 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025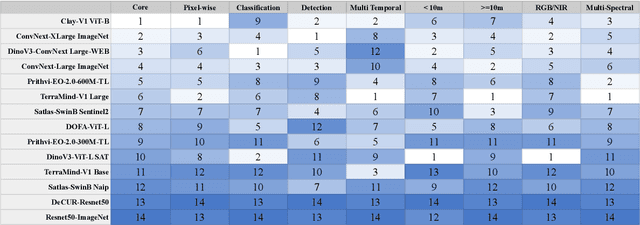
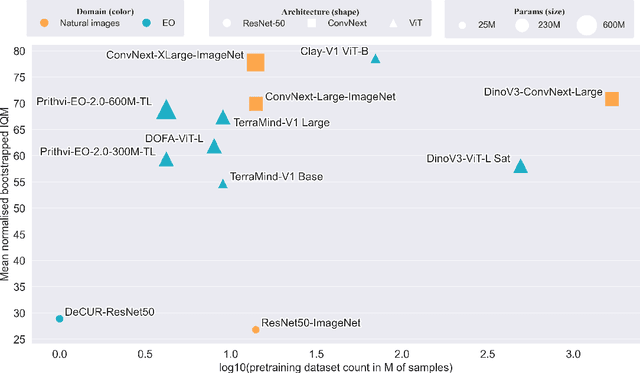
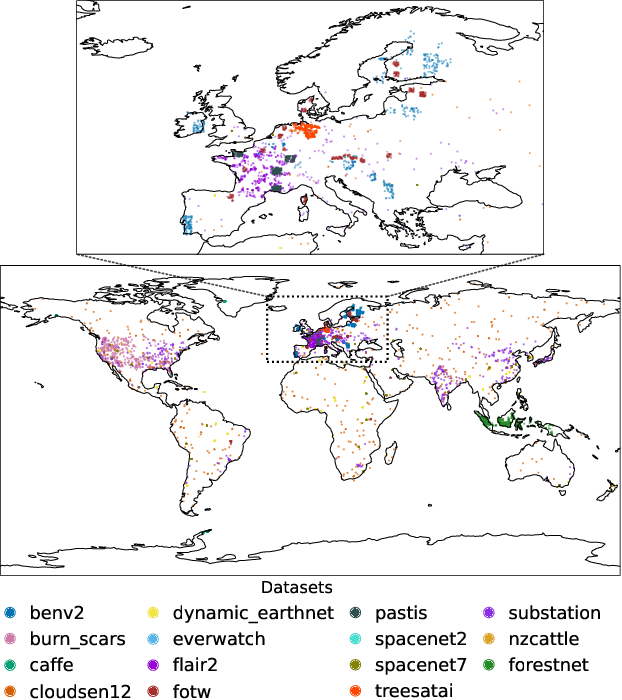
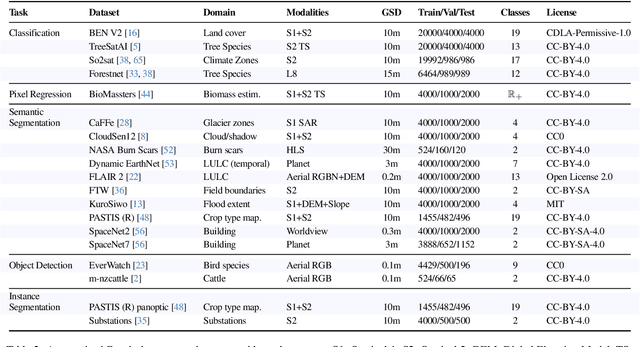
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
Panopticon: Advancing Any-Sensor Foundation Models for Earth Observation
Mar 13, 2025Earth observation (EO) data features diverse sensing platforms with varying spectral bands, spatial resolutions, and sensing modalities. While most prior work has constrained inputs to fixed sensors, a new class of any-sensor foundation models able to process arbitrary sensors has recently emerged. Contributing to this line of work, we propose Panopticon, an any-sensor foundation model built on the DINOv2 framework. We extend DINOv2 by (1) treating images of the same geolocation across sensors as natural augmentations, (2) subsampling channels to diversify spectral input, and (3) adding a cross attention over channels as a flexible patch embedding mechanism. By encoding the wavelength and modes of optical and synthetic aperture radar sensors, respectively, Panopticon can effectively process any combination of arbitrary channels. In extensive evaluations, we achieve state-of-the-art performance on GEO-Bench, especially on the widely-used Sentinel-1 and Sentinel-2 sensors, while out-competing other any-sensor models, as well as domain adapted fixed-sensor models on unique sensor configurations. Panopticon enables immediate generalization to both existing and future satellite platforms, advancing sensor-agnostic EO.
GeoLangBind: Unifying Earth Observation with Agglomerative Vision-Language Foundation Models
Mar 08, 2025Earth observation (EO) data, collected from diverse sensors with varying imaging principles, present significant challenges in creating unified analytical frameworks. We present GeoLangBind, a novel agglomerative vision--language foundation model that bridges the gap between heterogeneous EO data modalities using language as a unifying medium. Our approach aligns different EO data types into a shared language embedding space, enabling seamless integration and complementary feature learning from diverse sensor data. To achieve this, we construct a large-scale multimodal image--text dataset, GeoLangBind-2M, encompassing six data modalities. GeoLangBind leverages this dataset to develop a zero-shot foundation model capable of processing arbitrary numbers of EO data channels as input. Through our designed Modality-aware Knowledge Agglomeration (MaKA) module and progressive multimodal weight merging strategy, we create a powerful agglomerative foundation model that excels in both zero-shot vision--language comprehension and fine-grained visual understanding. Extensive evaluation across 23 datasets covering multiple tasks demonstrates GeoLangBind's superior performance and versatility in EO applications, offering a robust framework for various environmental monitoring and analysis tasks. The dataset and pretrained models will be publicly available.
Lightning UQ Box: A Comprehensive Framework for Uncertainty Quantification in Deep Learning
Oct 04, 2024



Uncertainty quantification (UQ) is an essential tool for applying deep neural networks (DNNs) to real world tasks, as it attaches a degree of confidence to DNN outputs. However, despite its benefits, UQ is often left out of the standard DNN workflow due to the additional technical knowledge required to apply and evaluate existing UQ procedures. Hence there is a need for a comprehensive toolbox that allows the user to integrate UQ into their modelling workflow, without significant overhead. We introduce \texttt{Lightning UQ Box}: a unified interface for applying and evaluating various approaches to UQ. In this paper, we provide a theoretical and quantitative comparison of the wide range of state-of-the-art UQ methods implemented in our toolbox. We focus on two challenging vision tasks: (i) estimating tropical cyclone wind speeds from infrared satellite imagery and (ii) estimating the power output of solar panels from RGB images of the sky. By highlighting the differences between methods our results demonstrate the need for a broad and approachable experimental framework for UQ, that can be used for benchmarking UQ methods. The toolbox, example implementations, and further information are available at: https://github.com/lightning-uq-box/lightning-uq-box
Uncertainty Aware Tropical Cyclone Wind Speed Estimation from Satellite Data
Apr 12, 2024



Deep neural networks (DNNs) have been successfully applied to earth observation (EO) data and opened new research avenues. Despite the theoretical and practical advances of these techniques, DNNs are still considered black box tools and by default are designed to give point predictions. However, the majority of EO applications demand reliable uncertainty estimates that can support practitioners in critical decision making tasks. This work provides a theoretical and quantitative comparison of existing uncertainty quantification methods for DNNs applied to the task of wind speed estimation in satellite imagery of tropical cyclones. We provide a detailed evaluation of predictive uncertainty estimates from state-of-the-art uncertainty quantification (UQ) methods for DNNs. We find that predictive uncertainties can be utilized to further improve accuracy and analyze the predictive uncertainties of different methods across storm categories.
SSL4EO-L: Datasets and Foundation Models for Landsat Imagery
Jun 15, 2023



The Landsat program is the longest-running Earth observation program in history, with 50+ years of data acquisition by 8 satellites. The multispectral imagery captured by sensors onboard these satellites is critical for a wide range of scientific fields. Despite the increasing popularity of deep learning and remote sensing, the majority of researchers still use decision trees and random forests for Landsat image analysis due to the prevalence of small labeled datasets and lack of foundation models. In this paper, we introduce SSL4EO-L, the first ever dataset designed for Self-Supervised Learning for Earth Observation for the Landsat family of satellites (including 3 sensors and 2 product levels) and the largest Landsat dataset in history (5M image patches). Additionally, we modernize and re-release the L7 Irish and L8 Biome cloud detection datasets, and introduce the first ML benchmark datasets for Landsats 4-5 TM and Landsat 7 ETM+ SR. Finally, we pre-train the first foundation models for Landsat imagery using SSL4EO-L and evaluate their performance on multiple semantic segmentation tasks. All datasets and model weights are available via the TorchGeo (https://github.com/microsoft/torchgeo) library, making reproducibility and experimentation easy, and enabling scientific advancements in the burgeoning field of remote sensing for a myriad of downstream applications.
GEO-Bench: Toward Foundation Models for Earth Monitoring
Jun 06, 2023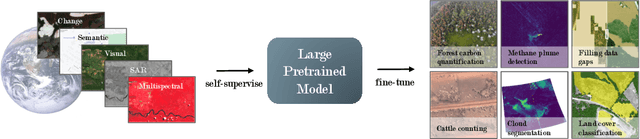
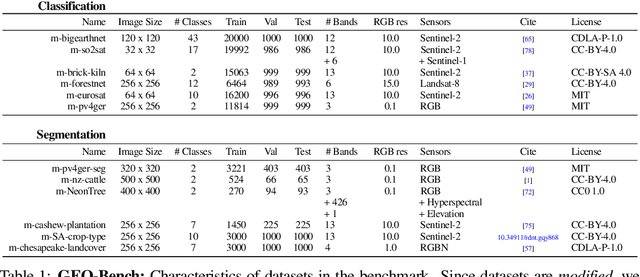

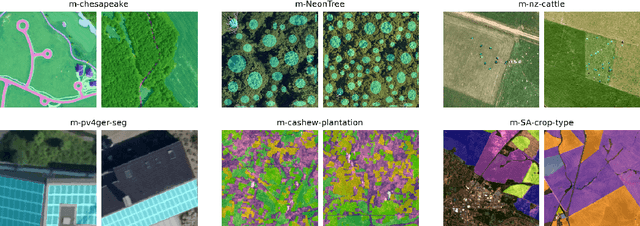
Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing. Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited. To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models. We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.