 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6D Object Pose Estimation from Approximate 3D Models for Orbital Robotics
Mar 31, 2023



We present a novel technique to estimate the 6D pose of objects from single images where the 3D geometry of the object is only given approximately and not as a precise 3D model. To achieve this, we employ a dense 2D-to-3D correspondence predictor that regresses 3D model coordinates for every pixel. In addition to the 3D coordinates, our model also estimates the pixel-wise coordinate error to discard correspondences that are likely wrong. This allows us to generate multiple 6D pose hypotheses of the object, which we then refine iteratively using a highly efficient region-based approach. We also introduce a novel pixel-wise posterior formulation by which we can estimate the probability for each hypothesis and select the most likely one. As we show in experiments, our approach is capable of dealing with extreme visual conditions including overexposure, high contrast, or low signal-to-noise ratio. This makes it a powerful technique for the particularly challenging task of estimating the pose of tumbling satellites for in-orbit robotic applications. Our method achieves state-of-the-art performance on the SPEED+ dataset and has won the SPEC2021 post-mortem competition.
Fusing Visual Appearance and Geometry for Multi-modality 6DoF Object Tracking
Feb 22, 2023



In many applications of advanced robotic manipulation, six degrees of freedom (6DoF) object pose estimates are continuously required. In this work, we develop a multi-modality tracker that fuses information from visual appearance and geometry to estimate object poses. The algorithm extends our previous method ICG, which uses geometry, to additionally consider surface appearance. In general, object surfaces contain local characteristics from text, graphics, and patterns, as well as global differences from distinct materials and colors. To incorporate this visual information, two modalities are developed. For local characteristics, keypoint features are used to minimize distances between points from keyframes and the current image. For global differences, a novel region approach is developed that considers multiple regions on the object surface. In addition, it allows the modeling of external geometries. Experiments on the YCB-Video and OPT datasets demonstrate that our approach ICG+ performs best on both datasets, outperforming both conventional and deep learning-based methods. At the same time, the algorithm is highly efficient and runs at more than 300 Hz. The source code of our tracker is publicly available.
A Multi-body Tracking Framework -- From Rigid Objects to Kinematic Structures
Aug 02, 2022
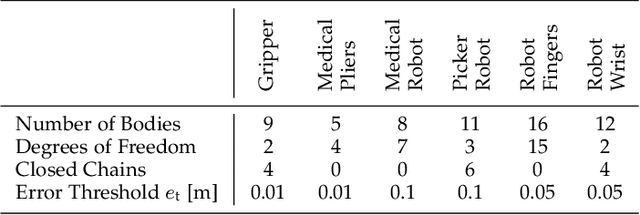
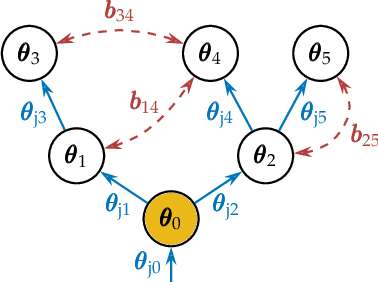
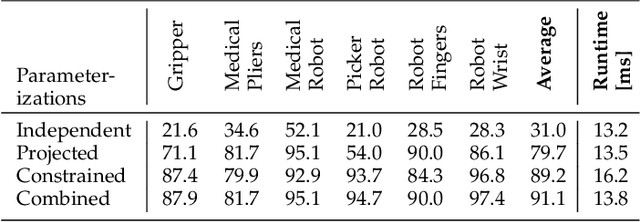
Kinematic structures are very common in the real world. They range from simple articulated objects to complex mechanical systems. However, despite their relevance, most model-based 3D tracking methods only consider rigid objects. To overcome this limitation, we propose a flexible framework that allows the extension of existing 6DoF algorithms to kinematic structures. Our approach focuses on methods that employ Newton-like optimization techniques, which are widely used in object tracking. The framework considers both tree-like and closed kinematic structures and allows a flexible configuration of joints and constraints. To project equations from individual rigid bodies to a multi-body system, Jacobians are used. For closed kinematic chains, a novel formulation that features Lagrange multipliers is developed. In a detailed mathematical proof, we show that our constraint formulation leads to an exact kinematic solution and converges in a single iteration. Based on the proposed framework, we extend ICG, which is a state-of-the-art rigid object tracking algorithm, to multi-body tracking. For the evaluation, we create a highly-realistic synthetic dataset that features a large number of sequences and various robots. Based on this dataset, we conduct a wide variety of experiments that demonstrate the excellent performance of the developed framework and our multi-body tracker.
Iterative Corresponding Geometry: Fusing Region and Depth for Highly Efficient 3D Tracking of Textureless Objects
Mar 10, 2022
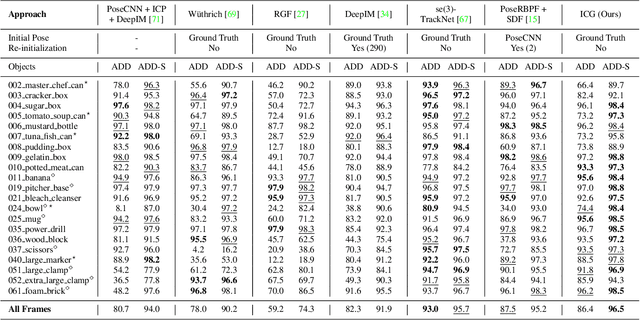
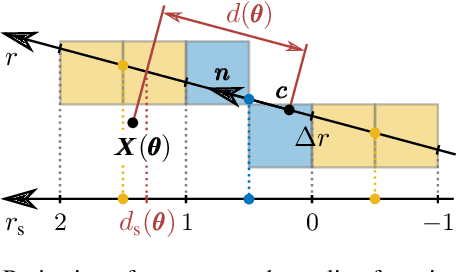
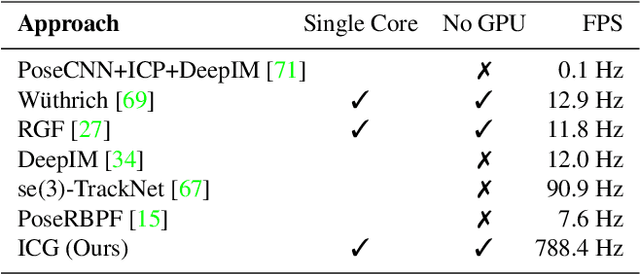
Tracking objects in 3D space and predicting their 6DoF pose is an essential task in computer vision. State-of-the-art approaches often rely on object texture to tackle this problem. However, while they achieve impressive results, many objects do not contain sufficient texture, violating the main underlying assumption. In the following, we thus propose ICG, a novel probabilistic tracker that fuses region and depth information and only requires the object geometry. Our method deploys correspondence lines and points to iteratively refine the pose. We also implement robust occlusion handling to improve performance in real-world settings. Experiments on the YCB-Video, OPT, and Choi datasets demonstrate that, even for textured objects, our approach outperforms the current state of the art with respect to accuracy and robustness. At the same time, ICG shows fast convergence and outstanding efficiency, requiring only 1.3 ms per frame on a single CPU core. Finally, we analyze the influence of individual components and discuss our performance compared to deep learning-based methods. The source code of our tracker is publicly available.
SRT3D: A Sparse Region-Based 3D Object Tracking Approach for the Real World
Oct 25, 2021

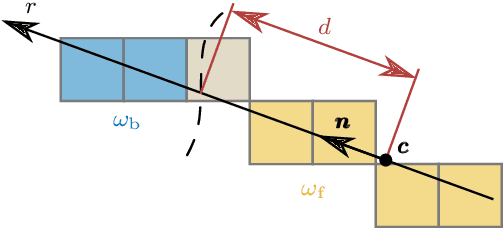
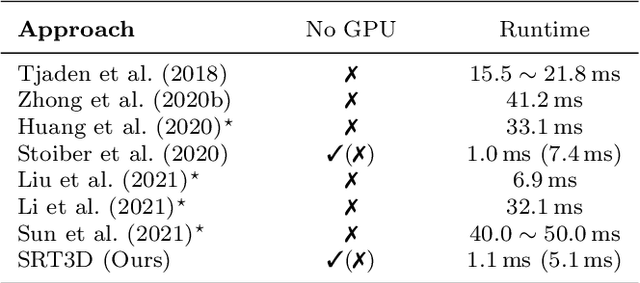
Region-based methods have become increasingly popular for model-based, monocular 3D tracking of texture-less objects in cluttered scenes. However, while they achieve state-of-the-art results, most methods are computationally expensive, requiring significant resources to run in real-time. In the following, we build on our previous work and develop SRT3D, a sparse region-based approach to 3D object tracking that bridges this gap in efficiency. Our method considers image information sparsely along so-called correspondence lines that model the probability of the object's contour location. We thereby improve on the current state of the art and introduce smoothed step functions that consider a defined global and local uncertainty. For the resulting probabilistic formulation, a thorough analysis is provided. Finally, we use a pre-rendered sparse viewpoint model to create a joint posterior probability for the object pose. The function is maximized using second-order Newton optimization with Tikhonov regularization. During the pose estimation, we differentiate between global and local optimization, using a novel approximation for the first-order derivative employed in the Newton method. In multiple experiments, we demonstrate that the resulting algorithm improves the current state of the art both in terms of runtime and quality, performing particularly well for noisy and cluttered images encountered in the real world.