 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Augmentation for Robust Visual Question Answering in Remote Sensing Images
Paper and Code
Apr 07, 2023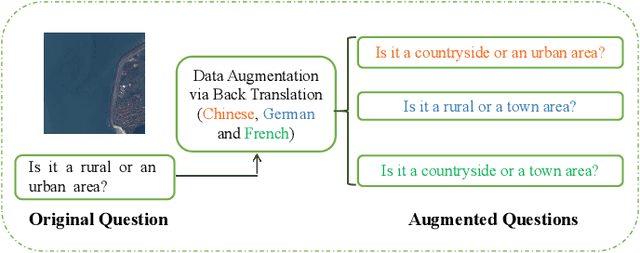
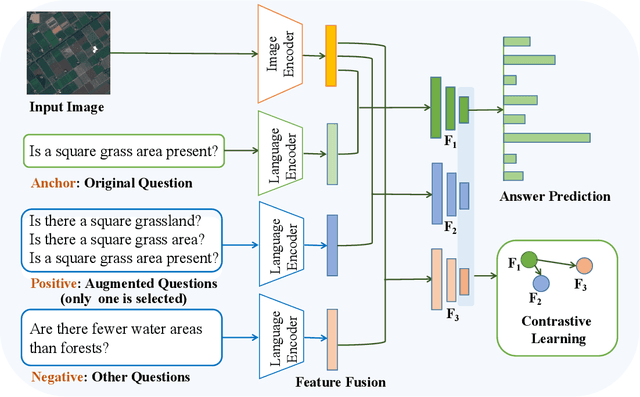
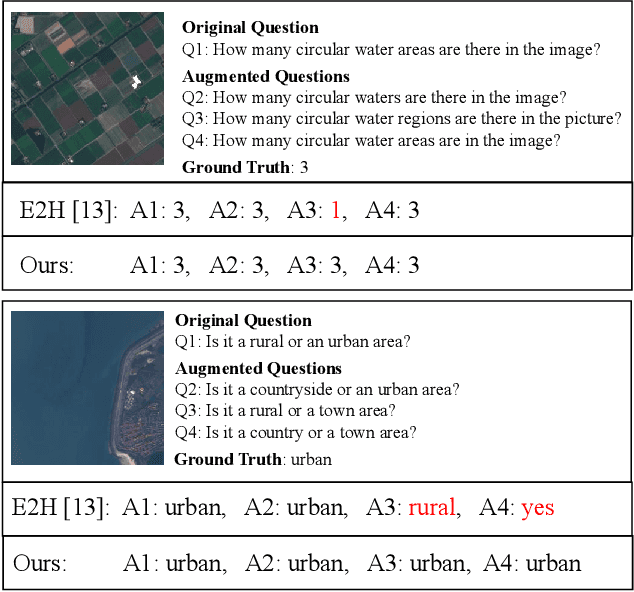
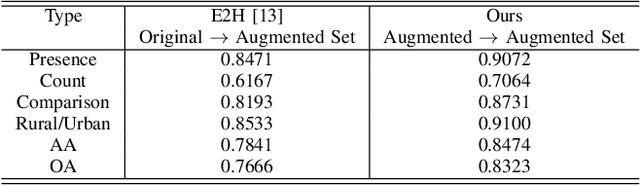
Aiming at answering questions based on the content of remotely sensed images, visual question answering for remote sensing data (RSVQA) has attracted much attention nowadays. However, previous works in RSVQA have focused little on the robustness of RSVQA. As we aim to enhance the reliability of RSVQA models, how to learn robust representations against new words and different question templates with the same meaning is the key challenge. With the proposed augmented dataset, we are able to obtain more questions in addition to the original ones with the same meaning. To make better use of this information, in this study, we propose a contrastive learning strategy for training robust RSVQA models against diverse question templates and words. Experimental results demonstrate that the proposed augmented dataset is effective in improving the robustness of the RSVQA model. In addition, the contrastive learning strategy performs well on the low resolution (LR) dataset.