 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Easy to Hard: Learning Language-guided Curriculum for Visual Question Answering on Remote Sensing Data
Paper and Code
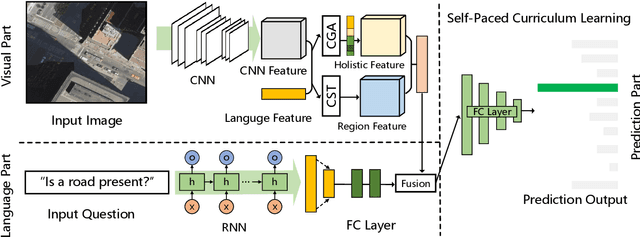
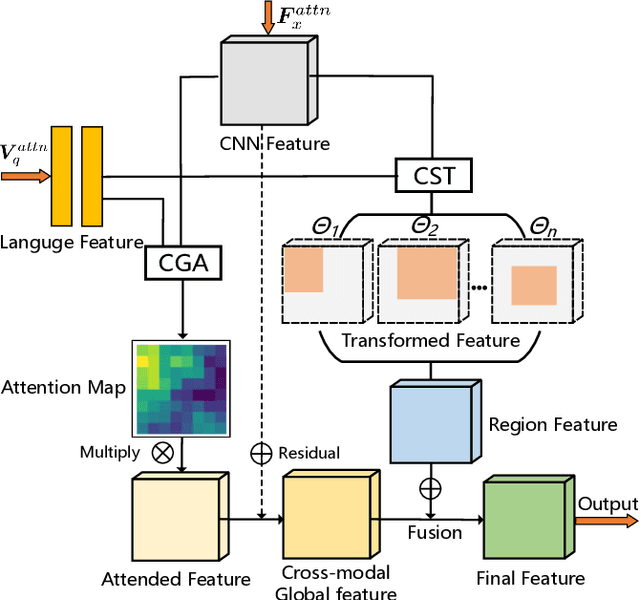
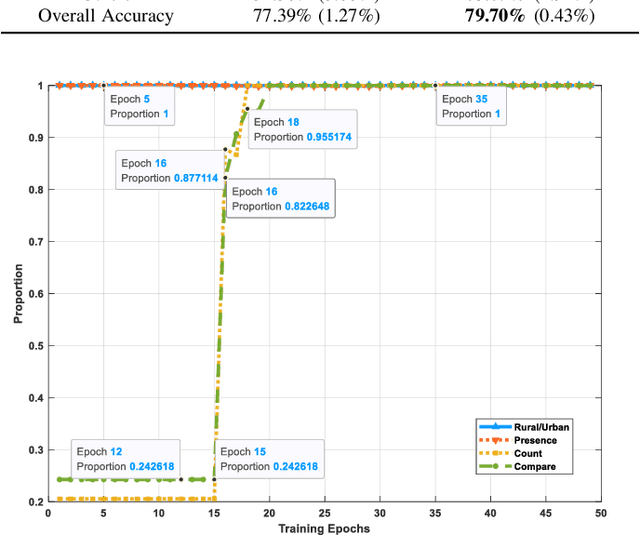
Visual question answering (VQA) for remote sensing scene has great potential in intelligent human-computer interaction system. Although VQA in computer vision has been widely researched, VQA for remote sensing data (RSVQA) is still in its infancy. There are two characteristics that need to be specially considered for the RSVQA task. 1) No object annotations are available in RSVQA datasets, which makes it difficult for models to exploit informative region representation; 2) There are questions with clearly different difficulty levels for each image in the RSVQA task. Directly training a model with questions in a random order may confuse the model and limit the performance. To address these two problems, in this paper, a multi-level visual feature learning method is proposed to jointly extract language-guided holistic and regional image features. Besides, a self-paced curriculum learning (SPCL)-based VQA model is developed to train networks with samples in an easy-to-hard way. To be more specific, a language-guided SPCL method with a soft weighting strategy is explored in this work. The proposed model is evaluated on three public datasets, and extensive experimental results show that the proposed RSVQA framework can achieve promising performance.