 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning Control Variates: Variance Reduction with Limited Data
Paper and Code

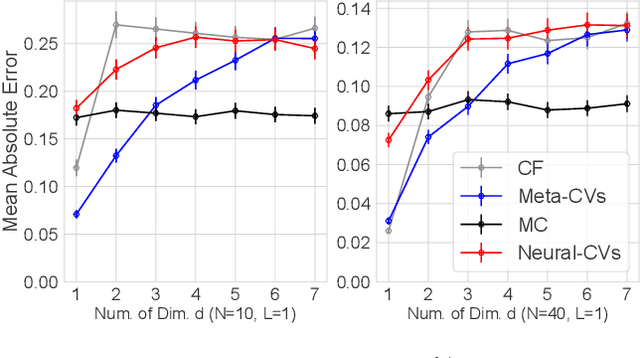
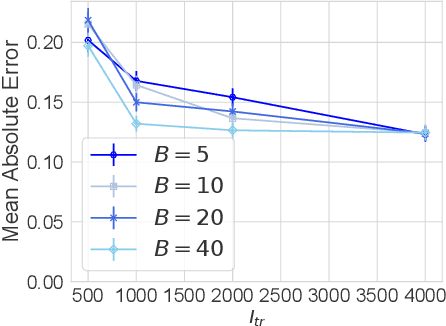
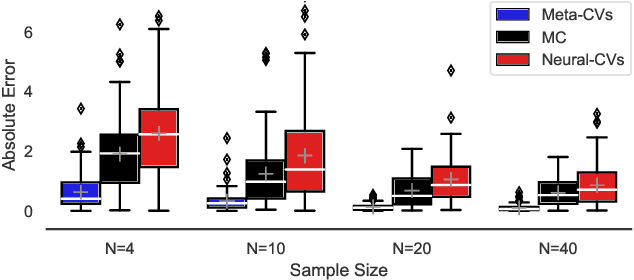
Control variates can be a powerful tool to reduce the variance of Monte Carlo estimators, but constructing effective control variates can be challenging when the number of samples is small. In this paper, we show that when a large number of related integrals need to be computed, it is possible to leverage the similarity between these integration tasks to improve performance even when the number of samples per task is very small. Our approach, called meta learning CVs (Meta-CVs), can be used for up to hundreds or thousands of tasks. Our empirical assessment indicates that Meta-CVs can lead to significant variance reduction in such settings, and our theoretical analysis establishes general conditions under which Meta-CVs can be successfully trained.