 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-directional Feature Reconstruction Network for Fine-Grained Few-Shot Image Classification
Nov 30, 2022



The main challenge for fine-grained few-shot image classification is to learn feature representations with higher inter-class and lower intra-class variations, with a mere few labelled samples. Conventional few-shot learning methods however cannot be naively adopted for this fine-grained setting -- a quick pilot study reveals that they in fact push for the opposite (i.e., lower inter-class variations and higher intra-class variations). To alleviate this problem, prior works predominately use a support set to reconstruct the query image and then utilize metric learning to determine its category. Upon careful inspection, we further reveal that such unidirectional reconstruction methods only help to increase inter-class variations and are not effective in tackling intra-class variations. In this paper, we for the first time introduce a bi-reconstruction mechanism that can simultaneously accommodate for inter-class and intra-class variations. In addition to using the support set to reconstruct the query set for increasing inter-class variations, we further use the query set to reconstruct the support set for reducing intra-class variations. This design effectively helps the model to explore more subtle and discriminative features which is key for the fine-grained problem in hand. Furthermore, we also construct a self-reconstruction module to work alongside the bi-directional module to make the features even more discriminative. Experimental results on three widely used fine-grained image classification datasets consistently show considerable improvements compared with other methods. Codes are available at: https://github.com/PRIS-CV/Bi-FRN.
Deep Metric Learning for Few-Shot Image Classification: A Selective Review
May 17, 2021
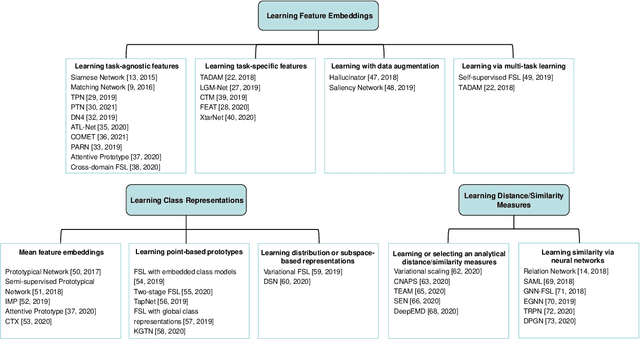
Few-shot image classification is a challenging problem which aims to achieve the human level of recognition based only on a small number of images. Deep learning algorithms such as meta-learning, transfer learning, and metric learning have been employed recently and achieved the state-of-the-art performance. In this survey, we review representative deep metric learning methods for few-shot classification, and categorize them into three groups according to the major problems and novelties they focus on. We conclude this review with a discussion on current challenges and future trends in few-shot image classification.
ATRM: Attention-based Task-level Relation Module for GNN-based Few-shot Learning
Jan 25, 2021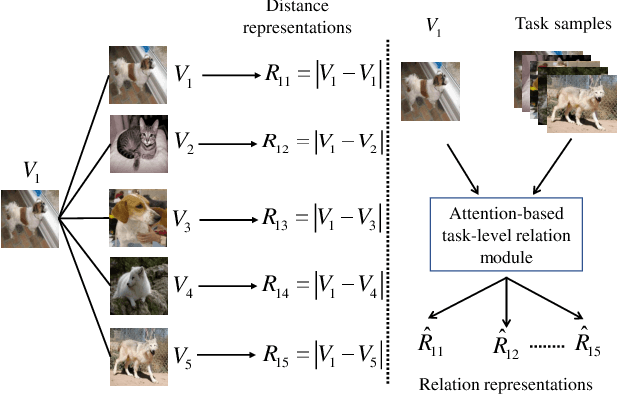
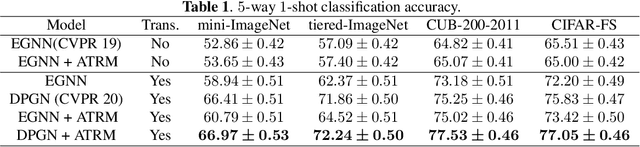
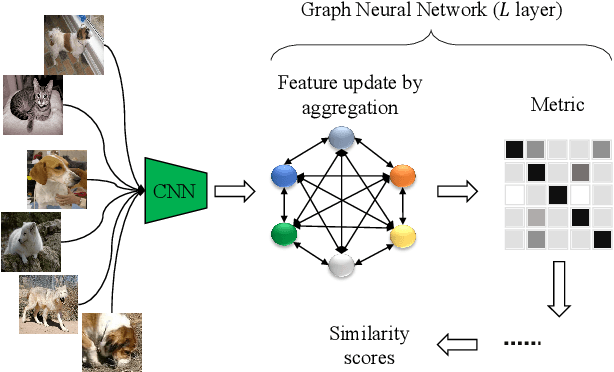
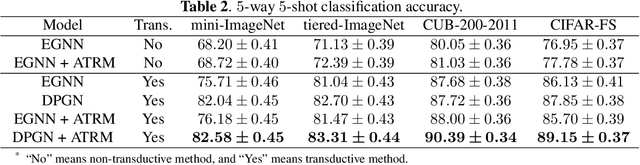
Recently, graph neural networks (GNNs) have shown powerful ability to handle few-shot classification problem, which aims at classifying unseen samples when trained with limited labeled samples per class. GNN-based few-shot learning architectures mostly replace traditional metric with a learnable GNN. In the GNN, the nodes are set as the samples embedding, and the relationship between two connected nodes can be obtained by a network, the input of which is the difference of their embedding features. We consider this method of measuring relation of samples only models the sample-to-sample relation, while neglects the specificity of different tasks. That is, this method of measuring relation does not take the task-level information into account. To this end, we propose a new relation measure method, namely the attention-based task-level relation module (ATRM), to explicitly model the task-level relation of one sample to all the others. The proposed module captures the relation representations between nodes by considering the sample-to-task instead of sample-to-sample embedding features. We conducted extensive experiments on four benchmark datasets: mini-ImageNet, tiered-ImageNet, CUB-200-2011, and CIFAR-FS. Experimental results demonstrate that the proposed module is effective for GNN-based few-shot learning.
BSNet: Bi-Similarity Network for Few-shot Fine-grained Image Classification
Nov 29, 2020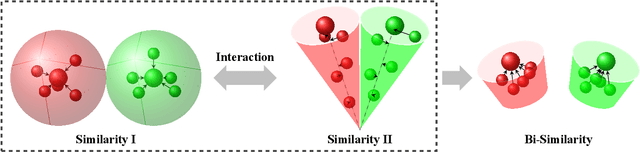
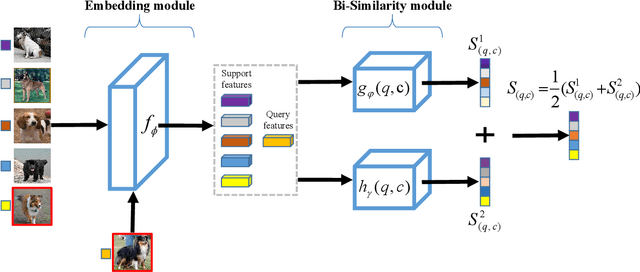
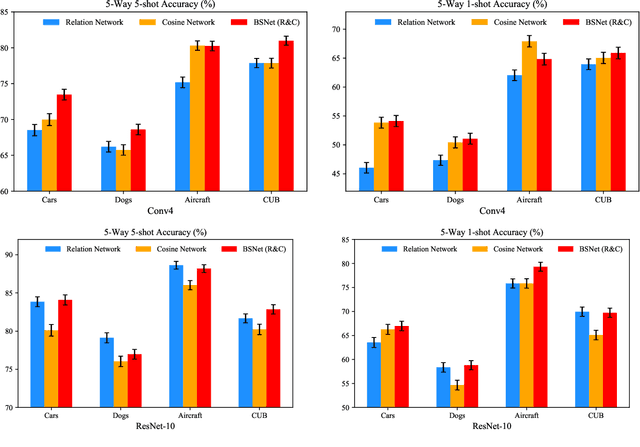
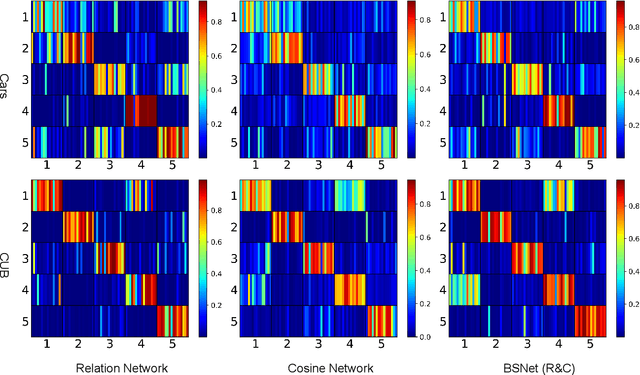
Few-shot learning for fine-grained image classification has gained recent attention in computer vision. Among the approaches for few-shot learning, due to the simplicity and effectiveness, metric-based methods are favorably state-of-the-art on many tasks. Most of the metric-based methods assume a single similarity measure and thus obtain a single feature space. However, if samples can simultaneously be well classified via two distinct similarity measures, the samples within a class can distribute more compactly in a smaller feature space, producing more discriminative feature maps. Motivated by this, we propose a so-called \textit{Bi-Similarity Network} (\textit{BSNet}) that consists of a single embedding module and a bi-similarity module of two similarity measures. After the support images and the query images pass through the convolution-based embedding module, the bi-similarity module learns feature maps according to two similarity measures of diverse characteristics. In this way, the model is enabled to learn more discriminative and less similarity-biased features from few shots of fine-grained images, such that the model generalization ability can be significantly improved. Through extensive experiments by slightly modifying established metric/similarity based networks, we show that the proposed approach produces a substantial improvement on several fine-grained image benchmark datasets. Codes are available at: https://github.com/spraise/BSNet
CC-Loss: Channel Correlation Loss For Image Classification
Oct 12, 2020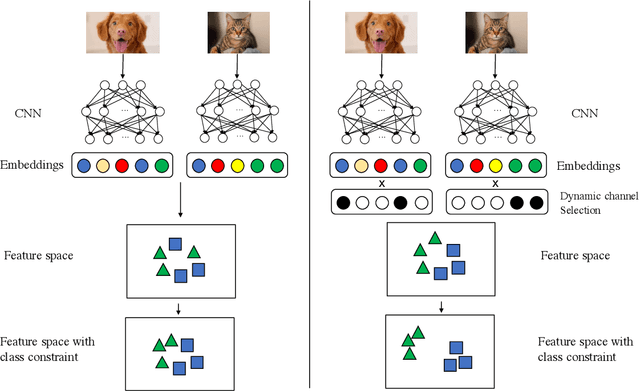

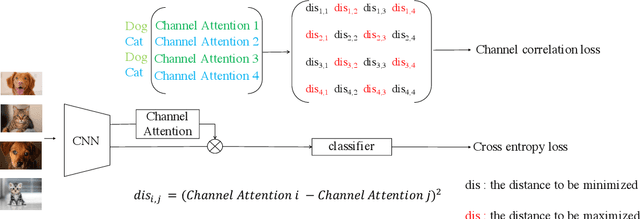
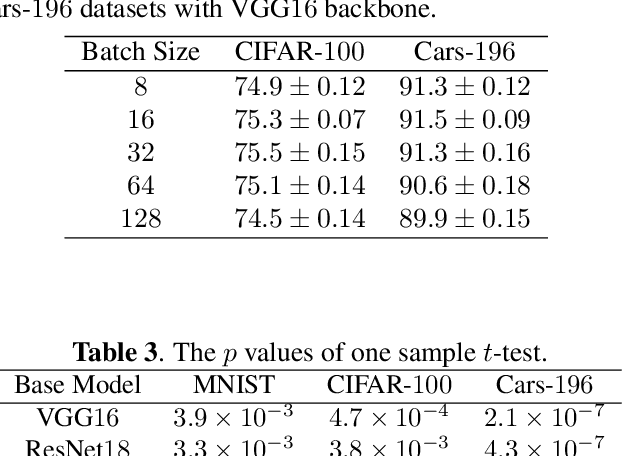
The loss function is a key component in deep learning models. A commonly used loss function for classification is the cross entropy loss, which is a simple yet effective application of information theory for classification problems. Based on this loss, many other loss functions have been proposed,~\emph{e.g.}, by adding intra-class and inter-class constraints to enhance the discriminative ability of the learned features. However, these loss functions fail to consider the connections between the feature distribution and the model structure. Aiming at addressing this problem, we propose a channel correlation loss (CC-Loss) that is able to constrain the specific relations between classes and channels as well as maintain the intra-class and the inter-class separability. CC-Loss uses a channel attention module to generate channel attention of features for each sample in the training stage. Next, an Euclidean distance matrix is calculated to make the channel attention vectors associated with the same class become identical and to increase the difference between different classes. Finally, we obtain a feature embedding with good intra-class compactness and inter-class separability.Experimental results show that two different backbone models trained with the proposed CC-Loss outperform the state-of-the-art loss functions on three image classification datasets.
ReMarNet: Conjoint Relation and Margin Learning for Small-Sample Image Classification
Jun 27, 2020
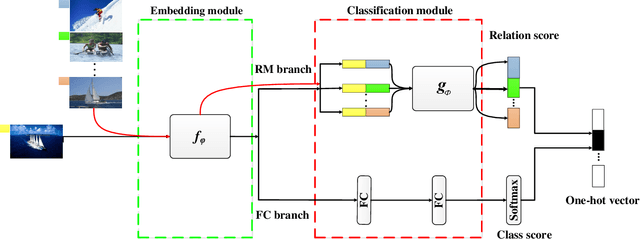
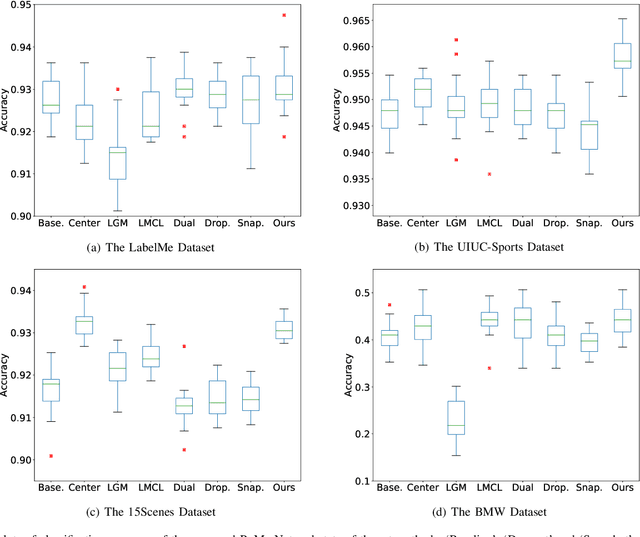
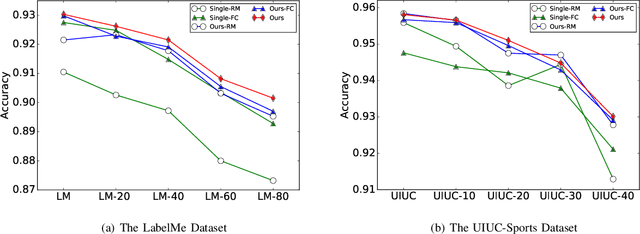
Despite achieving state-of-the-art performance, deep learning methods generally require a large amount of labeled data during training and may suffer from overfitting when the sample size is small. To ensure good generalizability of deep networks under small sample sizes, learning discriminative features is crucial. To this end, several loss functions have been proposed to encourage large intra-class compactness and inter-class separability. In this paper, we propose to enhance the discriminative power of features from a new perspective by introducing a novel neural network termed Relation-and-Margin learning Network (ReMarNet). Our method assembles two networks of different backbones so as to learn the features that can perform excellently in both of the aforementioned two classification mechanisms. Specifically, a relation network is used to learn the features that can support classification based on the similarity between a sample and a class prototype; at the meantime, a fully connected network with the cross entropy loss is used for classification via the decision boundary. Experiments on four image datasets demonstrate that our approach is effective in learning discriminative features from a small set of labeled samples and achieves competitive performance against state-of-the-art methods. Codes are available at https://github.com/liyunyu08/ReMarNet.
A Concise Review of Recent Few-shot Meta-learning Methods
May 22, 2020
Few-shot meta-learning has been recently reviving with expectations to mimic humanity's fast adaption to new concepts based on prior knowledge. In this short communication, we give a concise review on recent representative methods in few-shot meta-learning, which are categorized into four branches according to their technical characteristics. We conclude this review with some vital current challenges and future prospects in few-shot meta-learning.
OSLNet: Deep Small-Sample Classification with an Orthogonal Softmax Layer
Apr 20, 2020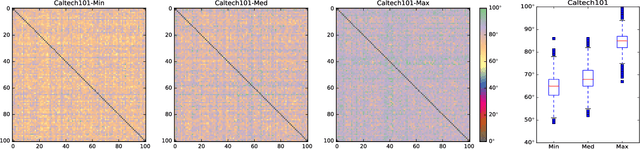

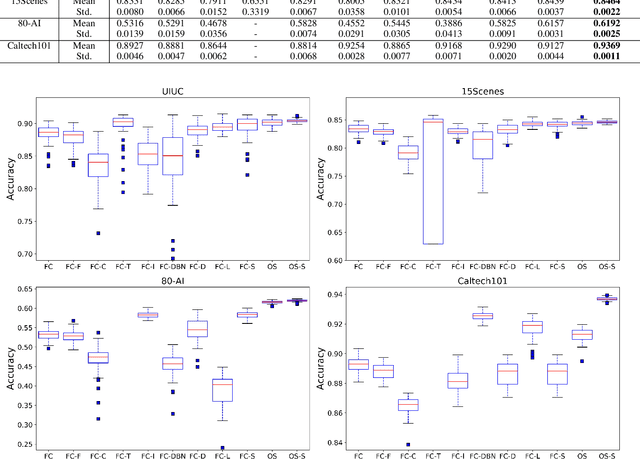

A deep neural network of multiple nonlinear layers forms a large function space, which can easily lead to overfitting when it encounters small-sample data. To mitigate overfitting in small-sample classification, learning more discriminative features from small-sample data is becoming a new trend. To this end, this paper aims to find a subspace of neural networks that can facilitate a large decision margin. Specifically, we propose the Orthogonal Softmax Layer (OSL), which makes the weight vectors in the classification layer remain orthogonal during both the training and test processes. The Rademacher complexity of a network using the OSL is only $\frac{1}{K}$, where $K$ is the number of classes, of that of a network using the fully connected classification layer, leading to a tighter generalization error bound. Experimental results demonstrate that the proposed OSL has better performance than the methods used for comparison on four small-sample benchmark datasets, as well as its applicability to large-sample datasets. Codes are available at: https://github.com/dongliangchang/OSLNet.
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification
Feb 11, 2020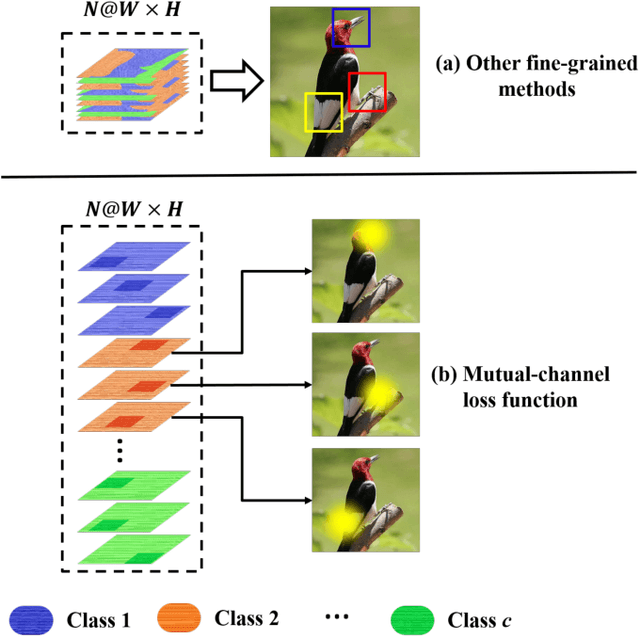



Key for solving fine-grained image categorization is finding discriminate and local regions that correspond to subtle visual traits. Great strides have been made, with complex networks designed specifically to learn part-level discriminate feature representations. In this paper, we show it is possible to cultivate subtle details without the need for overly complicated network designs or training mechanisms -- a single loss is all it takes. The main trick lies with how we delve into individual feature channels early on, as opposed to the convention of starting from a consolidated feature map. The proposed loss function, termed as mutual-channel loss (MC-Loss), consists of two channel-specific components: a discriminality component and a diversity component. The discriminality component forces all feature channels belonging to the same class to be discriminative, through a novel channel-wise attention mechanism. The diversity component additionally constraints channels so that they become mutually exclusive on spatial-wise. The end result is therefore a set of feature channels that each reflects different locally discriminative regions for a specific class. The MC-Loss can be trained end-to-end, without the need for any bounding-box/part annotations, and yields highly discriminative regions during inference. Experimental results show our MC-Loss when implemented on top of common base networks can achieve state-of-the-art performance on all four fine-grained categorization datasets (CUB-Birds, FGVC-Aircraft, Flowers-102, and Stanford-Cars). Ablative studies further demonstrate the superiority of MC-Loss when compared with other recently proposed general-purpose losses for visual classification, on two different base networks. Code available at https://github.com/dongliangchang/Mutual-Channel-Loss
Channel Max Pooling Layer for Fine-Grained Vehicle Classification
Feb 14, 2019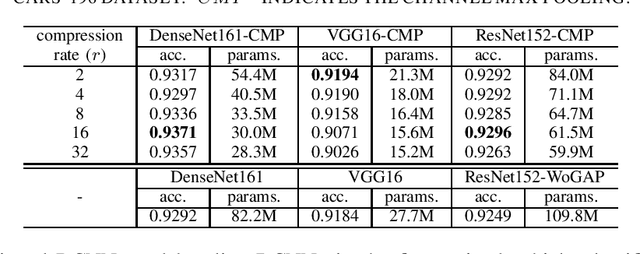

Deep convolutional networks have recently shown excellent performance on Fine-Grained Vehicle Classification. Based on these existing works, we consider that the back-probation algorithm does not focus on extracting less discriminative feature as much as possible, but focus on that the loss function equals zero. Intuitively, if we can learn less discriminative features, and these features still could fit the training data well, the generalization ability of neural network could be improved. Therefore, we propose a new layer which is placed between fully connected layers and convolutional layers, called as Chanel Max Pooling. The proposed layer groups the features map first and then compress each group into a new feature map by computing maximum of pixels with same positions in the group of feature maps. Meanwhile, the proposed layer has an advantage that it could help neural network reduce massive parameters. Experimental results on two fine-grained vehicle datasets, the Stanford Cars-196 dataset and the Comp Cars dataset, demonstrate that the proposed layer could improve classification accuracies of deep neural networks on fine-grained vehicle classification in the situation that a massive of parameters are reduced. Moreover, it has a competitive performance with the-state-of-art performance on the two datasets.