 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoLangBind: Unifying Earth Observation with Agglomerative Vision-Language Foundation Models
Mar 08, 2025Earth observation (EO) data, collected from diverse sensors with varying imaging principles, present significant challenges in creating unified analytical frameworks. We present GeoLangBind, a novel agglomerative vision--language foundation model that bridges the gap between heterogeneous EO data modalities using language as a unifying medium. Our approach aligns different EO data types into a shared language embedding space, enabling seamless integration and complementary feature learning from diverse sensor data. To achieve this, we construct a large-scale multimodal image--text dataset, GeoLangBind-2M, encompassing six data modalities. GeoLangBind leverages this dataset to develop a zero-shot foundation model capable of processing arbitrary numbers of EO data channels as input. Through our designed Modality-aware Knowledge Agglomeration (MaKA) module and progressive multimodal weight merging strategy, we create a powerful agglomerative foundation model that excels in both zero-shot vision--language comprehension and fine-grained visual understanding. Extensive evaluation across 23 datasets covering multiple tasks demonstrates GeoLangBind's superior performance and versatility in EO applications, offering a robust framework for various environmental monitoring and analysis tasks. The dataset and pretrained models will be publicly available.
On the Foundations of Earth and Climate Foundation Models
May 07, 2024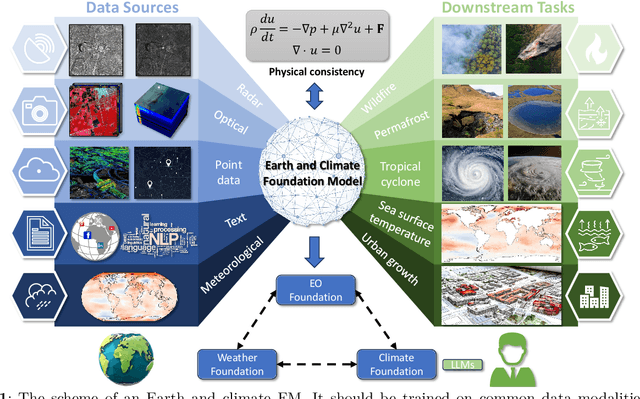

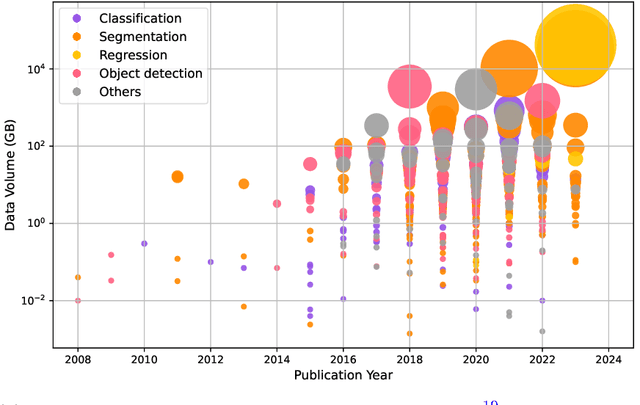
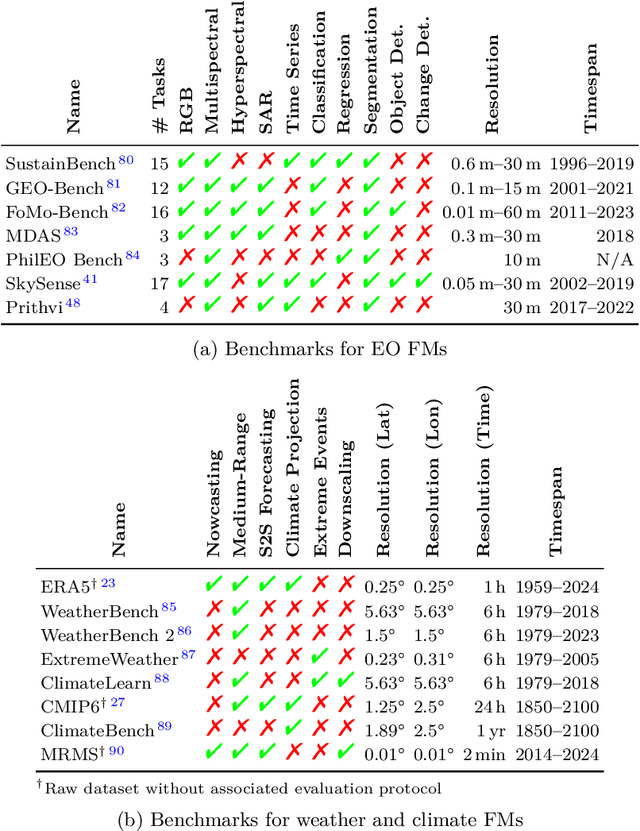
Foundation models have enormous potential in advancing Earth and climate sciences, however, current approaches may not be optimal as they focus on a few basic features of a desirable Earth and climate foundation model. Crafting the ideal Earth foundation model, we define eleven features which would allow such a foundation model to be beneficial for any geoscientific downstream application in an environmental- and human-centric manner.We further shed light on the way forward to achieve the ideal model and to evaluate Earth foundation models. What comes after foundation models? Energy efficient adaptation, adversarial defenses, and interpretability are among the emerging directions.
ChatEarthNet: A Global-Scale Image-Text Dataset Empowering Vision-Language Geo-Foundation Models
Feb 26, 2024An in-depth comprehension of global land cover is essential in Earth observation, forming the foundation for a multitude of applications. Although remote sensing technology has advanced rapidly, leading to a proliferation of satellite imagery, the inherent complexity of these images often makes them difficult for non-expert users to understand. Natural language, as a carrier of human knowledge, can be a bridge between common users and complicated satellite imagery. In this context, we introduce a global-scale, high-quality image-text dataset for remote sensing, providing natural language descriptions for Sentinel-2 data to facilitate the understanding of satellite imagery for common users. Specifically, we utilize Sentinel-2 data for its global coverage as the foundational image source, employing semantic segmentation labels from the European Space Agency's (ESA) WorldCover project to enrich the descriptions of land covers. By conducting in-depth semantic analysis, we formulate detailed prompts to elicit rich descriptions from ChatGPT. To enhance the dataset's quality, we introduce the manual verification process. This step involves manual inspection and correction to refine the dataset, thus significantly improving its accuracy and quality. Finally, we offer the community ChatEarthNet, a large-scale image-text dataset characterized by global coverage, high quality, wide-ranging diversity, and detailed descriptions. ChatEarthNet consists of 163,488 image-text pairs with captions generated by ChatGPT-3.5 and an additional 10,000 image-text pairs with captions generated by ChatGPT-4V(ision). This dataset has significant potential for training vision-language geo-foundation models and evaluating large vision-language models for remote sensing. The dataset will be made publicly available.
RRSIS: Referring Remote Sensing Image Segmentation
Jun 14, 2023
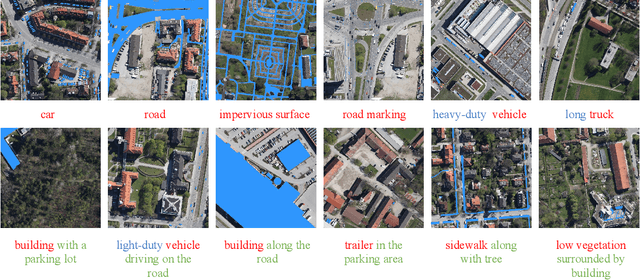

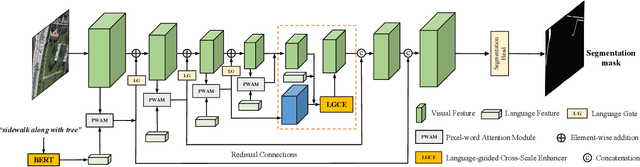
Localizing desired objects from remote sensing images is of great use in practical applications. Referring image segmentation, which aims at segmenting out the objects to which a given expression refers, has been extensively studied in natural images. However, almost no research attention is given to this task of remote sensing imagery. Considering its potential for real-world applications, in this paper, we introduce referring remote sensing image segmentation (RRSIS) to fill in this gap and make some insightful explorations. Specifically, we create a new dataset, called RefSegRS, for this task, enabling us to evaluate different methods. Afterward, we benchmark referring image segmentation methods of natural images on the RefSegRS dataset and find that these models show limited efficacy in detecting small and scattered objects. To alleviate this issue, we propose a language-guided cross-scale enhancement (LGCE) module that utilizes linguistic features to adaptively enhance multi-scale visual features by integrating both deep and shallow features. The proposed dataset, benchmarking results, and the designed LGCE module provide insights into the design of a better RRSIS model. We will make our dataset and code publicly available.
Overcoming Language Bias in Remote Sensing Visual Question Answering via Adversarial Training
Jun 01, 2023
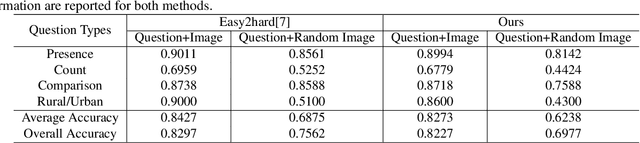
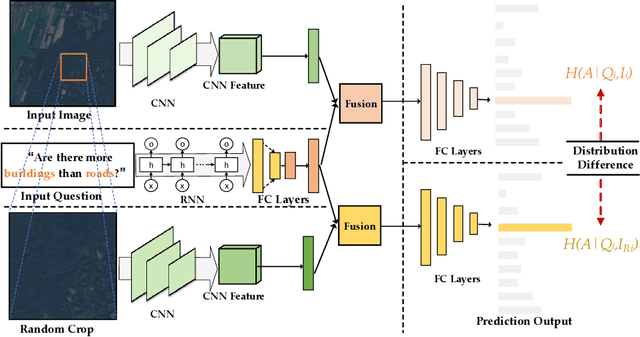
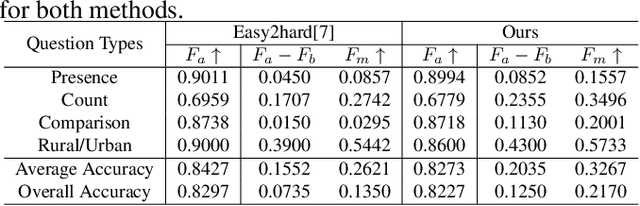
The Visual Question Answering (VQA) system offers a user-friendly interface and enables human-computer interaction. However, VQA models commonly face the challenge of language bias, resulting from the learned superficial correlation between questions and answers. To address this issue, in this study, we present a novel framework to reduce the language bias of the VQA for remote sensing data (RSVQA). Specifically, we add an adversarial branch to the original VQA framework. Based on the adversarial branch, we introduce two regularizers to constrain the training process against language bias. Furthermore, to evaluate the performance in terms of language bias, we propose a new metric that combines standard accuracy with the performance drop when incorporating question and random image information. Experimental results demonstrate the effectiveness of our method. We believe that our method can shed light on future work for reducing language bias on the RSVQA task.
Vision-Language Models in Remote Sensing: Current Progress and Future Trends
May 09, 2023



The remarkable achievements of ChatGPT and GPT-4 have sparked a wave of interest and research in the field of large language models for Artificial General Intelligence (AGI). These models provide us with intelligent solutions that are more similar to human thinking, enabling us to use general artificial intelligence to solve problems in various applications. However, in the field of remote sensing, the scientific literature on the implementation of AGI remains relatively scant. Existing AI-related research primarily focuses on visual understanding tasks while neglecting the semantic understanding of the objects and their relationships. This is where vision-language models excel, as they enable reasoning about images and their associated textual descriptions, allowing for a deeper understanding of the underlying semantics. Vision-language models can go beyond recognizing the objects in an image and can infer the relationships between them, as well as generate natural language descriptions of the image. This makes them better suited for tasks that require both visual and textual understanding, such as image captioning, text-based image retrieval, and visual question answering. This paper provides a comprehensive review of the research on vision-language models in remote sensing, summarizing the latest progress, highlighting the current challenges, and identifying potential research opportunities. Specifically, we review the application of vision-language models in several mainstream remote sensing tasks, including image captioning, text-based image generation, text-based image retrieval, visual question answering, scene classification, semantic segmentation, and object detection. For each task, we briefly describe the task background and review some representative works. Finally, we summarize the limitations of existing work and provide some possible directions for future development.
Multilingual Augmentation for Robust Visual Question Answering in Remote Sensing Images
Apr 07, 2023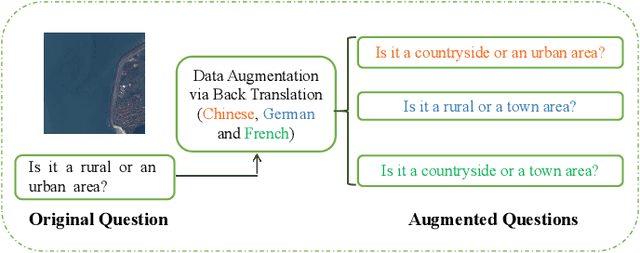
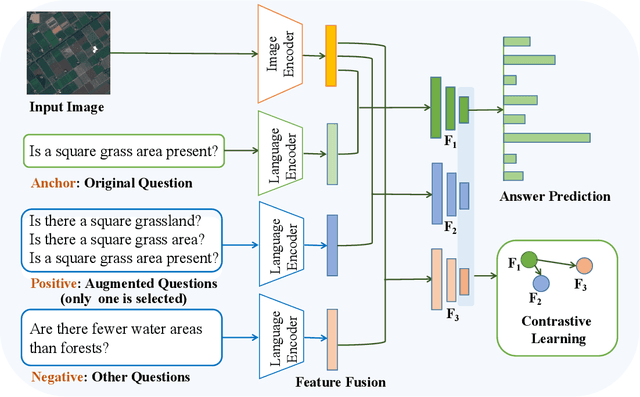
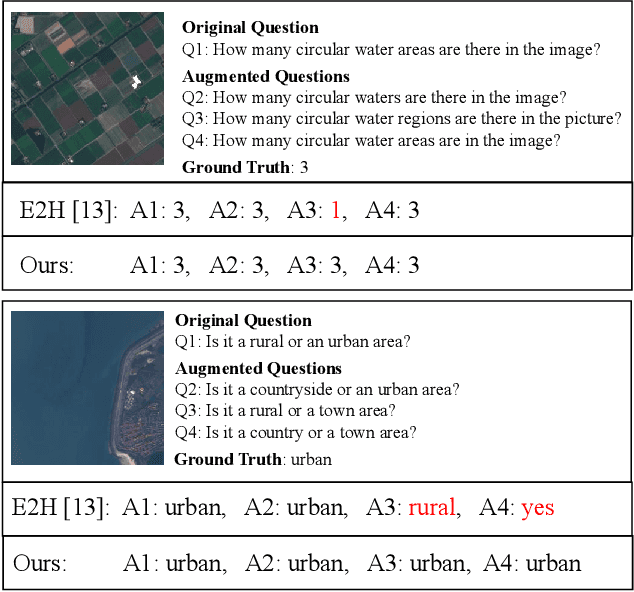
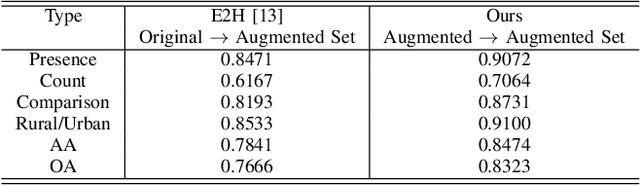
Aiming at answering questions based on the content of remotely sensed images, visual question answering for remote sensing data (RSVQA) has attracted much attention nowadays. However, previous works in RSVQA have focused little on the robustness of RSVQA. As we aim to enhance the reliability of RSVQA models, how to learn robust representations against new words and different question templates with the same meaning is the key challenge. With the proposed augmented dataset, we are able to obtain more questions in addition to the original ones with the same meaning. To make better use of this information, in this study, we propose a contrastive learning strategy for training robust RSVQA models against diverse question templates and words. Experimental results demonstrate that the proposed augmented dataset is effective in improving the robustness of the RSVQA model. In addition, the contrastive learning strategy performs well on the low resolution (LR) dataset.
From Easy to Hard: Learning Language-guided Curriculum for Visual Question Answering on Remote Sensing Data
May 06, 2022
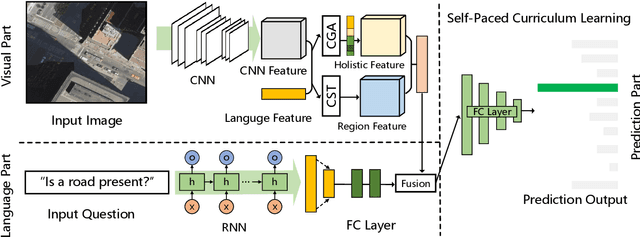
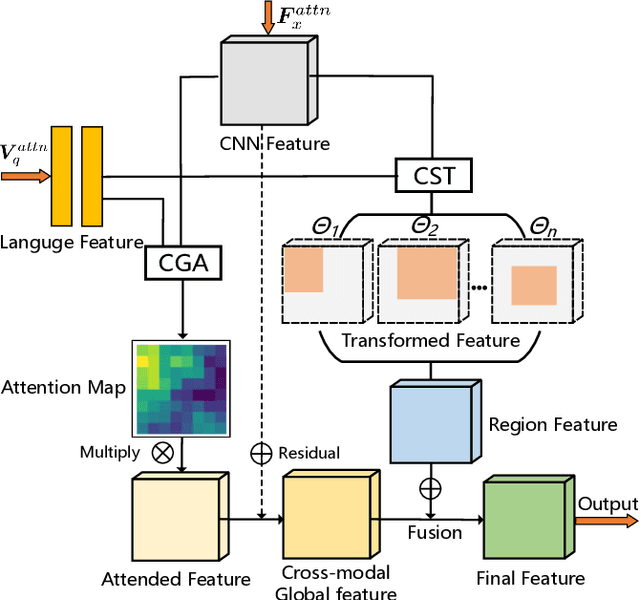
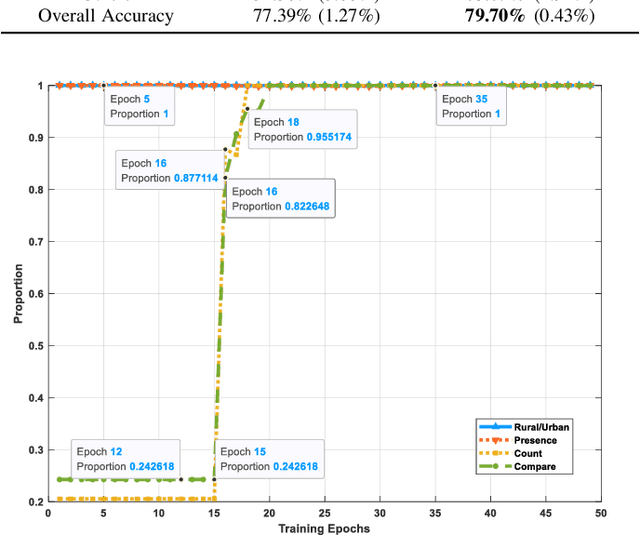
Visual question answering (VQA) for remote sensing scene has great potential in intelligent human-computer interaction system. Although VQA in computer vision has been widely researched, VQA for remote sensing data (RSVQA) is still in its infancy. There are two characteristics that need to be specially considered for the RSVQA task. 1) No object annotations are available in RSVQA datasets, which makes it difficult for models to exploit informative region representation; 2) There are questions with clearly different difficulty levels for each image in the RSVQA task. Directly training a model with questions in a random order may confuse the model and limit the performance. To address these two problems, in this paper, a multi-level visual feature learning method is proposed to jointly extract language-guided holistic and regional image features. Besides, a self-paced curriculum learning (SPCL)-based VQA model is developed to train networks with samples in an easy-to-hard way. To be more specific, a language-guided SPCL method with a soft weighting strategy is explored in this work. The proposed model is evaluated on three public datasets, and extensive experimental results show that the proposed RSVQA framework can achieve promising performance.
Change Detection Meets Visual Question Answering
Dec 12, 2021
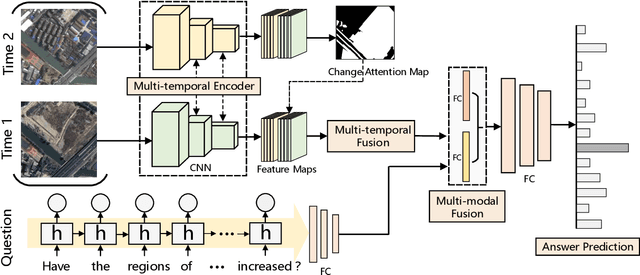

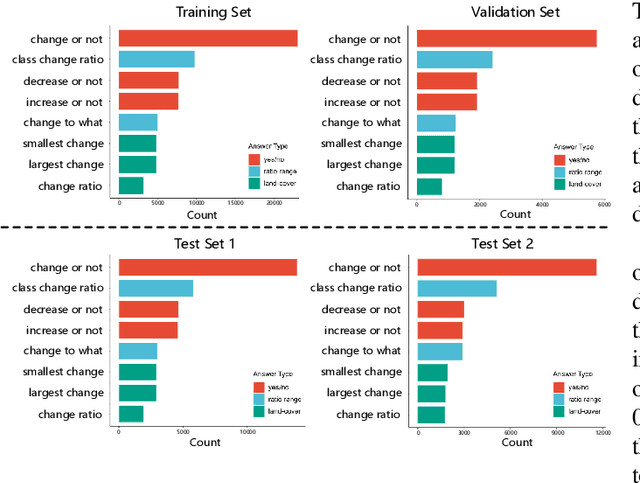
The Earth's surface is continually changing, and identifying changes plays an important role in urban planning and sustainability. Although change detection techniques have been successfully developed for many years, these techniques are still limited to experts and facilitators in related fields. In order to provide every user with flexible access to change information and help them better understand land-cover changes, we introduce a novel task: change detection-based visual question answering (CDVQA) on multi-temporal aerial images. In particular, multi-temporal images can be queried to obtain high level change-based information according to content changes between two input images. We first build a CDVQA dataset including multi-temporal image-question-answer triplets using an automatic question-answer generation method. Then, a baseline CDVQA framework is devised in this work, and it contains four parts: multi-temporal feature encoding, multi-temporal fusion, multi-modal fusion, and answer prediction. In addition, we also introduce a change enhancing module to multi-temporal feature encoding, aiming at incorporating more change-related information. Finally, effects of different backbones and multi-temporal fusion strategies are studied on the performance of CDVQA task. The experimental results provide useful insights for developing better CDVQA models, which are important for future research on this task. We will make our dataset and code publicly available.
GETNET: A General End-to-end Two-dimensional CNN Framework for Hyperspectral Image Change Detection
May 05, 2019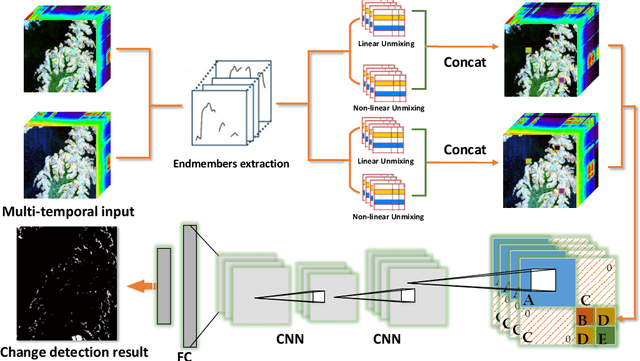

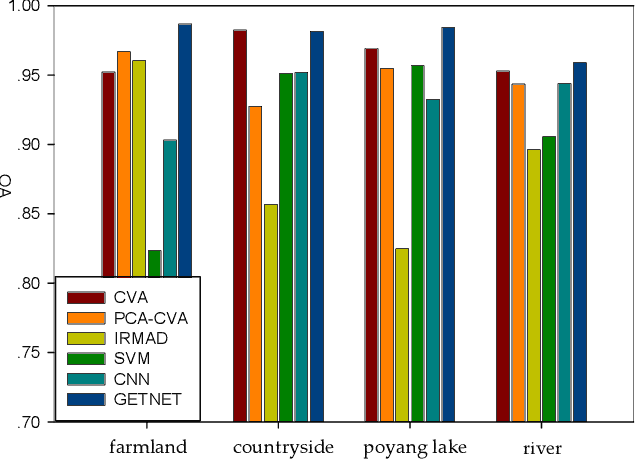
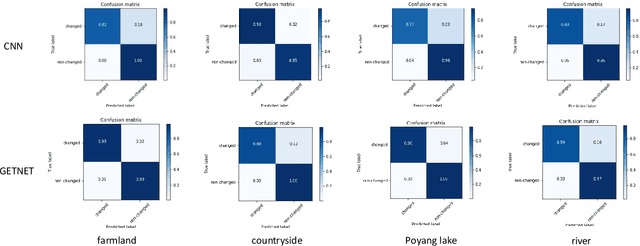
Change detection (CD) is an important application of remote sensing, which provides timely change information about large-scale Earth surface. With the emergence of hyperspectral imagery, CD technology has been greatly promoted, as hyperspectral data with the highspectral resolution are capable of detecting finer changes than using the traditional multispectral imagery. Nevertheless, the high dimension of hyperspectral data makes it difficult to implement traditional CD algorithms. Besides, endmember abundance information at subpixel level is often not fully utilized. In order to better handle high dimension problem and explore abundance information, this paper presents a General End-to-end Two-dimensional CNN (GETNET) framework for hyperspectral image change detection (HSI-CD). The main contributions of this work are threefold: 1) Mixed-affinity matrix that integrates subpixel representation is introduced to mine more cross-channel gradient features and fuse multi-source information; 2) 2-D CNN is designed to learn the discriminative features effectively from multi-source data at a higher level and enhance the generalization ability of the proposed CD algorithm; 3) A new HSI-CD data set is designed for the objective comparison of different methods. Experimental results on real hyperspectral data sets demonstrate the proposed method outperforms most of the state-of-the-arts.