88.44% on blind test in the fusion track.