 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
How Does the Lagrangian Guide Safe Reinforcement Learning through Diffusion Models?
Feb 02, 2026Diffusion policy sampling enables reinforcement learning (RL) to represent multimodal action distributions beyond suboptimal unimodal Gaussian policies. However, existing diffusion-based RL methods primarily focus on offline settings for reward maximization, with limited consideration of safety in online settings. To address this gap, we propose Augmented Lagrangian-Guided Diffusion (ALGD), a novel algorithm for off-policy safe RL. By revisiting optimization theory and energy-based model, we show that the instability of primal-dual methods arises from the non-convex Lagrangian landscape. In diffusion-based safe RL, the Lagrangian can be interpreted as an energy function guiding the denoising dynamics. Counterintuitively, direct usage destabilizes both policy generation and training. ALGD resolves this issue by introducing an augmented Lagrangian that locally convexifies the energy landscape, yielding a stabilized policy generation and training process without altering the distribution of the optimal policy. Theoretical analysis and extensive experiments demonstrate that ALGD is both theoretically grounded and empirically effective, achieving strong and stable performance across diverse environments.
On Stability and Robustness of Diffusion Posterior Sampling for Bayesian Inverse Problems
Feb 02, 2026Diffusion models have recently emerged as powerful learned priors for Bayesian inverse problems (BIPs). Diffusion-based solvers rely on a presumed likelihood for the observations in BIPs to guide the generation process. However, the link between likelihood and recovery quality for BIPs is unclear in previous works. We bridge this gap by characterizing the posterior approximation error and proving the \emph{stability} of the diffusion-based solvers. Meanwhile, an immediate result of our findings on stability demonstrates the lack of robustness in diffusion-based solvers, which remains unexplored. This can degrade performance when the presumed likelihood mismatches the unknown true data generation processes. To address this issue, we propose a simple yet effective solution, \emph{robust diffusion posterior sampling}, which is provably \emph{robust} and compatible with existing gradient-based posterior samplers. Empirical results on scientific inverse problems and natural image tasks validate the effectiveness and robustness of our method, showing consistent performance improvements under challenging likelihood misspecifications.
MemoCue: Empowering LLM-Based Agents for Human Memory Recall via Strategy-Guided Querying
Jul 31, 2025Agent-assisted memory recall is one critical research problem in the field of human-computer interaction. In conventional methods, the agent can retrieve information from its equipped memory module to help the person recall incomplete or vague memories. The limited size of memory module hinders the acquisition of complete memories and impacts the memory recall performance in practice. Memory theories suggest that the person's relevant memory can be proactively activated through some effective cues. Inspired by this, we propose a novel strategy-guided agent-assisted memory recall method, allowing the agent to transform an original query into a cue-rich one via the judiciously designed strategy to help the person recall memories. To this end, there are two key challenges. (1) How to choose the appropriate recall strategy for diverse forgetting scenarios with distinct memory-recall characteristics? (2) How to obtain the high-quality responses leveraging recall strategies, given only abstract and sparsely annotated strategy patterns? To address the challenges, we propose a Recall Router framework. Specifically, we design a 5W Recall Map to classify memory queries into five typical scenarios and define fifteen recall strategy patterns across the corresponding scenarios. We then propose a hierarchical recall tree combined with the Monte Carlo Tree Search algorithm to optimize the selection of strategy and the generation of strategy responses. We construct an instruction tuning dataset and fine-tune multiple open-source large language models (LLMs) to develop MemoCue, an agent that excels in providing memory-inspired responses. Experiments on three representative datasets show that MemoCue surpasses LLM-based methods by 17.74% in recall inspiration. Further human evaluation highlights its advantages in memory-recall applications.
Multi-task deep learning for large-scale building detail extraction from high-resolution satellite imagery
Oct 29, 2023



Understanding urban dynamics and promoting sustainable development requires comprehensive insights about buildings. While geospatial artificial intelligence has advanced the extraction of such details from Earth observational data, existing methods often suffer from computational inefficiencies and inconsistencies when compiling unified building-related datasets for practical applications. To bridge this gap, we introduce the Multi-task Building Refiner (MT-BR), an adaptable neural network tailored for simultaneous extraction of spatial and attributional building details from high-resolution satellite imagery, exemplified by building rooftops, urban functional types, and roof architectural types. Notably, MT-BR can be fine-tuned to incorporate additional building details, extending its applicability. For large-scale applications, we devise a novel spatial sampling scheme that strategically selects limited but representative image samples. This process optimizes both the spatial distribution of samples and the urban environmental characteristics they contain, thus enhancing extraction effectiveness while curtailing data preparation expenditures. We further enhance MT-BR's predictive performance and generalization capabilities through the integration of advanced augmentation techniques. Our quantitative results highlight the efficacy of the proposed methods. Specifically, networks trained with datasets curated via our sampling method demonstrate improved predictive accuracy relative to those using alternative sampling approaches, with no alterations to network architecture. Moreover, MT-BR consistently outperforms other state-of-the-art methods in extracting building details across various metrics. The real-world practicality is also demonstrated in an application across Shanghai, generating a unified dataset that encompasses both the spatial and attributional details of buildings.
Meta-learning Control Variates: Variance Reduction with Limited Data
Mar 15, 2023
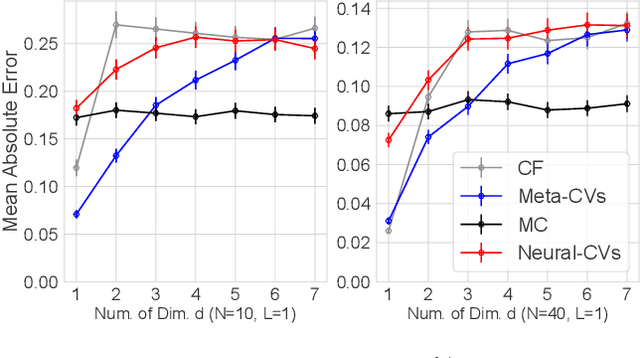
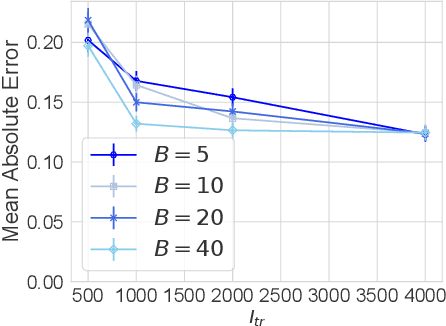
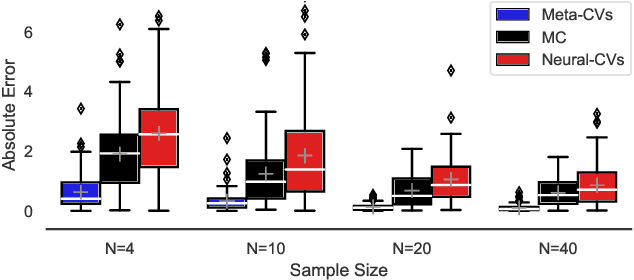
Control variates can be a powerful tool to reduce the variance of Monte Carlo estimators, but constructing effective control variates can be challenging when the number of samples is small. In this paper, we show that when a large number of related integrals need to be computed, it is possible to leverage the similarity between these integration tasks to improve performance even when the number of samples per task is very small. Our approach, called meta learning CVs (Meta-CVs), can be used for up to hundreds or thousands of tasks. Our empirical assessment indicates that Meta-CVs can lead to significant variance reduction in such settings, and our theoretical analysis establishes general conditions under which Meta-CVs can be successfully trained.
Whittle Index Based Scheduling Policy for Minimizing the Cost of Age of Information
Sep 13, 2021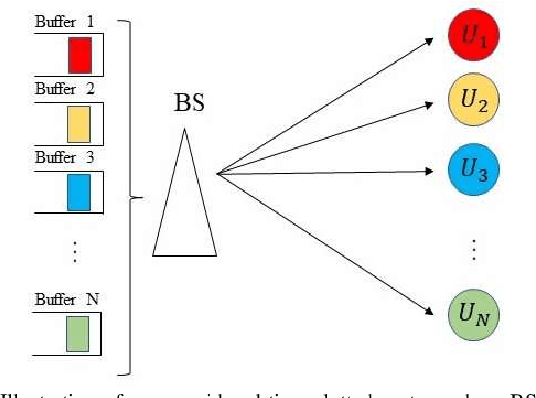
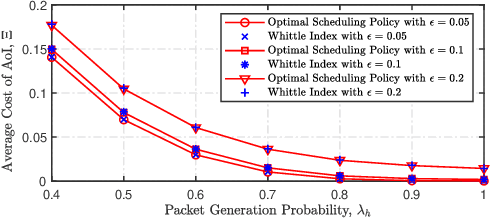
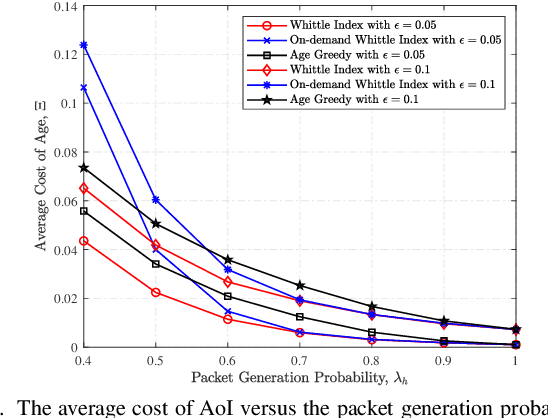
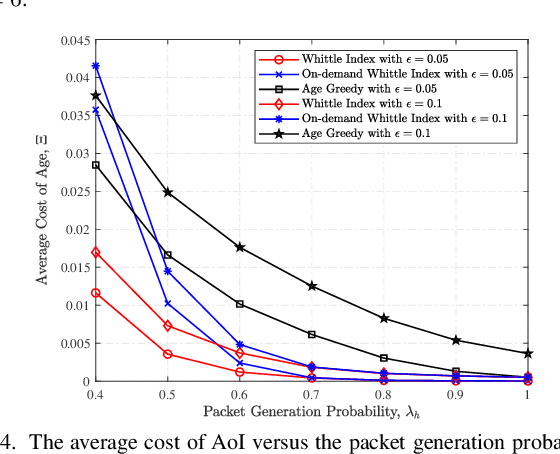
We design a new scheduling policy to minimize the general non-decreasing cost function of age of information (AoI) in a multiuser system. In this system, the base station stochastically generates time-sensitive packets and transmits them to corresponding user equipments via an unreliable channel. We first formulate the transmission scheduling problem as an average cost constrained Markov decision process problem. Through introducing the service charge, we derive the closed-form expression for the Whittle index, based on which we design the scheduling policy. Using numerical results, we demonstrate the performance gain of our designed scheduling policy compared to the existing policies, such as the optimal policy, the on-demand Whittle index policy, and the age greedy policy.
Dual MINE-based Neural Secure Communications under Gaussian Wiretap Channel
Feb 25, 2021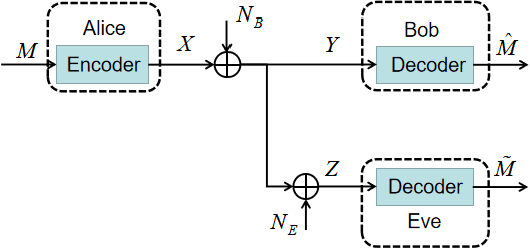
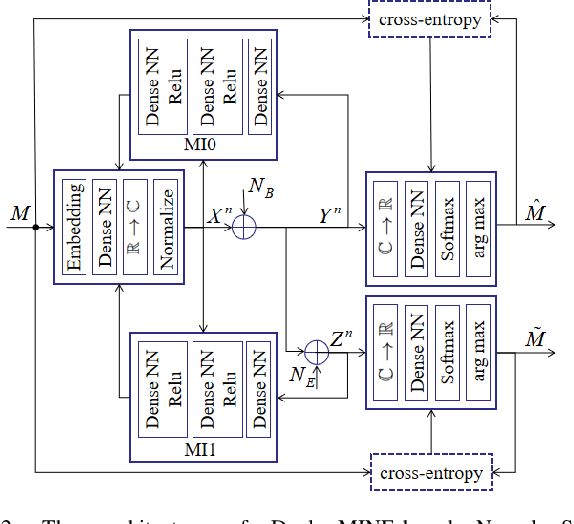
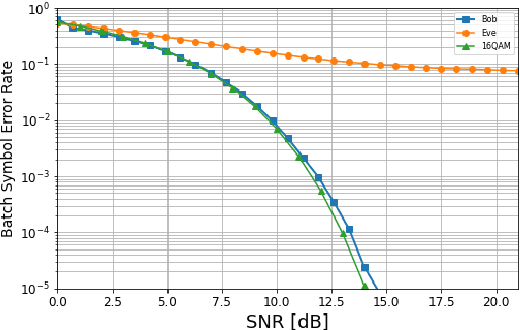
Recently, some researches are devoted to the topic of end-to-end learning a physical layer secure communication system based on autoencoder under Gaussian wiretap channel. However, in those works, the reliability and security of the encoder model were learned through necessary decoding outputs of not only legitimate receiver but also the eavesdropper. In fact, the assumption of known eavesdropper's decoder or its output is not practical. To address this issue, in this paper we propose a dual mutual information neural estimation (MINE) based neural secure communications model. The security constraints of this method is constructed only with the input and output signal samples of the legal and eavesdropper channels and benefit that training the encoder is completely independent of the decoder. Moreover, since the design of secure coding does not rely on the eavesdropper's decoding results, the security performance would not be affected by the eavesdropper's decoding means. Numerical results show that the performance of our model is guaranteed whether the eavesdropper learns the decoder himself or uses the legal decoder.
BSNet: Bi-Similarity Network for Few-shot Fine-grained Image Classification
Nov 29, 2020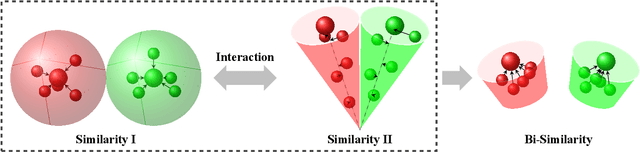
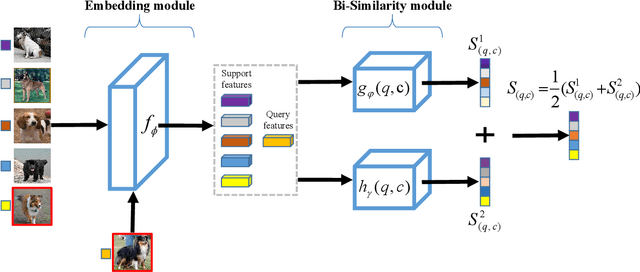
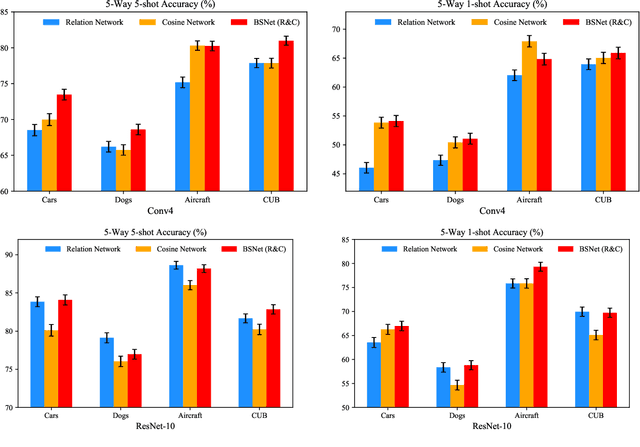
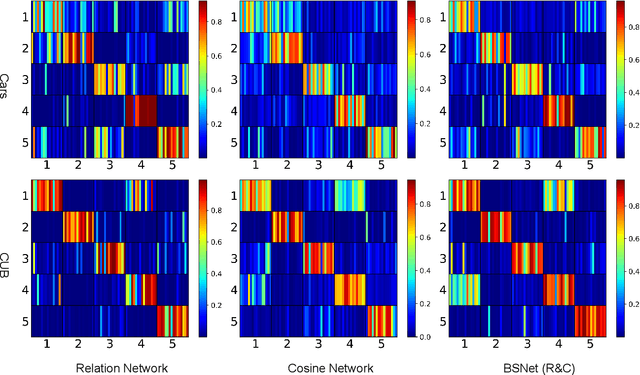
Few-shot learning for fine-grained image classification has gained recent attention in computer vision. Among the approaches for few-shot learning, due to the simplicity and effectiveness, metric-based methods are favorably state-of-the-art on many tasks. Most of the metric-based methods assume a single similarity measure and thus obtain a single feature space. However, if samples can simultaneously be well classified via two distinct similarity measures, the samples within a class can distribute more compactly in a smaller feature space, producing more discriminative feature maps. Motivated by this, we propose a so-called \textit{Bi-Similarity Network} (\textit{BSNet}) that consists of a single embedding module and a bi-similarity module of two similarity measures. After the support images and the query images pass through the convolution-based embedding module, the bi-similarity module learns feature maps according to two similarity measures of diverse characteristics. In this way, the model is enabled to learn more discriminative and less similarity-biased features from few shots of fine-grained images, such that the model generalization ability can be significantly improved. Through extensive experiments by slightly modifying established metric/similarity based networks, we show that the proposed approach produces a substantial improvement on several fine-grained image benchmark datasets. Codes are available at: https://github.com/spraise/BSNet
A Concise Review of Recent Few-shot Meta-learning Methods
May 22, 2020
Few-shot meta-learning has been recently reviving with expectations to mimic humanity's fast adaption to new concepts based on prior knowledge. In this short communication, we give a concise review on recent representative methods in few-shot meta-learning, which are categorized into four branches according to their technical characteristics. We conclude this review with some vital current challenges and future prospects in few-shot meta-learning.