 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Pooling for 3D Large-Scale Scene Understanding
Jan 17, 2023Inspired by the success of recent vision transformers and large kernel design in convolutional neural networks (CNNs), in this paper, we analyze and explore essential reasons for their success. We claim two factors that are critical for 3D large-scale scene understanding: a larger receptive field and operations with greater non-linearity. The former is responsible for providing long range contexts and the latter can enhance the capacity of the network. To achieve the above properties, we propose a simple yet effective long range pooling (LRP) module using dilation max pooling, which provides a network with a large adaptive receptive field. LRP has few parameters, and can be readily added to current CNNs. Also, based on LRP, we present an entire network architecture, LRPNet, for 3D understanding. Ablation studies are presented to support our claims, and show that the LRP module achieves better results than large kernel convolution yet with reduced computation, due to its nonlinearity. We also demonstrate the superiority of LRPNet on various benchmarks: LRPNet performs the best on ScanNet and surpasses other CNN-based methods on S3DIS and Matterport3D. Code will be made publicly available.
Sampling Equivariant Self-attention Networks for Object Detection in Aerial Images
Nov 05, 2021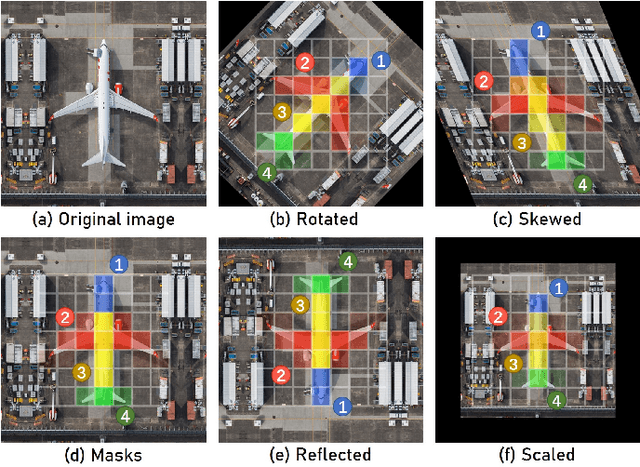
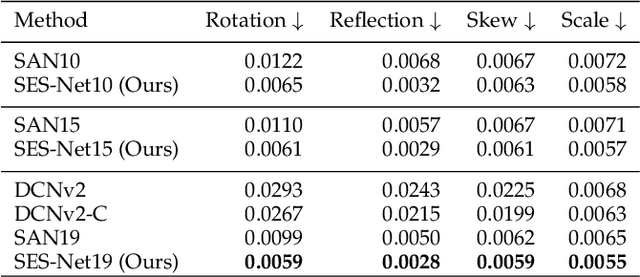
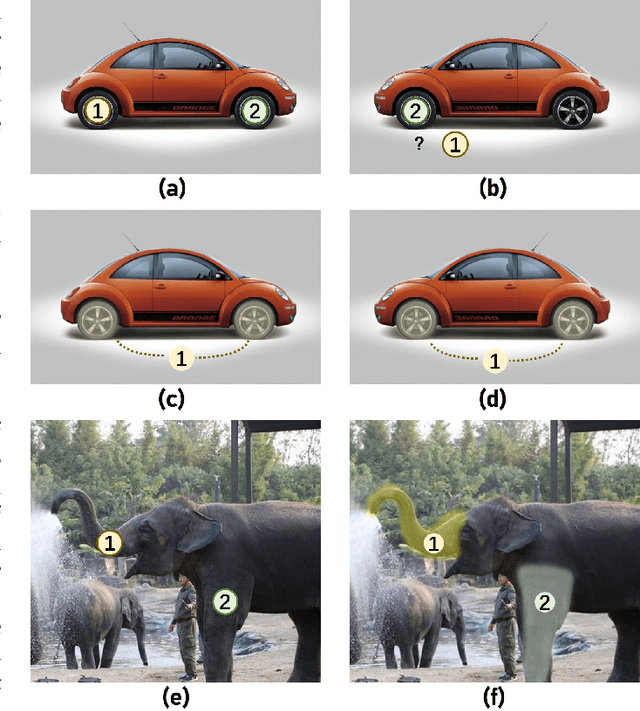
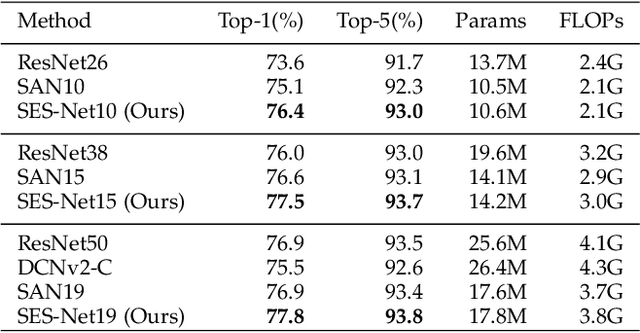
Objects in aerial images have greater variations in scale and orientation than in typical images, so detection is more difficult. Convolutional neural networks use a variety of frequency- and orientation-specific kernels to identify objects subject to different transformations; these require many parameters. Sampling equivariant networks can adjust sampling from input feature maps according to the transformation of the object, allowing a kernel to extract features of an object under different transformations. Doing so requires fewer parameters, and makes the network more suitable for representing deformable objects, like those in aerial images. However, methods like deformable convolutional networks can only provide sampling equivariance under certain circumstances, because of the locations used for sampling. We propose sampling equivariant self-attention networks which consider self-attention restricted to a local image patch as convolution sampling with masks instead of locations, and design a transformation embedding module to further improve the equivariant sampling ability. We also use a novel randomized normalization module to tackle overfitting due to limited aerial image data. We show that our model (i) provides significantly better sampling equivariance than existing methods, without additional supervision, (ii) provides improved classification on ImageNet, and (iii) achieves state-of-the-art results on the DOTA dataset, without increased computation.