 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness is Not Silence: Unmasking Vacuous Neutrality in Small Language Models
Jun 10, 2025The rapid adoption of Small Language Models (SLMs) for on-device and resource-constrained deployments has outpaced our understanding of their ethical risks. To the best of our knowledge, we present the first large-scale audit of instruction-tuned SLMs spanning 0.5 to 5 billion parameters-an overlooked "middle tier" between BERT-class encoders and flagship LLMs. Our evaluation includes nine open-source models from the Qwen 2.5, LLaMA 3.2, Gemma 3, and Phi families. Using the BBQ benchmark under zero-shot prompting, we analyze both utility and fairness across ambiguous and disambiguated contexts. This evaluation reveals three key insights. First, competence and fairness need not be antagonistic: Phi models achieve F1 scores exceeding 90 percent while exhibiting minimal bias, showing that efficient and ethical NLP is attainable. Second, social bias varies significantly by architecture: Qwen 2.5 models may appear fair, but this often reflects vacuous neutrality, random guessing, or evasive behavior rather than genuine ethical alignment. In contrast, LLaMA 3.2 models exhibit stronger stereotypical bias, suggesting overconfidence rather than neutrality. Third, compression introduces nuanced trade-offs: 4-bit AWQ quantization improves F1 scores in ambiguous settings for LLaMA 3.2-3B but increases disability-related bias in Phi-4-Mini by over 7 percentage points. These insights provide practical guidance for the responsible deployment of SLMs in applications demanding fairness and efficiency, particularly benefiting small enterprises and resource-constrained environments.
PESTO: Switching Point based Dynamic and Relative Positional Encoding for Code-Mixed Languages
Nov 12, 2021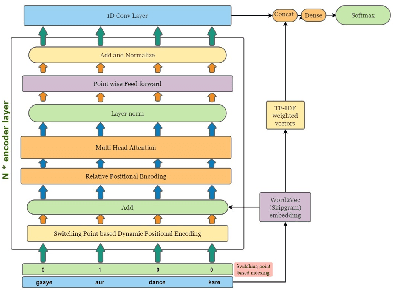
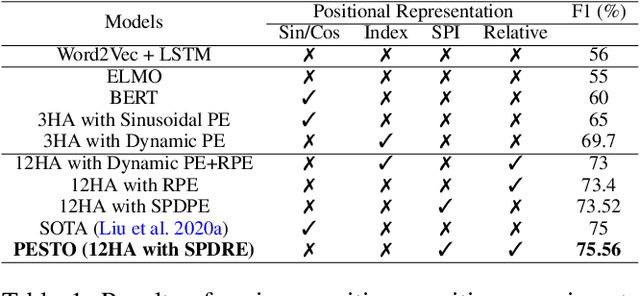
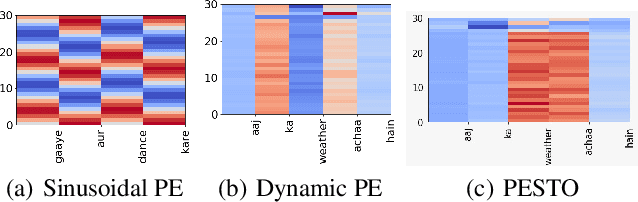
NLP applications for code-mixed (CM) or mix-lingual text have gained a significant momentum recently, the main reason being the prevalence of language mixing in social media communications in multi-lingual societies like India, Mexico, Europe, parts of USA etc. Word embeddings are basic build-ing blocks of any NLP system today, yet, word embedding for CM languages is an unexplored territory. The major bottleneck for CM word embeddings is switching points, where the language switches. These locations lack in contextually and statistical systems fail to model this phenomena due to high variance in the seen examples. In this paper we present our initial observations on applying switching point based positional encoding techniques for CM language, specifically Hinglish (Hindi - English). Results are only marginally better than SOTA, but it is evident that positional encoding could bean effective way to train position sensitive language models for CM text.