 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-embedded Fourier Neural Network for Partial Differential Equations
Jul 15, 2024
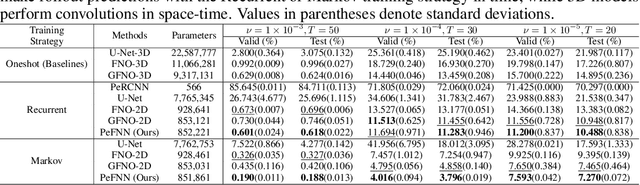
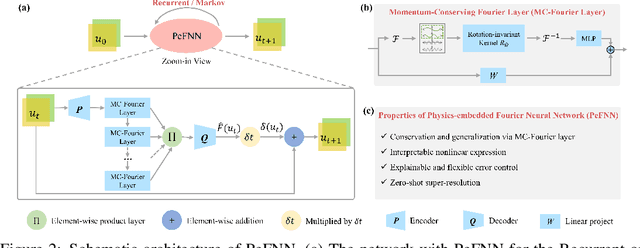

We consider solving complex spatiotemporal dynamical systems governed by partial differential equations (PDEs) using frequency domain-based discrete learning approaches, such as Fourier neural operators. Despite their widespread use for approximating nonlinear PDEs, the majority of these methods neglect fundamental physical laws and lack interpretability. We address these shortcomings by introducing Physics-embedded Fourier Neural Networks (PeFNN) with flexible and explainable error control. PeFNN is designed to enforce momentum conservation and yields interpretable nonlinear expressions by utilizing unique multi-scale momentum-conserving Fourier (MC-Fourier) layers and an element-wise product operation. The MC-Fourier layer is by design translation- and rotation-invariant in the frequency domain, serving as a plug-and-play module that adheres to the laws of momentum conservation. PeFNN establishes a new state-of-the-art in solving widely employed spatiotemporal PDEs and generalizes well across input resolutions. Further, we demonstrate its outstanding performance for challenging real-world applications such as large-scale flood simulations.
On the Foundations of Earth and Climate Foundation Models
May 07, 2024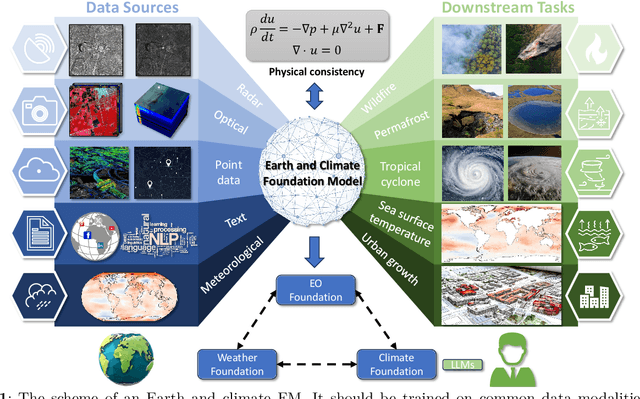

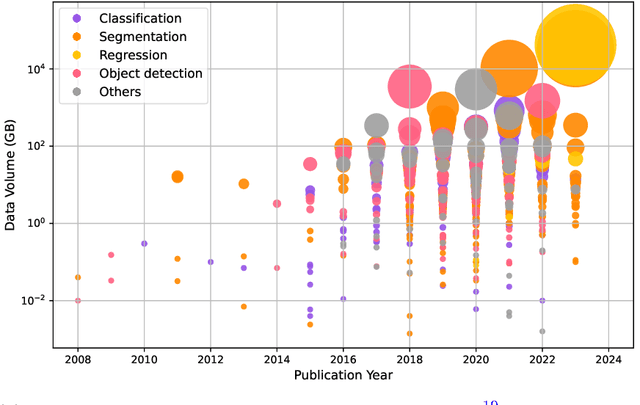
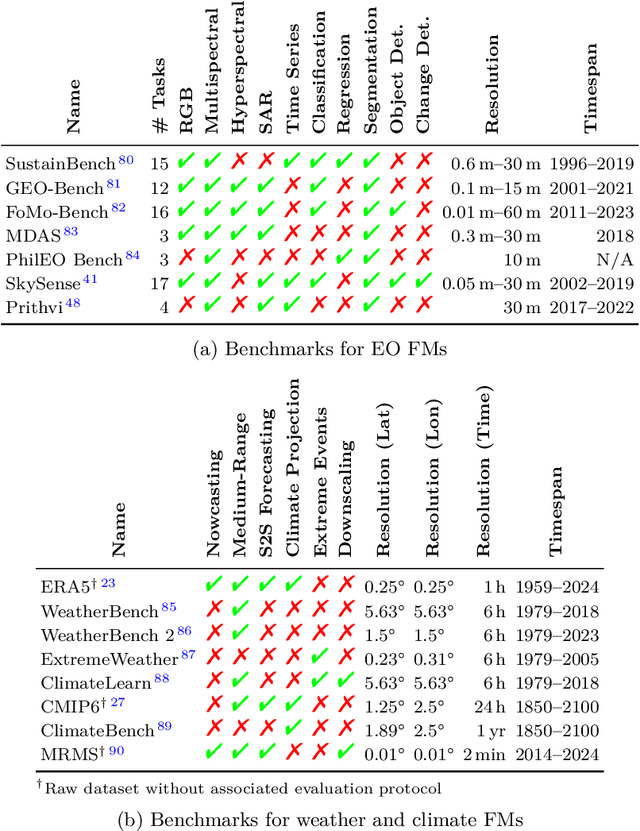
Foundation models have enormous potential in advancing Earth and climate sciences, however, current approaches may not be optimal as they focus on a few basic features of a desirable Earth and climate foundation model. Crafting the ideal Earth foundation model, we define eleven features which would allow such a foundation model to be beneficial for any geoscientific downstream application in an environmental- and human-centric manner.We further shed light on the way forward to achieve the ideal model and to evaluate Earth foundation models. What comes after foundation models? Energy efficient adaptation, adversarial defenses, and interpretability are among the emerging directions.
Large-scale flood modeling and forecasting with FloodCast
Mar 18, 2024



Large-scale hydrodynamic models generally rely on fixed-resolution spatial grids and model parameters as well as incurring a high computational cost. This limits their ability to accurately forecast flood crests and issue time-critical hazard warnings. In this work, we build a fast, stable, accurate, resolution-invariant, and geometry-adaptative flood modeling and forecasting framework that can perform at large scales, namely FloodCast. The framework comprises two main modules: multi-satellite observation and hydrodynamic modeling. In the multi-satellite observation module, a real-time unsupervised change detection method and a rainfall processing and analysis tool are proposed to harness the full potential of multi-satellite observations in large-scale flood prediction. In the hydrodynamic modeling module, a geometry-adaptive physics-informed neural solver (GeoPINS) is introduced, benefiting from the absence of a requirement for training data in physics-informed neural networks and featuring a fast, accurate, and resolution-invariant architecture with Fourier neural operators. GeoPINS demonstrates impressive performance on popular PDEs across regular and irregular domains. Building upon GeoPINS, we propose a sequence-to-sequence GeoPINS model to handle long-term temporal series and extensive spatial domains in large-scale flood modeling. Next, we establish a benchmark dataset in the 2022 Pakistan flood to assess various flood prediction methods. Finally, we validate the model in three dimensions - flood inundation range, depth, and transferability of spatiotemporal downscaling. Traditional hydrodynamics and sequence-to-sequence GeoPINS exhibit exceptional agreement during high water levels, while comparative assessments with SAR-based flood depth data show that sequence-to-sequence GeoPINS outperforms traditional hydrodynamics, with smaller prediction errors.
Multi-task deep learning for large-scale building detail extraction from high-resolution satellite imagery
Oct 29, 2023



Understanding urban dynamics and promoting sustainable development requires comprehensive insights about buildings. While geospatial artificial intelligence has advanced the extraction of such details from Earth observational data, existing methods often suffer from computational inefficiencies and inconsistencies when compiling unified building-related datasets for practical applications. To bridge this gap, we introduce the Multi-task Building Refiner (MT-BR), an adaptable neural network tailored for simultaneous extraction of spatial and attributional building details from high-resolution satellite imagery, exemplified by building rooftops, urban functional types, and roof architectural types. Notably, MT-BR can be fine-tuned to incorporate additional building details, extending its applicability. For large-scale applications, we devise a novel spatial sampling scheme that strategically selects limited but representative image samples. This process optimizes both the spatial distribution of samples and the urban environmental characteristics they contain, thus enhancing extraction effectiveness while curtailing data preparation expenditures. We further enhance MT-BR's predictive performance and generalization capabilities through the integration of advanced augmentation techniques. Our quantitative results highlight the efficacy of the proposed methods. Specifically, networks trained with datasets curated via our sampling method demonstrate improved predictive accuracy relative to those using alternative sampling approaches, with no alterations to network architecture. Moreover, MT-BR consistently outperforms other state-of-the-art methods in extracting building details across various metrics. The real-world practicality is also demonstrated in an application across Shanghai, generating a unified dataset that encompasses both the spatial and attributional details of buildings.
Physics-aware Machine Learning Revolutionizes Scientific Paradigm for Machine Learning and Process-based Hydrology
Oct 20, 2023



Accurate hydrological understanding and water cycle prediction are crucial for addressing scientific and societal challenges associated with the management of water resources, particularly under the dynamic influence of anthropogenic climate change. Existing reviews predominantly concentrate on the development of machine learning (ML) in this field, yet there is a clear distinction between hydrology and ML as separate paradigms. Here, we introduce physics-aware ML as a transformative approach to overcome the perceived barrier and revolutionize both fields. Specifically, we present a comprehensive review of the physics-aware ML methods, building a structured community (PaML) of existing methodologies that integrate prior physical knowledge or physics-based modeling into ML. We systematically analyze these PaML methodologies with respect to four aspects: physical data-guided ML, physics-informed ML, physics-embedded ML, and physics-aware hybrid learning. PaML facilitates ML-aided hypotheses, accelerating insights from big data and fostering scientific discoveries. We first conduct a systematic review of hydrology in PaML, including rainfall-runoff hydrological processes and hydrodynamic processes, and highlight the most promising and challenging directions for different objectives and PaML methods. Finally, a new PaML-based hydrology platform, termed HydroPML, is released as a foundation for hydrological applications. HydroPML enhances the explainability and causality of ML and lays the groundwork for the digital water cycle's realization. The HydroPML platform is publicly available at https://hydropml.github.io/.
UCDFormer: Unsupervised Change Detection Using a Transformer-driven Image Translation
Aug 02, 2023
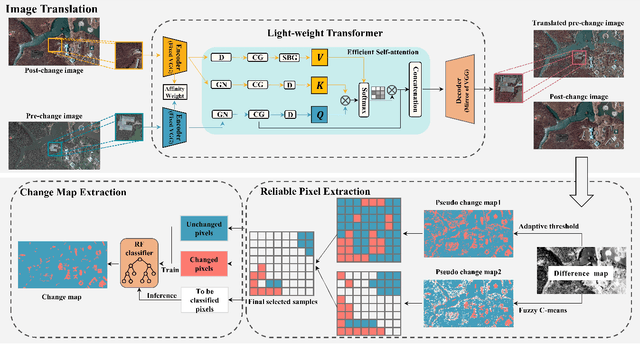


Change detection (CD) by comparing two bi-temporal images is a crucial task in remote sensing. With the advantages of requiring no cumbersome labeled change information, unsupervised CD has attracted extensive attention in the community. However, existing unsupervised CD approaches rarely consider the seasonal and style differences incurred by the illumination and atmospheric conditions in multi-temporal images. To this end, we propose a change detection with domain shift setting for remote sensing images. Furthermore, we present a novel unsupervised CD method using a light-weight transformer, called UCDFormer. Specifically, a transformer-driven image translation composed of a light-weight transformer and a domain-specific affinity weight is first proposed to mitigate domain shift between two images with real-time efficiency. After image translation, we can generate the difference map between the translated before-event image and the original after-event image. Then, a novel reliable pixel extraction module is proposed to select significantly changed/unchanged pixel positions by fusing the pseudo change maps of fuzzy c-means clustering and adaptive threshold. Finally, a binary change map is obtained based on these selected pixel pairs and a binary classifier. Experimental results on different unsupervised CD tasks with seasonal and style changes demonstrate the effectiveness of the proposed UCDFormer. For example, compared with several other related methods, UCDFormer improves performance on the Kappa coefficient by more than 12\%. In addition, UCDFormer achieves excellent performance for earthquake-induced landslide detection when considering large-scale applications. The code is available at \url{https://github.com/zhu-xlab/UCDFormer}
FlexDelta: A flexure-based fully decoupled parallel $xyz$ positioning stage with long stroke
Jul 19, 2023Decoupled parallel $xyz$ positioning stages with large stroke have been desired in high-speed and precise positioning fields. However, currently such stages are either short in stroke or unqualified in parasitic motion and coupling rate. This paper proposes a novel flexure-based decoupled parallel $xyz$ positioning stage (FlexDelta) and conducts its conceptual design, modeling, and experimental study. Firstly, the working principle of FlexDelta is introduced, followed by its mechanism design with flexure. Secondly, the stiffness model of flexure is established via matrix-based Castigliano's second theorem, and the influence of its lateral stiffness on the stiffness model of FlexDelta is comprehensively investigated and then optimally designed. Finally, experimental study was carried out based on the prototype fabricated. The results reveal that the positioning stage features centimeter-stroke in three axes, with coupling rate less than 0.53%, parasitic motion less than 1.72 mrad over full range. And its natural frequencies are 20.8 Hz, 20.8 Hz, and 22.4 Hz for $x$, $y$, and $z$ axis respectively. Multi-axis path tracking tests were also carried out, which validates its dynamic performance with micrometer error.
DisasterNets: Embedding Machine Learning in Disaster Mapping
Jun 16, 2023



Disaster mapping is a critical task that often requires on-site experts and is time-consuming. To address this, a comprehensive framework is presented for fast and accurate recognition of disasters using machine learning, termed DisasterNets. It consists of two stages, space granulation and attribute granulation. The space granulation stage leverages supervised/semi-supervised learning, unsupervised change detection, and domain adaptation with/without source data techniques to handle different disaster mapping scenarios. Furthermore, the disaster database with the corresponding geographic information field properties is built by using the attribute granulation stage. The framework is applied to earthquake-triggered landslide mapping and large-scale flood mapping. The results demonstrate a competitive performance for high-precision, high-efficiency, and cross-scene recognition of disasters. To bridge the gap between disaster mapping and machine learning communities, we will provide an openly accessible tool based on DisasterNets. The framework and tool will be available at https://github.com/HydroPML/DisasterNets.
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Apr 16, 2023



Image keypoints and descriptors play a crucial role in many visual measurement tasks. In recent years, deep neural networks have been widely used to improve the performance of keypoint and descriptor extraction. However, the conventional convolution operations do not provide the geometric invariance required for the descriptor. To address this issue, we propose the Sparse Deformable Descriptor Head (SDDH), which learns the deformable positions of supporting features for each keypoint and constructs deformable descriptors. Furthermore, SDDH extracts descriptors at sparse keypoints instead of a dense descriptor map, which enables efficient extraction of descriptors with strong expressiveness. In addition, we relax the neural reprojection error (NRE) loss from dense to sparse to train the extracted sparse descriptors. Experimental results show that the proposed network is both efficient and powerful in various visual measurement tasks, including image matching, 3D reconstruction, and visual relocalization.
Event Voxel Set Transformer for Spatiotemporal Representation Learning on Event Streams
Mar 07, 2023Event cameras are neuromorphic vision sensors representing visual information as sparse and asynchronous event streams. Most state-of-the-art event-based methods project events into dense frames and process them with conventional learning models. However, these approaches sacrifice the sparsity and high temporal resolution of event data, resulting in a large model size and high computational complexity. To fit the sparse nature of events and sufficiently explore their implicit relationship, we develop a novel attention-aware framework named Event Voxel Set Transformer (EVSTr) for spatiotemporal representation learning on event streams. It first converts the event stream into a voxel set and then hierarchically aggregates voxel features to obtain robust representations. The core of EVSTr is an event voxel transformer encoder to extract discriminative spatiotemporal features, which consists of two well-designed components, including a multi-scale neighbor embedding layer (MNEL) for local information aggregation and a voxel self-attention layer (VSAL) for global representation modeling. Enabling the framework to incorporate a long-term temporal structure, we introduce a segmental consensus strategy for modeling motion patterns over a sequence of segmented voxel sets. We evaluate the proposed framework on two event-based tasks: object classification and action recognition. Comprehensive experiments show that EVSTr achieves state-of-the-art performance while maintaining low model complexity. Additionally, we present a new dataset (NeuroHAR) recorded in challenging visual scenarios to address the lack of real-world event-based datasets for action recognition.