 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization in Topology Optimization via Sensitivity-Conditioned Bernoulli Flow Matching
Jun 01, 2026Surrogate models for topology optimization (TO) exhibit highly variable out-of-distribution (OOD) generalization under distribution shifts such as changing loads or boundary conditions, yet the source of this variability remains unclear. We hypothesize that OOD performance is governed by how much information the conditioning signal preserves about the adjoint sensitivity (reduced gradient) that drives classical TO. Modeling the TO pipeline as a causal Markov chain, the Data Processing Inequality establishes that, under this abstraction, the sensitivity field is an information-theoretically optimal conditioning signal for topology prediction. However, computing exact adjoint sensitivities can be expensive or unavailable in practice; we observe that certain physical fields can approximate sensitivities through monotone transformations. To formalize this, we introduce \textbf{pseudo-sensitivities} to characterize which fields enable generalization versus those that are information-poor. We then show that a sensitivity-conditioned Bernoulli flow-matching generator empirically confirms these predictions: conditioning on sensitivities yields state-of-the-art OOD performance, while increasingly distant physical fields degrade toward raw parameter conditioning. Results hold across structural TO benchmarks under load shifts and our new CFD-TO dataset under boundary-condition shifts such as multi-outlet configurations. Code and datasets are available at https://tum-pbs.github.io/topotransformer/ .
CRAFT: Conflict-Resolved Aggregation for Federated Training
May 20, 2026The aggregation of conflicting client updates remains a fundamental bottleneck in federated learning (FL) under heterogeneous data distributions. Naive averaging can produce a global update that improves the global objective while conflicting with specific clients, causing degradation for those clients. In this work, we propose CRAFT (Conflict-Resolved Aggregation for Federated Training), a new aggregation framework that treats the global update as a geometric correction problem. We formulate aggregation as finding the update closest to a reference direction while satisfying conflict-free alignment constraints. We derive a closed-form expression for the constrained optimization problem, avoiding the computational overhead of iterative solvers. Furthermore, we use a layer-wise adaptation to address conflicts at varying feature granularities. We provide a theoretical analysis showing that CRAFT promotes a common-descent structure and mitigates conflicts through its projection geometry. Extensive experiments on heterogeneous benchmarks demonstrate that CRAFT improves the accuracy of the global model while reducing performance disparity across clients compared with state-of-the-art baselines. The source code for CRAFT is available at https://github.com/tum-pbs/CRAFT.
A neural operator framework for data-driven discovery of stability and receptivity in physical systems
Apr 21, 2026Understanding how complex systems respond to perturbations, such as whether they will remain stable or what their most sensitive patterns are, is a fundamental challenge across science and engineering. Traditional stability and receptivity (resolvent) analyses are powerful but rely on known equations and linearization, limiting their use in nonlinear or poorly modeled systems. Here, we introduce a data-driven framework that automatically identifies stability properties and optimal forcing responses from observation data alone, without requiring governing equations. By training a neural network as a dynamics emulator and using automatic differentiation to extract its Jacobian, we can compute eigenmodes and resolvent modes directly from data. We demonstrate the method on both canonical chaotic models and high-dimensional fluid flows, successfully identifying dominant instability modes and input-output structures even in strongly nonlinear regimes. By leveraging a neural network-based emulator, we readily obtain a nonlinear representation of system dynamics while additionally retrieving intricate dynamical patterns that were previously difficult to resolve. This equation-free methodology establishes a broadly applicable tool for analyzing complex, high-dimensional datasets, with immediate relevance to grand challenges in fields such as climate science, neuroscience, and fluid engineering.
Towards a Foundation-Model Paradigm for Aerodynamic Prediction in Three-dimensional Design
Apr 20, 2026Accurate machine-learning models for aerodynamic prediction are essential for accelerating shape optimization, yet remain challenging to develop for complex three-dimensional configurations due to the high cost of generating training data. This work introduces a methodology for efficiently constructing accurate surrogate models for design purposes by first pre-training a large-scale model on diverse geometries and then fine-tuning it with a few more detailed task-specific samples. A Transformer-based architecture, AeroTransformer, is developed and tailored for large-scale training to learn aerodynamics. The methodology is evaluated on transonic wings, where the model is pre-trained on SuperWing, a dataset of nearly 30000 samples with broad geometric diversity, and subsequently fine-tuned to handle specific wing shapes perturbed from the Common Research Model. Results show that, with 450 task-specific samples, the proposed methodology achieves 0.36% error on surface-flow prediction, reducing 84.2% compared to training from scratch. The influence of model configurations and training strategies is also systematically studied to provide guidance on effectively training and deploying such models under limited data and computational budgets. To facilitate reuse, we release the datasets and the pre-trained models at https://github.com/tum-pbs/AeroTransformer. An interactive design tool is also built on the pre-trained model and is available online at https://webwing.pbs.cit.tum.de.
One Scale at a Time: Scale-Autoregressive Modeling for Fluid Flow Distributions
Apr 13, 2026Analyzing unsteady fluid flows often requires access to the full distribution of possible temporal states, yet conventional PDE solvers are computationally prohibitive and learned time-stepping surrogates quickly accumulate error over long rollouts. Generative models avoid compounding error by sampling states independently, but diffusion and flow-matching methods, while accurate, are limited by the cost of many evaluations over the entire mesh. We introduce scale-autoregressive modeling (SAR) for sampling flows on unstructured meshes hierarchically from coarse to fine: it first generates a low-resolution field, then refines it by progressively sampling higher resolutions conditioned on coarser predictions. This coarse-to-fine factorization improves efficiency by concentrating computation at coarser scales, where uncertainty is greatest, while requiring fewer steps at finer scales. Across unsteady-flow benchmarks of varying complexity, SAR attains substantially lower distributional error and higher per-sample accuracy than state-of-the-art diffusion models based on multi-scale GNNs, while matching or surpassing a flow-matching Transolver (a linear-time transformer) yet running 2-7x faster than this depending on the task. Overall, SAR provides a practical tool for fast and accurate estimation of statistical flow quantities (e.g., turbulent kinetic energy and two-point correlations) in real-world settings.
Physics-Constrained Adaptive Flow Matching for Climate Downscaling
Apr 03, 2026Regional climate information at kilometer scales is essential for assessing the impacts of climate change, but generating it with global climate models is too expensive due to their high computational costs. Machine learning models offer a fast alternative, yet they often violate basic physical laws and degrade when applied to climates outside of their training distribution. We present Physics-Constrained Adaptive Flow Matching (PC-AFM), a generative downscaling model that addresses both problems. Building on the Adaptive Flow Matching (AFM) model of Fotiadis et al. (2025) as our baseline, we add soft conservation constraints that keep the downscaled output consistent with the large-scale input for precipitation and humidity, and use gradient surgery via the ConFIG algorithm to prevent these constraints from interfering with the generative objective. We train the model on Central Europe climate data, evaluate it on a 10-time downscaling task (63km to 6.3km) over six variables (near-surface temperature, precipitation, specific humidity, surface pressure, and horizontal wind components) across a comprehensive set of metrics including bias, ensemble skill scores, power spectra, and conservation error, and test the generalization on two held-out climate regions. Within the training distribution, PC-AFM reduces conservation errors and improves ensemble calibration while matching the baseline on standard skill metrics. Outside the training distribution, where unconstrained models develop large systematic errors by extrapolating learned statistics, PC-AFM halves precipitation wet bias, reduces conservation error and improves extreme-quantile accuracy, all without any information about the target climate at inference time. These results indicate that physical consistency is a practical requirement for deploying generative downscaling models in real-world applications.
Plug-and-Play Benchmarking of Reinforcement Learning Algorithms for Large-Scale Flow Control
Jan 21, 2026Reinforcement learning (RL) has shown promising results in active flow control (AFC), yet progress in the field remains difficult to assess as existing studies rely on heterogeneous observation and actuation schemes, numerical setups, and evaluation protocols. Current AFC benchmarks attempt to address these issues but heavily rely on external computational fluid dynamics (CFD) solvers, are not fully differentiable, and provide limited 3D and multi-agent support. To overcome these limitations, we introduce FluidGym, the first standalone, fully differentiable benchmark suite for RL in AFC. Built entirely in PyTorch on top of the GPU-accelerated PICT solver, FluidGym runs in a single Python stack, requires no external CFD software, and provides standardized evaluation protocols. We present baseline results with PPO and SAC and release all environments, datasets, and trained models as public resources. FluidGym enables systematic comparison of control methods, establishes a scalable foundation for future research in learning-based flow control, and is available at https://github.com/safe-autonomous-systems/fluidgym.
SuperWing: a comprehensive transonic wing dataset for data-driven aerodynamic design
Dec 16, 2025Machine-learning surrogate models have shown promise in accelerating aerodynamic design, yet progress toward generalizable predictors for three-dimensional wings has been limited by the scarcity and restricted diversity of existing datasets. Here, we present SuperWing, a comprehensive open dataset of transonic swept-wing aerodynamics comprising 4,239 parameterized wing geometries and 28,856 Reynolds-averaged Navier-Stokes flow field solutions. The wing shapes in the dataset are generated using a simplified yet expressive geometry parameterization that incorporates spanwise variations in airfoil shape, twist, and dihedral, allowing for an enhanced diversity without relying on perturbations of a baseline wing. All shapes are simulated under a broad range of Mach numbers and angles of attack covering the typical flight envelope. To demonstrate the dataset's utility, we benchmark two state-of-the-art Transformers that accurately predict surface flow and achieve a 2.5 drag-count error on held-out samples. Models pretrained on SuperWing further exhibit strong zero-shot generalization to complex benchmark wings such as DLR-F6 and NASA CRM, underscoring the dataset's diversity and potential for practical usage.
INC: An Indirect Neural Corrector for Auto-Regressive Hybrid PDE Solvers
Nov 18, 2025

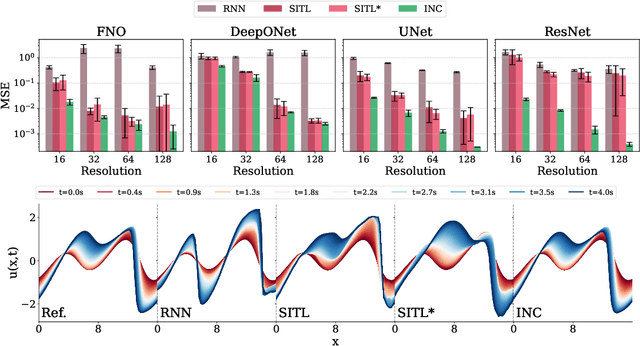

When simulating partial differential equations, hybrid solvers combine coarse numerical solvers with learned correctors. They promise accelerated simulations while adhering to physical constraints. However, as shown in our theoretical framework, directly applying learned corrections to solver outputs leads to significant autoregressive errors, which originate from amplified perturbations that accumulate during long-term rollouts, especially in chaotic regimes. To overcome this, we propose the Indirect Neural Corrector ($\mathrm{INC}$), which integrates learned corrections into the governing equations rather than applying direct state updates. Our key insight is that $\mathrm{INC}$ reduces the error amplification on the order of $Δt^{-1} + L$, where $Δt$ is the timestep and $L$ the Lipschitz constant. At the same time, our framework poses no architectural requirements and integrates seamlessly with arbitrary neural networks and solvers. We test $\mathrm{INC}$ in extensive benchmarks, covering numerous differentiable solvers, neural backbones, and test cases ranging from a 1D chaotic system to 3D turbulence. $\mathrm{INC}$ improves the long-term trajectory performance ($R^2$) by up to 158.7%, stabilizes blowups under aggressive coarsening, and for complex 3D turbulence cases yields speed-ups of several orders of magnitude. $\mathrm{INC}$ thus enables stable, efficient PDE emulation with formal error reduction, paving the way for faster scientific and engineering simulations with reliable physics guarantees. Our source code is available at https://github.com/tum-pbs/INC
Neural Emulator Superiority: When Machine Learning for PDEs Surpasses its Training Data
Oct 27, 2025Neural operators or emulators for PDEs trained on data from numerical solvers are conventionally assumed to be limited by their training data's fidelity. We challenge this assumption by identifying "emulator superiority," where neural networks trained purely on low-fidelity solver data can achieve higher accuracy than those solvers when evaluated against a higher-fidelity reference. Our theoretical analysis reveals how the interplay between emulator inductive biases, training objectives, and numerical error characteristics enables superior performance during multi-step rollouts. We empirically validate this finding across different PDEs using standard neural architectures, demonstrating that emulators can implicitly learn dynamics that are more regularized or exhibit more favorable error accumulation properties than their training data, potentially surpassing training data limitations and mitigating numerical artifacts. This work prompts a re-evaluation of emulator benchmarking, suggesting neural emulators might achieve greater physical fidelity than their training source within specific operational regimes. Project Page: https://tum-pbs.github.io/emulator-superiority